为什么需要分布式事物
比如某一系统中,有两个独立的微服务,一个是订单服务,一个是库存服务。这俩服务各自都有一个自己的数据库。
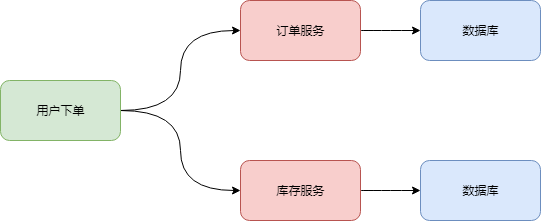
那么一个用户在下单时候怎么保证在订单库里有一条订单数据,同时,库存数据库的数据也能相应的减少,让两边数据维持着一致性,不能出现订单创建完成,而库存没有对应减少的情况,这就需要分布式事务来保证了。
分布式事务解决方案
分布式事务的解决方案,典型的有两阶段和三阶段提交协议
2PC 两阶段提交
两阶段提交(2PC,Two-phase Commit Protocol)是非常经典的强一致性、中心化的原子提交协议,在各种事务和一致性的解决方案中,都能看到两阶段提交的应用。
2pc中包含两个角色:协调者和参与者,协调者可以简单理解为协调完成此次事物的领导/组织者,而参与者可以理解为真实在本节点执行事物的成员。
两阶段提交中的两个阶段,指的是 prepare 阶段和 Commit 阶段,两阶段提交的流程如下:
prepare 阶段
-
协调者首先向所有的参与者发出准备执行通知
-
参与者收到协调者的通知后,各自开始在本地执行事物,但是不提交,并且写本地的redo和undo日志。然后参与者向协调者反馈结果(ACK)
-
协调者根据反馈做出不同的通知
-
如果协调者收到全部参与者均为正常执行的反馈(也就是说所有参与者都成功完成了本地事物),则给参与者发送commit通知,进入commit阶段
-
-
如果协调者收到了某个参与执行失败的反馈,则发出rollback通知
-
-
如果协调者迟迟收不到某个参与者的反馈而导致超时,则发出rollback通知
-
commit阶段
进入了该阶段,也就表示协调者收到全部参与者均为正常执行的反馈,这时:
- 协调者发出commit的通知
- 参与者收到commit通知,执行提交,并释放资源
- 然后参与者反馈提交结果给协调者
两阶段提交存在的问题
资源被同步阻塞
在执行过程中,所有参与节点都是事务独占状态,当参与者占有公共资源时,那么第三方节点访问公共资源会被阻塞。
协调者可能出现单点故障
由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
在 Commit 阶段出现数据不一致
在第二阶段中,假设协调者发出了Commit 的通知,但是由于网络问题该通知仅被一部分参与者所收到并执行 Commit,其余的参与者没有收到通知,一直处于阻塞等待状态,于是整个分布式系统便出现了数据不一致性的现象。
协调者,参与者都发生故障
比如协调者在发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
3PC 三阶段提交
三阶段提交协议(3PC,Three-phase_commit_protocol)是在 2PC 之上扩展的提交协议,分为了三个阶段,并且为了解决二阶段协议中的同步阻塞等问题,三阶段提交协议在协调者和参与者中都引入了超时机制(在 2PC 中,只有协调者拥有超时机制)。
三阶段中的 Three Phase 分别为 CanCommit、PreCommit、DoCommit 阶段。
CanCommit阶段
-
协调者询问各个参与者是否可以正常执行,然后等待参与者的响应。
-
参与者预估判断是否可以执行(注意这里不做事物操作),向协调者反馈
-
协调者根据参与者的反馈做出不同的通知
-
如果所有参与者反馈为YES,则执行PreCommit阶段
-
-
如果有参与者反馈为NO,则协调者向所有参与者发送abort通知。参与者收到协调者的abort通知之后,执行事务的中断。
-
-
如果协调者迟迟收不到某个/些参与者的反馈,造成等待超时(协调者等不下去了),则协调者向所有参与者发送abort通知。参与者收到协调者的abort通知之后,执行事务的中断。
-
另外,如果参与者在反馈之后,迟迟收不到协调者的通知造成等到超时,则参与者也会执行事物中断
PreCommit阶段
-
协调者向参与者发送PreCommit通知,然后等待参与者的响应。
-
参与者收到协调者的通知后,各自开始在本地执行事物,但是不提交,并且写本地的redo和undo日志。然后参与者向协调者反馈结果(ACK)
-
协调者根据参与者的反馈做出不同的通知
-
如果协调者收到全部参与者均为正常执行的反馈(也就是说所有参与者都成功完成了本地事物),则给参与者发送commit通知,进入doCommit阶段
-
-
如果有参与者反馈为执行失败,则协调者向所有参与者发送rollack通知。参与者收到协调者的rollack通知之后,执行事务的回滚。
-
-
如果协调者迟迟收不到某个参与者的反馈,造成等待超时(协调者等不下去了),则协调者向所有参与者发送rollack通知。参与者收到协调者的rollack通知之后,执行事务的回滚。
-
DoCommit阶段
-
协调者向所有参与者发出事物提交的通知
-
参与者收到通知之后,执行commit;另外如果参与者迟迟收不到协调者的通知造成等待超时,参与者也会主动执行commit。完成事务提交之后释放所有事务资源。
-
参与者反馈事物提交结果
三阶段提交协议存在的问题
三阶段提交协议同样存在问题,在DoCommit阶段中,如果参与者出现了不能与协调者正常通信的问题,在这种情况下,参与者依然会进行事务的提交,这可能就出现了数据的不一致性。
基于两阶段提交的应用--hbase snapshot
hbase为指定表执行snapshot操作,实际上真正执行snapshot的是对应表的所有region。这些region因为分布在多个RegionServer上,所以需要一种机制来保证所有参与执行snapshot的region要么全部完成,要么都没有开始做,不能出现中间状态,比如某些region完成了,某些region未完成。
接下来就看看hbase是如何使用2PC协议来构建snapshot架构的,基本步骤如下:
-
prepare阶段:HMaster在zookeeper创建一个’/acquired-snapshotname’节点,并在此节点上写入snapshot相关信息(snapshot表信息)。所有regionserver监测到这个节点之后,根据/acquired-snapshotname节点携带的snapshot表信息查看当前regionserver上是否存在目标表,如果不存在,就忽略该命令。如果存在,遍历目标表中的所有region,分别针对每个region执行snapshot操作,注意此处snapshot操作的结果并没有写入最终文件夹,而是写入临时文件夹。regionserver执行完成之后会在/acquired-snapshotname节点下新建一个子节点/acquired-snapshotname/nodex,表示nodex节点完成了该regionserver上所有相关region的snapshot准备工作。
-
commit阶段:一旦所有regionserver都完成了snapshot的prepared工作,即都在/acquired-snapshotname节点下新建了对应子节点,hmaster就认为snapshot的准备工作完全完成。master会新建一个新的节点/reached-snapshotname,表示发送一个commit命令给参与的regionserver。所有regionserver监测到/reached-snapshotname节点之后,执行snapshot commit操作,commit操作非常简单,只需要将prepare阶段生成的结果从临时文件夹移动到最终文件夹即可。执行完成之后在/reached-snapshotname节点下新建子节点/reached-snapshotname/nodex,表示节点nodex完成snapshot工作。
-
abort阶段:如果在一定时间内/acquired-snapshotname节点个数没有满足条件(还有regionserver的准备工作没有完成),hmaster认为snapshot的准备工作超时。hmaster会新建另一种新的节点/abort-snapshotname,所有regionserver监听到这个命令之后会清理snapshot在临时文件夹中生成的结果。
可以看到,在这个系统中HMaster充当了协调者的角色,RegionServer充当了参与者的角色。HMaster和RegionServer之间的通信通过Zookeeper来完成,同时,事务状态也是记录在Zookeeper上的节点上。HMaster高可用情况下主HMaster宕机了,从HMaster切成主后根据Zookeeper上的状态可以决定事务是否继续提交或者abort。
参考: