linux内核分析学习笔记 ——第六章 进程的描述和进程的创建
学习重点——子进程的创建以及运行流程
进程描述和进程的创建
操作系统的三大功能——进程管理、内存管理和文件系统。
在linux内核中利用struct task_struct数据结构来描述进程。

其中包括了进程状态state、stack堆栈、进程双向链表struct list_head、控制台tty、文件系统fs的描述,进程打开文件的文件描述files、内存管理的描述mm、进程间通信的信号signal等等。
进程状态包括就绪台、运行态和阻塞态这三种基本状态。

- TASK_RUNNING有两个状态,一个是就绪态但是没有运行,另一个是运行态,这两个状态的转换依赖于内核中的调度器
另一种方式说TASK_RUNNING处运行态取决于它是否获得了CPU的控制权;如果被内核调度出去,就在等待队列中。 - 对于正在运行的进程,调用用户态库函数
exit()会陷入内核执行do_exit()进入TASK_ZOMBIE状态。 - 阻塞态也有两种
- TASK_UNINTERRUPTIBLE 可以被wake_up()唤醒
- TASK_INTERRUPTIBLE 可以被wake_up()和信号唤醒

进程的创建
0号进程的创建
在前面我们学到了,内核的第一个进程0号进程init_task的进程描述符结构体变量的初始化是通过硬编码方式确定下来的,其他的所有进程都是通过do_fork的方式复制父进程来初始化的。
内存管理相关代码
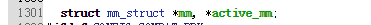
每个进程都有数据段、代码段、堆栈段等,他们就是由这个数据结构统领起来的。
进程之间的关系

进程描述符通过双向链表struct list_head_tasks双向链表来管理所有进程。
- real_partent parent用来记录当前父进程
- struct list_head_children双向链表 记录了当前的子进程
- struct list_head_list_sibling双向链表 记录了当前的兄弟进程
保存进程上下文中CPU相关信息的数据结构
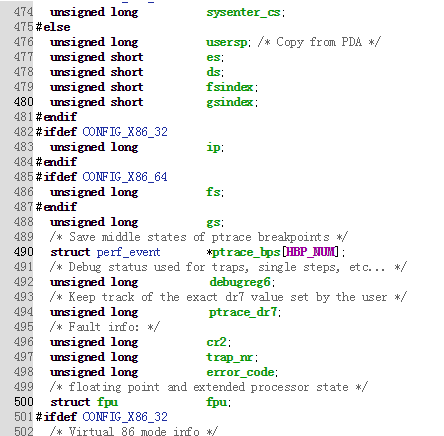
struct_thread_struct数据结构用来保存进程上下文中一些信息,最关键的是sp和ip,分别用来保存ESP寄存器状态和EIP寄存器状态。
进程创建的基本过程
- 将当前进程的描述符等相关进程资源复制一份
- 子进程要对复制的进程描述符进行一些修改
- 创建好的子进程放入运行队列
- 系统调度时,子进程将有机会被调度
do_fork()函数分析
不管是fork vfork还是clone 都是通过do_fork()函数创建进程。
触发系统调用的过程

一般的系统调用,在用户态 int $0x80 指令触发中断机制,跳转到内核态执行system_call系统调用,此时会把用户进程用户态的堆栈SS:EIP和CS:EIP和EFLAGS都压栈到当前内核堆栈中。最后iret恢复现场,回到用户态。


do_fork()的参数
- clone_flags 子进程创建的相关标志,通过此标志对父进程资源进行有选择的复制
- stack_start 子进程用户态堆栈地址
- stack_size 用户栈大小
- *parent_tidptr 指向父进程pid的指针
- *child_tidptr 指向子进程pid的指针
其中函数copy_process()函数用来创建子进程的进程描述符和其他相关数据结构
函数weak_up_new_task()作业是将子进程添加到进程调度队列。
copy_process()函数分析


copy_process中主要调用了dup_task_struct()和copy_thread()函数

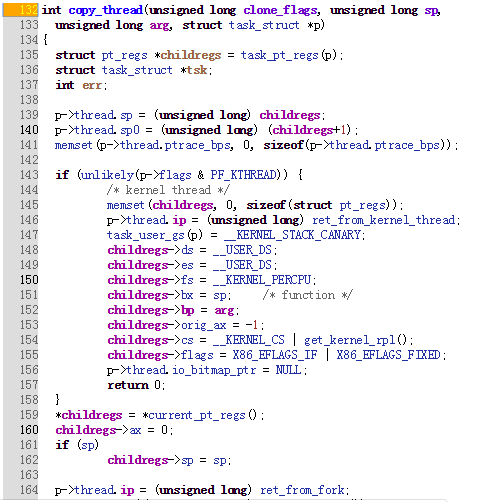
其中dup_task_struct()复制当前的进程描述符、信息检查、初始化、设置进程为就绪态、采用写时复制技术复制所有父进程的资源。
copy_thread()初始化了子进程的内核栈、设置子进程的pid
dup_task_struct()为子进程分配好了内核栈后,由copy_thread()初始化内核栈的关键信息。
如果为用户进程,子程序开始执行的起点是ret_from_fork
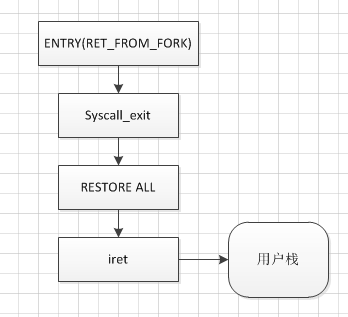
以用户态进程为例,子程序的起点是系统调用在内核态中的ret_from_fork,执行结束后,恢复现场返回用户态,此时返回的用户态堆栈是子进程的堆栈,执行子进程的相关函数
thread_info数据结构
- 通过task指针指向进程描述符,同时task_struct的stack字段指向本进程的thread_info结构首地址。
-下图所示是内核栈、 thread_info结构和进程描述符之间的关系。
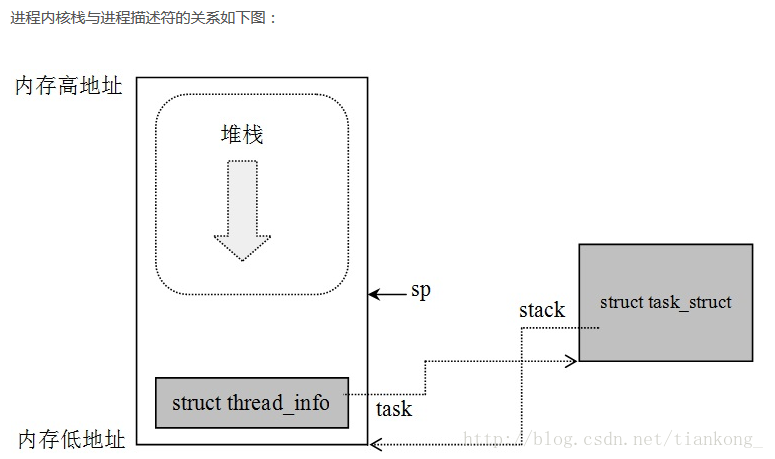
- thread_info记录了部分进程信息的结构体,包括了进程上下文信息。
实验跟踪分析进程创建的过程

编译好的MenuOS添加了fork功能,如下图所示

下面进行调试,为MenuOS添加断点,分别在sys_clone do_fork dup_task_struct copy_process``copy_thread处

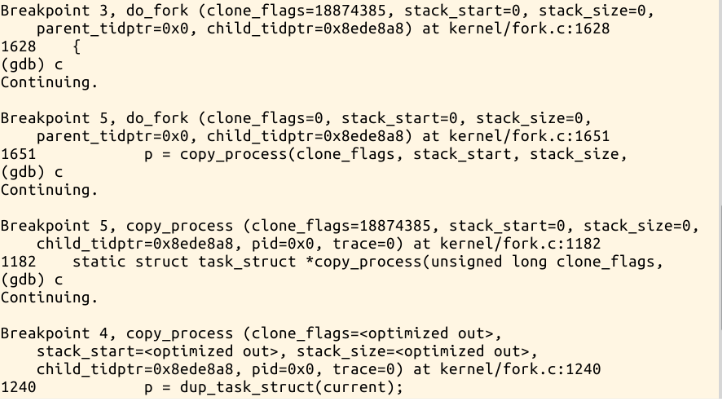

在命令行中输入fork发现停在sys_clone处,说明系统调用函数是sys_clone继续执行会停在do_fork中,系统调用函数的示意图大概是下图所示

系统调用创建子进程函数
linux系统下来实现创建进程,它们封装的对应的内核处理函数都是do_fork()
- fork() 创建的子进程是父进程的完整副本,复制了父进程的资源,包括内存task_struct内容
当进程A使用系统调用fork创建一个子进程B时,由于子进程B实际上是父进程A的一个拷贝,因此会拥有与父进程相同的物理页面。
- vfork()创建的子进程与父进程共享数据段,同时子进程会优先于父进程运行
由vfok创建出来的子进程共享了父进程的所有内存,包括栈地址,直至子进程使用execve启动新的应用程序为止
- clone() linux创建线程一般使用pthread库,clone是linux为我们提供的创建线程的系统调用
fork()函数理解
fork()函数功能是创建一个子进程。进程的唯一标识是pid,利用系统调用getpid()可以获得当前进程的进程号;利用getppid()可以获得当前进程父进程的进程号。

而进程所产生的父进程则是根据fork()的返回值来确定的。成功创建子进程后,父进程获得子进程的ID。而子进程获得返回值0。
注意事项:
- fork系统调用之后,父进程和子进程交替执行,并处于不同的空间中。
- fork()函数一次调用返回2次返回。两个进程处于不同的独立空间中而至于是先子进程还是父进程先执行,这没有确切的规定,是随机的。
——— 即并发的特性
子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。注意,子进程持有的是上述存储空间的“副本”,这意味着父子进程间不共享这些存储空间。
注意:复制内核堆栈的时候只是复制了内核堆栈的一部分,而不是全部复制。
- fork()的子执行过程在fork()之后并不是从头开始,父进程已经为子进程搭建好了运行环境,所以字节有效代码处开始执行。
由于在复制时复制了父进程的堆栈段,所以两个进程都停留在fork函数中,等待返回。因此fork函数会返回两次,一次是在父进程中返回,另一次是在子进程中返回,这两次的返回值是不一样的。
返回值可以理解为链表,fork()的父进程在创建了子进程后,“指针”指向了子进程的pid,所以返回值为子进程pid,而子进程没有指向,所以返回值为0