环境: anaconda
anaconda: 是一个集成环境(数据分析+机器学习),提供了一个叫做jupyter的可视化工具(基于浏览器)
启动: cmd>jupyter notebook
jupyter的基本使用:
-
快捷键:
- 插入cell:a,b
- 删除:x
- 执行:shift+enter
- 切换cell的模式:y,m
- tab:自动补全
- 打开帮助文档:shift+tab
-
cell分为两种模式
- code:编码
- markdown:编写文本
一, 爬虫概述
什么是爬虫:
- 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程。
爬虫的分类:
- 通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 简单来讲就是尽可能的;把互联网上的所有的网页下载下来,放到本地服务器里形成备分,在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
- 搜索引擎如何抓取互联网上的网站数据?
- 门户网站主动向搜索引擎公司提供其网站的url
- 搜索引擎公司与DNS服务商合作,获取网站的url
- 门户网站主动挂靠在一些知名网站的友情链接中
- 搜索引擎如何抓取互联网上的网站数据?
- 聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
- 增量式爬虫:监测网站数据更新的情况。抓取的是网站最新更新出来的数据。
爬虫安全性的探究
-
风险所在
- 爬虫干扰了被访问网站的正常运营;
- 爬虫抓取了受到法律保护的特定类型的数据或信息
-
如何规避风险
- 严格遵守网站设置的robots协议;
- 在规避反爬虫措施的同时,需要优化自己的代码,避免干扰被访问网站的正常运行;
- 在使用、传播抓取到的信息时,应审查所抓取的内容,如发现属于用户的个人信息、隐私或者他人的商业秘密的,应及时停止并删除
-
反爬机制:应用在网站中,门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
-
反反爬策略:应用在爬虫程序中, 爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
-
第一个反爬机制:
- robots协议:纯文本的协议
- 特点:防君子不防小人
- robots协议:纯文本的协议
二, http协议和https协议
HTTP协议
什么是HTTP协议?
HTTP协议就是服务器(Server)和客户端(Client)之间进行数据交互(相互传输数据)的一种形式。我们可以将Server和Client进行拟人化,那么该协议就是Server和Client这两兄弟间指定的一种交互沟通方式。
HTTP工作原理:
HTTP协议工作于客户端--服务端架构上。浏览器作为HTTP客户端,通过URL向HTTP服务端即WEB服务器发送请求。Web服务器根据接收到的请求后,向客户端发送响应信息.
HTTP四点注意事项:
- HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
HTTP之URL:
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。
HTTP之Request:
报文头:常被叫做请求头,请求头中存储的是该请求的一些主要说明(自我介绍)。服务器据此获取客户端的信息。
常见的请求头:
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
X-Requested-With: XMLHttpRequest 代表通过ajax方式进行访问
User-Agent:请求载体的身份标识
报文体:常被叫做请求体,请求体中存储的是将要传输/发送给服务器的数据信息。
HTTP之Response:
状态码:以“清晰明确”的语言告诉客户端本次请求的处理结果。
HTTP的响应状态码由5段组成:
1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急...
2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
相应头:响应的详情展示
常见的相应头信息:
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
相应体:根据客户端指定的请求信息,发送给客户端的指定数据
HTTPS协议
HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。
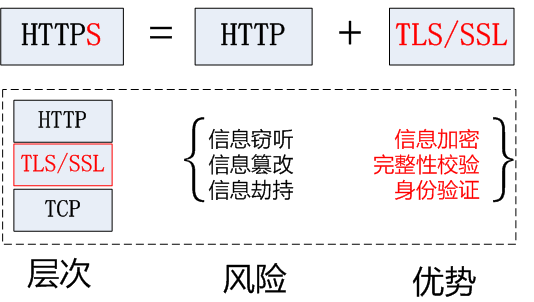
HTTPS采用的加密技术:
SSL加密技术:
SSL采用的加密技术叫做“共享秘钥加密”,也叫作“对称秘钥加密”,这种加密方法是这样的,比如客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递秘钥,(加密和解密的密钥是同一个),秘钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解秘钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患
非对称秘钥加密技术:
“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对称加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接收到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。
但是非对称秘钥加密技术也存在如下缺点:
第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
第二个是:非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
HTTPS的证书机制:
在上面我们讲了非对称加密的缺点,其中第一个就是公钥很可能存在被挟持的情况,无法保证客户端收到的公开密钥就是服务器发行的公开密钥。此时就引出了公开密钥证书机制。数字证书认证机构是客户端与服务器都可信赖的第三方机构。证书的具体传播过程如下:
1:服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起

2:服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。