1.简介
1.1定义
Elaticsearch ,简称为es,是一 个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
1.2核心概念
elasticsearch是面向文档的,和数据库的对比如下:
| Relational DB | Elasticsearch | Elasticsearch说明 |
| 数据库(database) | 索引(indices) | |
| 表(tables) | 类型(types) [在弃用] | |
| 行(rows) | 文档(documents) | 包含key:value,是一个json对象 |
| 字段(columns) | 字段(fields) |
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移,而索引和搜索数据的最小单位是文档。
2.下载和安装
本次在Linux上进行安装。
2.1下载
官网:https://www.elastic.co/cn/downloads/elasticsearch
网盘:链接:https://pan.baidu.com/s/1S9jovAYM98Q18zbT2h6uAQ 提取码:fnup
华为云的镜像:https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
2.2安装
1)把压缩包复制到Linux,解压
tar -zxvf /usr/backup/elasticsearch-7.8.0-linux-x86_64.tar.gz -C /usr/local
2)创建用户并给与权限
从5.0开始 elasticsearch 安全级别提高了 不允许采用root帐号启, 所以要添加一个用户用来启动。这里对解压后的文件名进行了重命名。
cd /usr/local mv elasticsearch-7.8.0-linux-x86_64 elasticsearch-7.8.0 useradd es chown -R es /usr/local/elasticsearch-7.8.0 cd elasticsearch-7.8.0
3)创建数据目录
cd /usr/local/elasticsearch-7.8.0 mkdir data
4)修改配置文件
vim config/elasticsearch.yml
然后把下面的注释删除并修改
cluster.name: my-application node.name: node-1 path.data: /usr/local/elasticsearch-7.8.0/data path.logs: /usr/local/elasticsearch-7.8.0/logs network.host: 0.0.0.0 http.port: 9200 cluster.initial_master_nodes: ["node-1"]
在文件最后再追加内容:
xpack.ml.enabled: false bootstrap.memory_lock: false bootstrap.system_call_filter: false
5)启动
启动之前要进入es用户
su es
bin/elasticsearch
看到下图显示的内容表示启动成功
![]()
6)测试
在本地浏览器输入http://192.168.159.128:9200/,看到下面返回的信息,说明安装成功
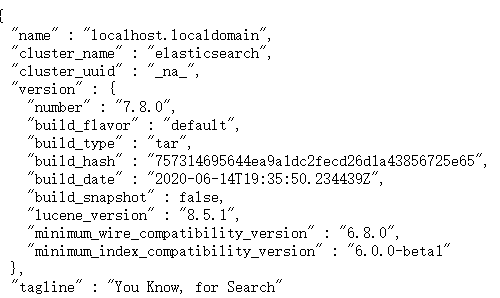
2.3安装遇到的问题
(1)unable to load JNA native support library, native methods will be disabled
原因:32位系统装了64位的elasticsearch,导致找不到JNA的jar包。
解决办法:下载32位的JNA的jar,删除原本elasticsearch/bin目录下的JNA的jar,把下载的JNA的jar复制进去即可。
网盘下载:链接:https://pan.baidu.com/s/1PYMEVlhxdif_g3ou2CMurw 提取码:eaae
(2)max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
原因:文件权限不足
解决办法:打开配置文件,在尾部追加内容。
vim /etc/security/limits.conf
追加的内容
* soft nofile 65536 * hard nofile 65536
(3)max number of threads [1024] for user [leyou] is too low, increase to at least [4096]
原因:线程数不够
解决办法:修改配置文件
vim /etc/security/limits.d/90-nproc.conf
把soft nproc 1024改为soft nproc 4096。
(4)max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
原因:进程虚拟内存数量不够
解决办法:修改配置文件
vim /etc/sysctl.conf
在尾部追加内容后保存
vm.max_map_count=655360
再执行命令:
sysctl -p
(5)JVM is using the client VM [Java HotSpot™ Client VM] but should be using a server VM for the best performance
原因:JVM正在使用客户机VM,但是为了获得最佳性能,应该使用服务器VM
解决办法:打开JAVA_HOME\jre\lib\i386\jvm.cfg,把下图的两行代码进行位置
cd /usr/local/java/jdk1.8.0/jre/lib/i386/jvm.cfg
换位置前:

换位置后:

2.4可视化界面安装
elasticsearch-head可以用来查看elasticsearch的相关信息,单独部署。这里就使用本地的内置的服务器运行,因此本机需要有nodeJs的环境。
1)下载
git clone https://github.com/mobz/elasticsearch-head.git
2)运行
cd elasticsearch-head
npm install
npm run start
在浏览器输入http://localhost:9100/ 进行访问,如下图:

3)解决跨域问题
当输入linux上的elasticsearch的访问地址时,head是无法进行连接的,原因就是涉及到了跨域。需要进行配置。
打开elasticsearch-7.8.0的配置文件,在尾部添加
vi config/elasticsearch.yml
#添加的内容
http.cors.enabled: true
http.cors.allow-origin: "*"
重启es后head就可以连接成功。
2.5Kibana安装
1)介绍
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索查看交互存储在Elasticsearch索 |中的数据。简单来说,就是用来操作Elasticsearch数据的。
2)下载
官网:https://www.elastic.co/cn/downloads/kibana
网盘:链接:https://pan.baidu.com/s/1qG_JHAM8Jw_OFXvZVc8wsA 提取码:3y9g
华为云镜像: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
3)安装
第一步:把下载的压缩包安装到Linux并解压
tar -zxvf /usr/backup/kibana-7.8.0-linux-x86_64.tar.gz -C /usr/local
第二步:修改配置文件
cd /usr/local mv kibana-7.8.0-linux-x86_64 kibana-7.8.0 cd kibana-7.8.0 vim config/kibana.yml
放开下面的注释并修改:
server.port: 5601 server.host: "0.0.0.0" #192.168.159.128是elasticsearch的服务器ip elasticsearch.url: "http://192.168.159.128:9200" kibana.index: ".kibana"
第三步:启动(必须以非root用户启动)
bin/kibana
出现下面的错误,不能正常启动。原因是kibana需要依赖node环境,因此需要先安装node。

node安装完成后,再次启动,发现启动成功。
第四步:测试。访问http://192.168.159.128:5601可以看到如下界面,说明安装成功。

第五步:页面改为汉化版。
vim config/kibana.yml
把i18n.locale: "en"改为i18n.locale: "zh-CN"即可,需要重启kibana。
2.6IK分析器安装
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引|库中的数据进行分词,然后进行一个匹配操作。
1)下载
需要注意的是,目前下载的elasticsearch和kibana以及Ik分词器的版本必须一致。后面如果再涉及到版本的也要保持一致。
github:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.8.0
网盘:链接:https://pan.baidu.com/s/19EfTBYFSi8SsUMjM9EuGIQ 提取码:vmpd
2)安装
把下载的压缩包解压后放到elasticsearch-7.8.0/plugins/目录里面即可。

3)测试
重启elasticsearch,在kibana的菜单栏找到开发工具并打开
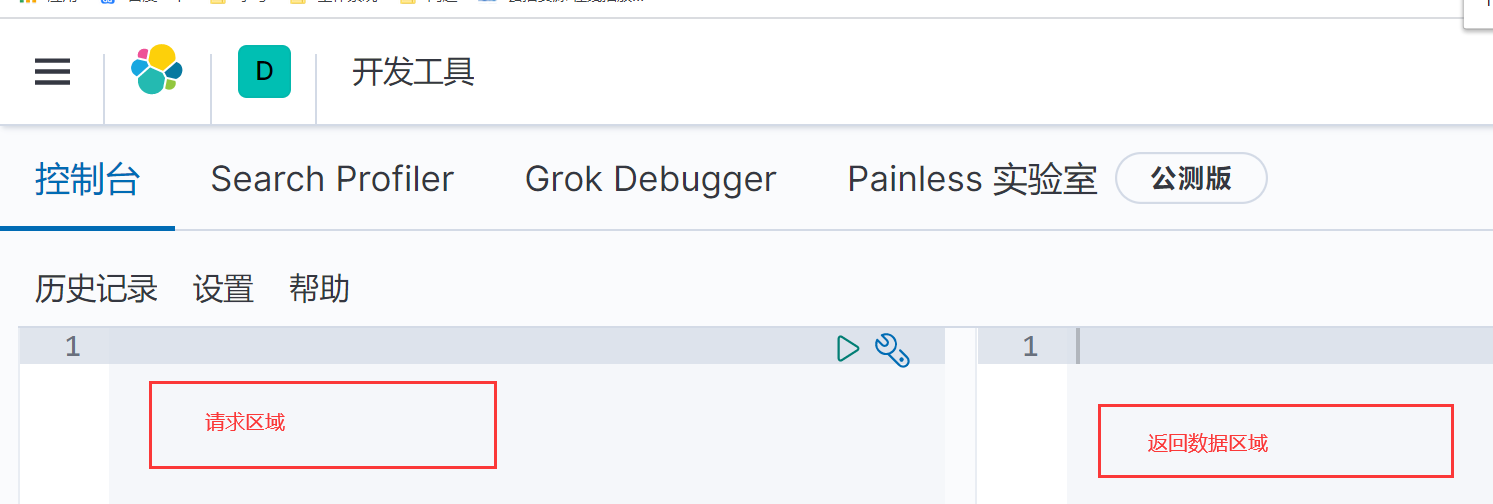
在左边的框中输入请求路径和参数即可进行数据的操作。以后与elasticsearch有关的数据操作都在这里进行开发测试,和之前的get和post请求类似,只是专业的东西用专业的工具来做。
(1)ik_smart:最少切分
GET _analyze { "analyzer": "ik_smart", "text": "中国人民" }
返回的内容如下图第一张


(2)ik_max_word:最细粒度划分
GET _analyze { "analyzer": "ik_max_word", "text": "中国人民" }
返回的内容如上图第二张。
3.Restful风格
3.1风格介绍
在elasticsearch中采用的是restful风格,具体用法如下:

3.2基本使用
1)创建索引和文档
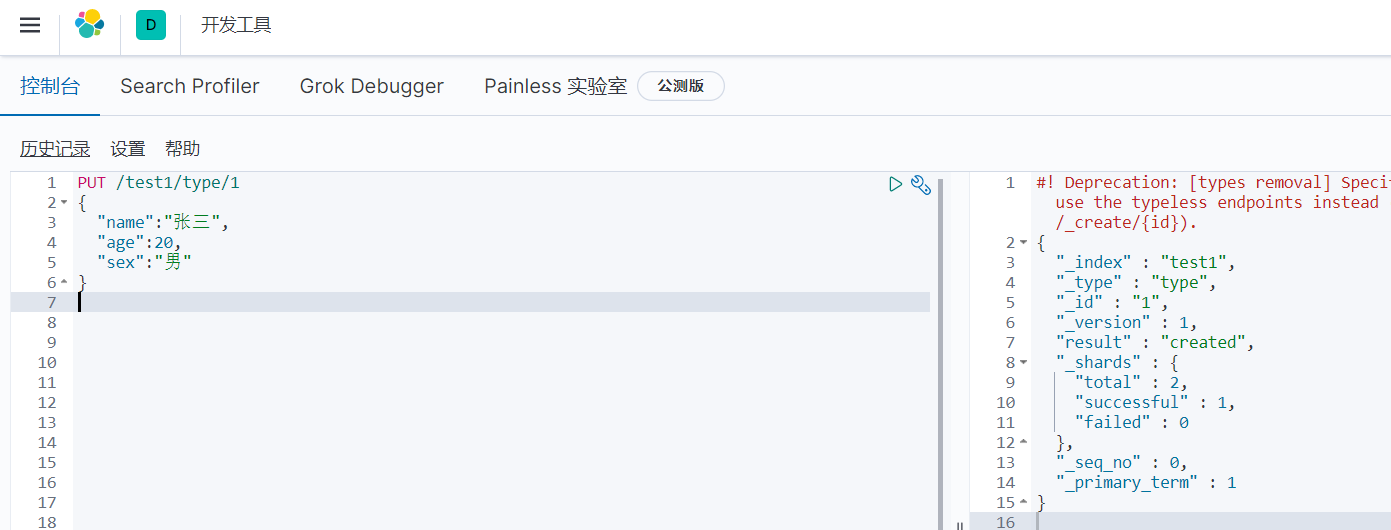
使用kibana发送请求,左边执行后,右边返回执行结果。然后再看elasticsearch-head,可以看到索引创建成功,插入了一个文档
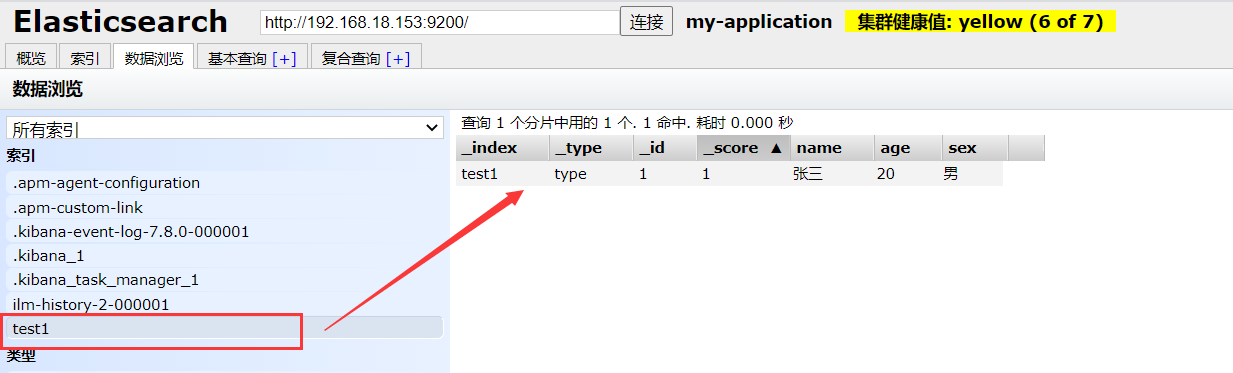
但是在我们创建索引时,对于name和age等key值并没有指定类型,elasticsearch中的类型主要有一下几个:
| 文字说明 | 类型 |
| 字符串类型 |
text,keyword |
| 数值类型 | byte,short,integer,long,float,double,half float,scaled float |
| 日期类型 | date |
| 布尔类型 | boolean |
| 二进制类型 | binary |
2)只创建索引(指定字段类型)
PUT /test2 { "mappings":{ "properties":{ "name":{ "type":"text" }, "age":{ "type":"integer" }, "brith":{ "type":"date" } } } }
创建了test2索引,指定了字段类型,name是text类型,age是integer类型,brith是date类型。
3)获取索引信息
GET test2
直接获取刚刚创建的索引信息
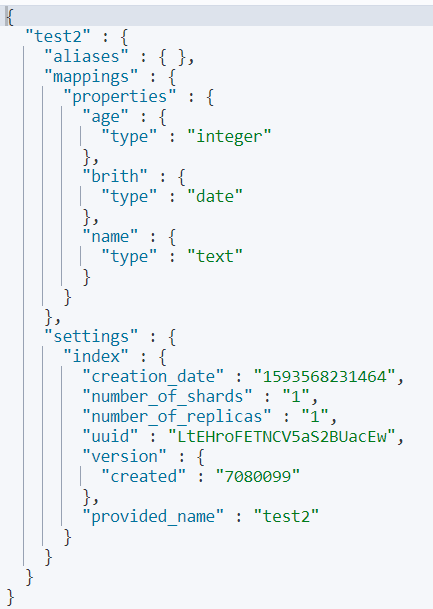
4)使用默认类型
对于类型,后面会渐渐被弃用,因此,在创建时建议指定默认的类型 “ _doc ”
PUT /test3/_doc/1 { "name":"张三", "age":20, "sex":"男", "brith":"1998-05-14" }
创建成功后查询索引信息
GET test3
看到刚刚创建的索引的几个字段都自动加了类型。

5)简单查询文档记录
GET /test3/_doc/1
返回信息

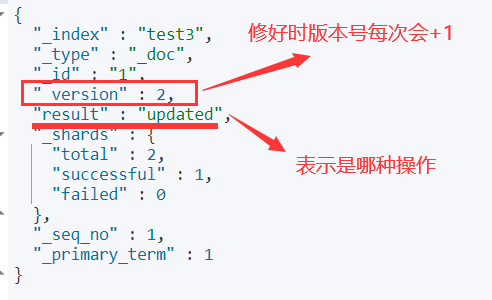
6)修改文档记录
POST /test3/_doc/1/_update
{
"doc":{
"name":"张三丰"
}
}
返回信息
7)查询所有文档记录
POST /test3/_doc/_search
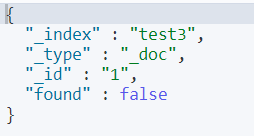
8)删除文档记录
DELETE /test3/_doc/1
删除之后再次查询,是找不到的
9)删除索引(删除test1索引)
DELETE /test1/
直接根据索引名称删除。
10)条件查询文档记录
为了查询准确,这里先给索引test3添加几个文档
PUT /test3/_doc/1 { "name":"张三1", "age":20, "sex":"男", "brith":"1998-05-14" } PUT /test3/_doc/2 { "name":"张三2", "age":22, "sex":"男", "brith":"1998-05-30" } PUT /test3/_doc/3 { "name":"张三3", "age":21, "sex":"男", "brith":"1996-06-14" } PUT /test3/_doc/4 { "name":"张三4", "age":24, "sex":"女", "brith":"1996-05-14" }
插入结果如图

(1)查询所有的男生
GET /test3/_doc/_search?q=sex:男
查询在后面加_search,q代表查询的参数
(2)查询名字中包含“张三”的人
GET /test3/_doc/_search?q=name:张三
4.整合SpringBoot
4.1环境准备
1)新建一个springboot的项目
2)导入elasticsearch的坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
3)查看版本是否一致
打开idea右侧的maven,查看elasticsearch的版本是否和自己安装的elasticsearch服务器版本一致。我目前使用的是最新的版本7.8.0,而maven的版本是7.6.2,如下图,版本不一致
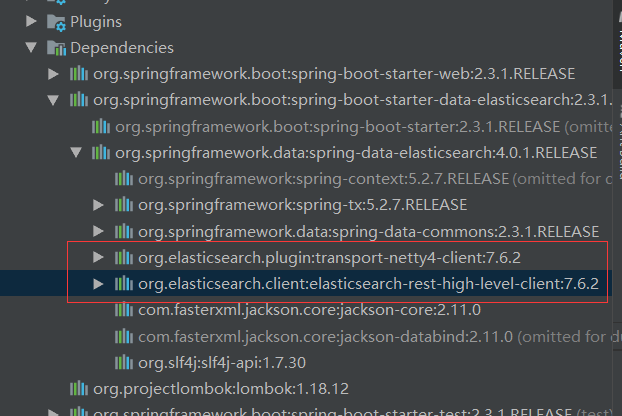
4)修改版本,保持一致
若第三步版本是一致的,则跳过此步骤,直接进入下一步。
在pom中设置版本是自己服务器的版本
<properties>
<elasticsearch.version>7.8.0</elasticsearch.version>
</properties>
导入后刷新maven,看到版本已经一致了

5)创建配置文件
package com.zys.elasticsearchserver.config; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * @author zhongyushi * @date 2020/7/11 0011 * @dec Elasticsearch配置 */ @Configuration public class ElasticsearchConfig { @Bean public RestHighLevelClient restHighLevelClient() { //配置服务地址 RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost("10.146.38.96", 9200, "http"))); return client; } }
上面的ip是服务器的ip地址。
4.2API讲解
参考网站:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/6.3/java-rest-high.html
4.2.1索引操作
1)创建索引
@Autowired private RestHighLevelClient client; //指定索引的名称 String indexName="test2020"; //创建索引 @Test public void createIndex() throws IOException { //创建索引请求 CreateIndexRequest request = new CreateIndexRequest(indexName); //发起请求,获得响应信息 CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT); System.out.println(response); }
2)获取索引、判断索引是否存在
//获取索引 @Test public void getIndex() throws IOException { //获取索引请求 GetIndexRequest request = new GetIndexRequest(indexName); //判断索引是否存在 boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); if(exists){ //获取索引 GetIndexResponse res = client.indices().get(request, RequestOptions.DEFAULT); System.out.println(res); } }
3)删除索引
//删除索引 @Test public void deleteIndex() throws IOException { //获取索引请求 DeleteIndexRequest request = new DeleteIndexRequest(indexName); //获取索引 AcknowledgedResponse res = client.indices().delete(request, RequestOptions.DEFAULT); //通过isAcknowledged()判断是否删除成功 System.out.println(res.isAcknowledged()); }
4.2.2文档操作
首先创建一个对象,再进行后面的操作
@Data @NoArgsConstructor @AllArgsConstructor public class User { private String name; private Integer age; private String addr; }
1)创建文档【同步】
使用对象类型:
//创建文档 @Test public void createDocument() throws IOException { User user=new User("张三",20,"武汉"); //在进行之前需要先保证索引已经创建 IndexRequest request=new IndexRequest(indexName);
//设置id,方便查询
request.id("1"); //把数据放入请求 request.source(JSON.toJSONString(user), XContentType.JSON); //发送请求 IndexResponse index = client.index(request, RequestOptions.DEFAULT); //创建后的文档信息 System.out.println(index.toString()); //获取命令的状态 System.out.println(index.status()); }
使用map类型:(自动把map转为json)
//创建文档 @Test public void createDocument2() throws IOException { Map<String,Object> map=new HashMap<>(); map.put("name","张三丰"); map.put("sex","男"); map.put("phone","13265452542"); map.put("brith",new Date()); IndexRequest request=new IndexRequest(indexName); //设置id request.id("1"); //把数据放入请求 request.source(map); //发送请求 IndexResponse index = client.index(request, RequestOptions.DEFAULT); //获取命令的状态 System.out.println(index.status()); }
使用key-value形式:(和map类型相似)
//创建文档 @Test public void createDocument3() throws IOException { IndexRequest request=new IndexRequest(indexName); //把数据放入请求 request.source("name","周芷若","sex","女","phone","13265452541"); //发送请求 IndexResponse index = client.index(request, RequestOptions.DEFAULT); //获取命令的状态 System.out.println(index.status()); }
使用XContentBuilder类型:(自动把XContentBuilder转为json content)
//创建文档 @Test public void createDocument4() throws IOException { XContentBuilder builder = XContentFactory.jsonBuilder(); builder.startObject(); { builder.field("name", "张无忌"); builder.timeField("sex", "男"); builder.field("brith", new Date()); } builder.endObject(); IndexRequest request=new IndexRequest(indexName); //把数据放入请求 request.source(builder); //发送请求 IndexResponse index = client.index(request, RequestOptions.DEFAULT); //获取命令的状态 System.out.println(index.status()); }
2)创建文件【异步】
除了上面的那种同步创建方式之外,还有异步的方式,这种方式需要创建一个监听器,在监听器中有两个方法可以重写,成功时回调方法和失败时回调方法。
ActionListener<IndexResponse> listener = new ActionListener<IndexResponse>() { @Override public void onResponse(IndexResponse indexResponse) { //执行成功的回调 System.out.println(indexResponse); } @Override public void onFailure(Exception e) { //执行失败的回调 System.out.println(e); } }; //创建文档 @Test public void createDocument() throws IOException { User user=new User("张三",20,"武汉"); //在进行之前需要先保证索引已经创建 IndexRequest request=new IndexRequest(indexName); //设置id request.id("1"); //把数据放入请求 request.source(JSON.toJSONString(user), XContentType.JSON); //发送请求 client.indexAsync(request,RequestOptions.DEFAULT,listener); }
3)获取文档
//获取文档 @Test public void getDocument() throws IOException { //指定文档id GetRequest request=new GetRequest(indexName,"1"); //发送请求 boolean exists = client.exists(request, RequestOptions.DEFAULT); if(exists){ GetResponse documentFields = client.get(request, RequestOptions.DEFAULT); System.out.println(documentFields); //获取对象(字符串) System.out.println(documentFields.getSourceAsString()); //获取对象(map) System.out.println(documentFields.getSourceAsMap()); } }
上例中判断文档是否存在,是同步的方式,异步方式判断如下
client.existsAsync(getRequest, listener);
4)修改文档
//修改文档 @Test public void updateDocument() throws IOException { User user=new User(); user.setName("李四"); user.setAddr("北京"); UpdateRequest request=new UpdateRequest(indexName,"1"); //把数据放入请求 request.doc(JSON.toJSONString(user), XContentType.JSON); //发送请求 UpdateResponse update = client.update(request, RequestOptions.DEFAULT); //获取命令的状态 System.out.println(update.status()); }
上例中修改文档是同步的方式,异步方式如下
client.updateAsync(request, listener);
当文档不存在时,会发生异常,若想使用更新,则可以使用upsert方法,它会创建一条文档信息
try{ client.update(request, RequestOptions.DEFAULT); }catch (ElasticsearchException e){ if (e.status() == RestStatus.NOT_FOUND) { request.upsert(JSON.toJSONString(user), XContentType.JSON); client.update(request, RequestOptions.DEFAULT); } }
5)删除文档
//删除文档 @Test public void deleteDocument() throws IOException { DeleteRequest request=new DeleteRequest(indexName,"1"); //发送请求 DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT); //获取命令的状态 System.out.println(delete.status()); }
上例中删除文档是同步的方式,异步方式如下
client.deleteAsync(request, listener);
6)批量插入
//批量插入数据 @Test public void insertBatch() throws IOException { //创建数据源 List<User> list=new ArrayList<>(); for (int i = 0; i < 10; i++) { User user=new User("张三"+i,20+i,"武汉市"+i+"区"); list.add(user); } BulkRequest request=new BulkRequest(); //把数据放入请求中 for (int i = 0; i < list.size(); i++) { request.add(new IndexRequest(indexName) .id(""+(i+1)) .source(JSON.toJSONString(list.get(i)),XContentType.JSON)); } //发送请求 BulkResponse bulk = client.bulk(request,RequestOptions.DEFAULT); //是否执行成功,成功返回false System.out.println(bulk.hasFailures()); }
上例中实现了批量插入,也可以同时进行批量删除和修改,类同。异步方式
client.bulkAsync(request, listener);
7)数据查询
//查询数据 @Test public void query2() throws IOException { SearchRequest request = new SearchRequest(indexName); //设置查询条件,当进行精确查询时,中文会进行分词,直接使用字段就查询不到数据,这时可以在字段后面加keyword // TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name","abcde"); // TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name.keyword","张三"); //模糊查询,查询name包含ddd的数据 WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery("name","*b*"); //构建搜索条件 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //排序,按照年龄的降序 sourceBuilder.sort(new FieldSortBuilder("age").order(SortOrder.DESC)); //设置分页,from起始索引,size每页条数,它们的默认值分别是0,10 sourceBuilder.from(0); sourceBuilder.size(20); //把查询条件放进去 sourceBuilder.query(wildcardQueryBuilder); //把构建起放入请求 request.source(sourceBuilder); //发送请求 SearchResponse search = client.search(request, RequestOptions.DEFAULT); //遍历获取返回的结果 for (SearchHit hit : search.getHits()) { Map<String, Object> sourceAsMap = hit.getSourceAsMap(); System.out.println(sourceAsMap); } }
高亮查询:原理就是设置要显示的高亮字段(添加标签),然后把查询出来的结果中要高亮显示的字段替换成设置好的高亮显示的字段内容
//查询数据 @Test public void query() throws IOException { SearchRequest request = new SearchRequest(indexName); //设置查询条件,当进行精确查询时,他会进行分词,直接使用字段就查询不到数据,这时可以在字段后面加keyword TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name","abcde"); //高亮查询:原理就是设置要显示的高亮字段(添加标签),然后把查询出来的结果中要高亮显示的字段替换成设置好的高亮显示的字段内容 HighlightBuilder highlightBuilder = new HighlightBuilder(); //设置显示高亮的字段 highlightBuilder.field("name"); //打开多个高亮显示 highlightBuilder.requireFieldMatch(false); //给高亮显示添加标签 highlightBuilder.preTags("<span style='color:red'>"); highlightBuilder.postTags("</span>"); //构建搜索条件 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //把查询条件放进去 sourceBuilder.query(termQueryBuilder); // sourceBuilder.query(queryBuilder); //高亮显示放进去 sourceBuilder.highlighter(highlightBuilder); //把构建起放入请求 request.source(sourceBuilder); //发送请求 SearchResponse search = client.search(request, RequestOptions.DEFAULT); //遍历获取返回的结果 for (SearchHit hit : search.getHits()) { //获取查询的结果 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); //获取高亮显示的字段 Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField name = highlightFields.get("name"); //把要显示的高亮字段替换成设置好的高亮字段 if(name!=null){ Text[] texts = name.fragments(); String newText = ""; for (Text text : texts) { newText += text; } //替换字段内容 sourceAsMap.put("name",newText); } System.out.println(sourceAsMap); } }
看到返回的结果带上了span标签,在页面中显示出来即可。

4.2.3响应数据详解
1)indexResponse/deleteResponse/updateResponse(创建/删除/修改文档的响应数据)
//创建文档 @Test public void createDocument() throws IOException { User user=new User("张三",20,"武汉1"); //在进行之前需要先保证索引已经创建 IndexRequest request=new IndexRequest(indexName); //设置id request.id("1"); //把数据放入请求 request.source(JSON.toJSONString(user), XContentType.JSON); //发送请求 IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT); //获取索引名称 String index =indexResponse.getIndex(); //获取类型,默认是_doc String type = indexResponse.getType(); //获取文档id String id = indexResponse.getId(); //获取版本类型 long version = indexResponse.getVersion(); //操作结果类型 DocWriteResponse.Result result = indexResponse.getResult(); if (result == DocWriteResponse.Result.CREATED) { //创建文档后的操作 System.out.println("创建文档成功"); } else if (result == DocWriteResponse.Result.UPDATED) { //修改文档后的操作 System.out.println("修改文档成功"); } //获取碎片信息 ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo(); if (shardInfo.getTotal() != shardInfo.getSuccessful()) { //成功碎片数少于总碎片数的情况 System.out.println(shardInfo.getTotal()+","+shardInfo.getSuccessful()); } if (shardInfo.getFailed() > 0) { ////处理潜在的故障 for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) { String reason = failure.reason(); System.out.println(reason); } } }
上面返回的数据有很多,根据自己的需求来获取。创建文档和删除文档返回的数据是类似的,删除文档的响应数据在此略。
2)getResponse(获取文档的响应数据)
@Test public void getDocument() throws IOException { //指定文档id GetRequest request = new GetRequest(indexName, "11"); //发送请求 GetResponse getResponse = client.get(request, RequestOptions.DEFAULT); String index = getResponse.getIndex(); String type = getResponse.getType(); String id = getResponse.getId(); //判断是否查询到文档信息 if (getResponse.isExists()) { //获取对象(字符串) System.out.println(getResponse.getSourceAsString()); //获取对象(map) System.out.println(getResponse.getSourceAsMap()); } }
3)bulkResponse(批量操作的响应数据)
for (BulkItemResponse bulkItemResponse : bulkResponse) { DocWriteResponse itemResponse = bulkItemResponse.getResponse(); if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX || bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) { //创建文档 IndexResponse indexResponse = (IndexResponse) itemResponse; } else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) { //修改文档 UpdateResponse updateResponse = (UpdateResponse) itemResponse; } else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) { //删除文档 DeleteResponse deleteResponse = (DeleteResponse) itemResponse; } }
4.2.4异常处理
1)当创建文档版本发生冲突时
IndexRequest request = new IndexRequest("myindex","doc","1").version(2); try { IndexResponse response = client.index(request); } catch(ElasticsearchException e) { if (e.status() == RestStatus.CONFLICT) { //处理异常 } }
2)查询索引不存在的文档信息
GetRequest request = new GetRequest("myindex", "1"); try { GetResponse getResponse = client.get(request); } catch (ElasticsearchException e) { if (e.status() == RestStatus.NOT_FOUND) { //索引不存在的处理 } }
3)获取文档,当指定的文档版本与实际的版本不一致时
try { GetRequest request = new GetRequest(indexName, "1").version(4); GetResponse getResponse = client.get(request); } catch (ElasticsearchException exception) { if (exception.status() == RestStatus.CONFLICT) { //当前版本与查询的版本不一致 } }
4)修改不存在的文档时
UpdateRequest request = new UpdateRequest(indexName, "11"); //把数据放入请求 request.doc(JSON.toJSONString(user), XContentType.JSON); try{ client.update(request, RequestOptions.DEFAULT); }catch (ElasticsearchException e){ if (e.status() == RestStatus.NOT_FOUND) { //异常处理 } }
5)当删除/修改时指定了版本,发生版本冲突
try { DeleteRequest request = new DeleteRequest("myindex", "doc", "1").version(2); DeleteResponse deleteResponse = client.delete(request); } catch (ElasticsearchException exception) { if (exception.status() == RestStatus.CONFLICT) { //异常处理 } }