Introduction
这篇paper是做Transformer压缩的,但其实bert的核心也就是transformer,这篇paper的实验里也做了bert的压缩。作者的主要工作是提出了LayerDrop的方法,即一种结构化的dropout的方法来对transformer模型进行训练,从而在不需要fine-tune的情况下选择一个大网络的子网络。
这篇paper方法的核心是通过Dropout来去从大模型中采样子网络,但是这个dropout是对分组权重进行dropout的,具体而言,这篇paper是layerwise的dropout,可见下图:
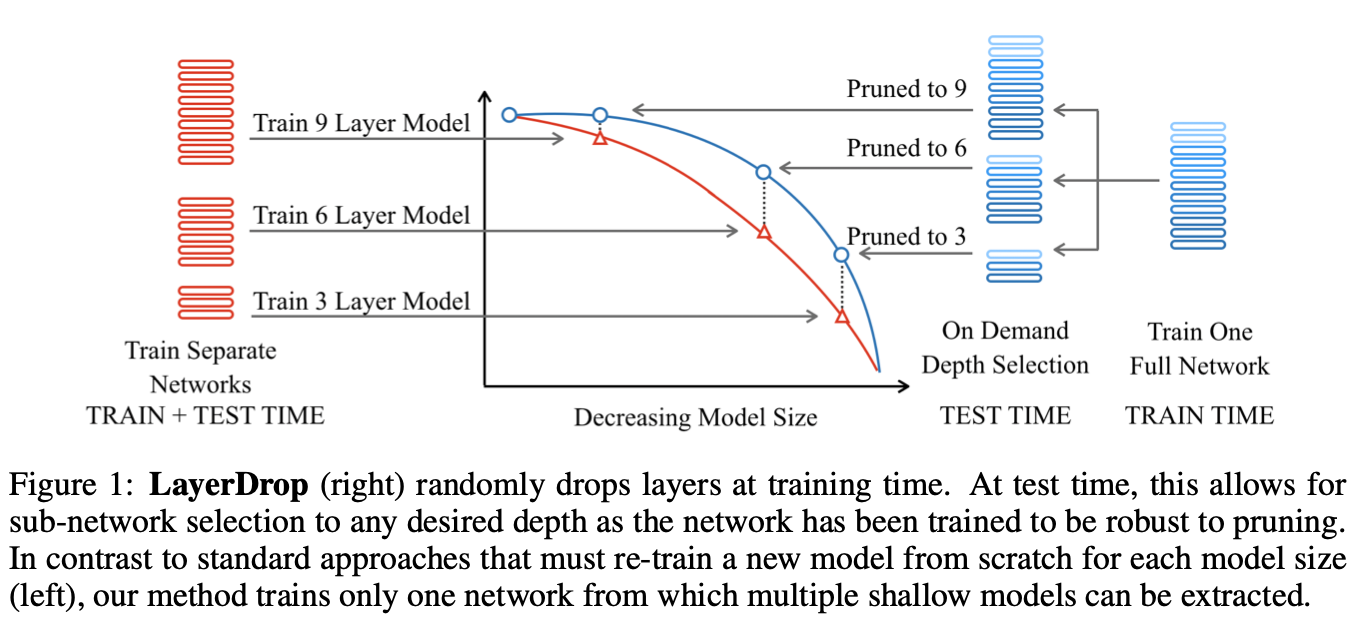
作者提出的方法是用LayerDrop的方法只训练一遍网络,然后在测试的时候可以根据不同的需求来选择不同的深度。
Method
Transformer Architecture
首先回顾一下transformer的结构,一个transformer由若干个层组成,每个层包含一个多头注意力模块和一个全连接的前向层,每个注意力头的输入是一个矩阵X,X的每一行输入句子的每一个元素,然后进行下面的运算:
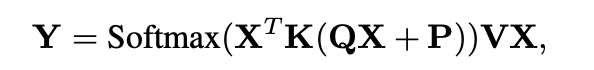
其中K、V、Q是三个参数矩阵,这一步输入的多个注意力头的结果会被拼接和变形为同样大小的X向量,然后经过一个全连接层:
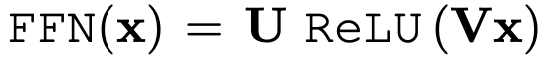
然后transformer中其实还是有一个类似于ResNet的残差模块,因为在整个transformer中的生成的向量维度都一样,所以可以方便的进行addnorm操作来避免梯度消失的问题,同时transformer还引入了layer normalization的操作,这个是对同一层中的所有输出做标准化,而BN是对一个batch中的所有样本输出做标准化。
whatever,前面只是一个对transformer的复习~
Training Transformers with Random Structured Pruning
作者提出了一个可以让transformer能够在测试过程中使用不同深度的正则项训练方法,主要关注点在于剪枝层数。那为什么作者选择减少层数呢?举例而言,如果减少attention head的数量,那么其实是不能起到加速作用的,因为attention模块的计算是并行的。
那么最重要的问题就是要剪哪些层呢?作者考虑了不同的剪枝策略:
-
Every Other
即每隔一层就以一定概率剪枝一层
-
Search on Valid
计算不同组合的layer在验证集上的表现,这种往往非常耗时
-
Data Driven Pruning
对每一个layer学习一个参数p,使得全局剪枝率为p*,然后对每个layer的输出添加这么一个非线性函数,在前向的时候只选择计算分数最高的k个layer。
Conclusion
这篇transformer压缩其实主要的工作在于很多的实验,因为还不太了解这块的各种数据集,所以就没有细看实验。这篇paper通过结构化的dropout来对网络进行训练,主要剪的是层数。