Zookeeper 架构
首先简单介绍下 Zookeeper 集群,一个 Zookeeper 集群通常由一组机器组成,一般3~5台集群就可以组成一个 Zookeeper 集群。集群拓扑图基本如下:
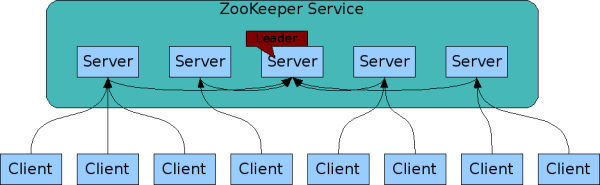
Zookeeper 集群中每一个节点都会在内存中维护当前的节点状态,并且彼此之间保持着通信
Leader
Leader 节点整个 Zookeeper 集群工作机制中的核心,主要工作是处理客户端的读写请求,及集群内部各服务的调度。注意只有 leader 能够处理写请求。
Follower
处理客户端的读请求;如果有写请求,则将写请求转发给 leader;参与 leader 选举投票等。
Zookeeper 数据模型
Zookeeper 的数据模型是一棵类似 Unix 文件系统的 ZNode Tree 即 ZNode 树,术语叫做 ZNode。ZNode 是 Zookeeper 存储数据的最小单元,每个 ZNode 可以保存数据,也可以挂载子节点,其中根节点是 /。示意图如下:
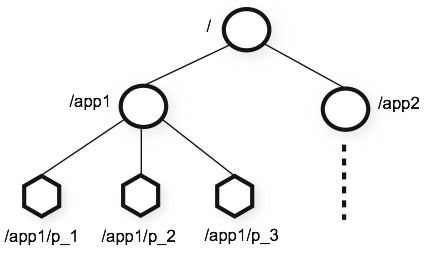
Zookeeper 主要提供了两个核心功能:
-
管理(存储、读取)客户端提交的数据;
-
为客户端提供ZNode的监听服务;
这里就涉及到 Zookeeper 的两个重要特性,就是它的 ZNode 模型与 Watcher 机制。
ZNode 模型
znode节点有4种类型:持久节点,临时节点,持久有序节点,临时有序节点
-
持久节点(PERSISTENT):客户端与 Zookeeper 断开会话后,该节点依旧存在,直到执行删除操作才会删除节点。
-
持久顺序节点(PERSISTENT_SEQUENTIAL):另一种持久节点,不同的是zookeeper会给该节点名称加上一个唯一单调递增的整数,也就是持久有序节点
-
临时节点(EPHEMERAL):节点的生命周期和客户端的会话绑定在一起,如果客户端崩溃了或者关闭了与 ZooKeeper的连接,这个节点就会被自动删除
-
临时顺序节点(EPHEMERAL_SEQUENTIAL):概念和上面类似,Zookeeper 也会给该节点进行顺序编号。
ZNode 除了存储用户数据外,还有以下特点:
-
包含 ZNode 修改/访问的时间、事务id(zxid),ACL 权限、版本等状态信息;
-
所有的事务请求在 ZNode 端都是顺序和原子性的;
-
数据主要存储在内存中,磁盘中保存事务日志、快照数据等;
Watcher 机制
Watcher 机制也称监听机制,它是 Zookeeper 的关键特性,是通过 ZooKeeper 实现分布式发布/订阅、分布式锁、集群管理等功能的基础。
ZooKeeper 客户端获得服务器的数据或者变化,不是通过轮询的模式,而是基于通知的机制,客户端向 ZooKeeper 服务器端注册需要监听的znode,如果被监听的znode发生了改变(比如节点被删除,节点数据发变更),则会通知客户端,需要强调的是这一个单次触发的操作。
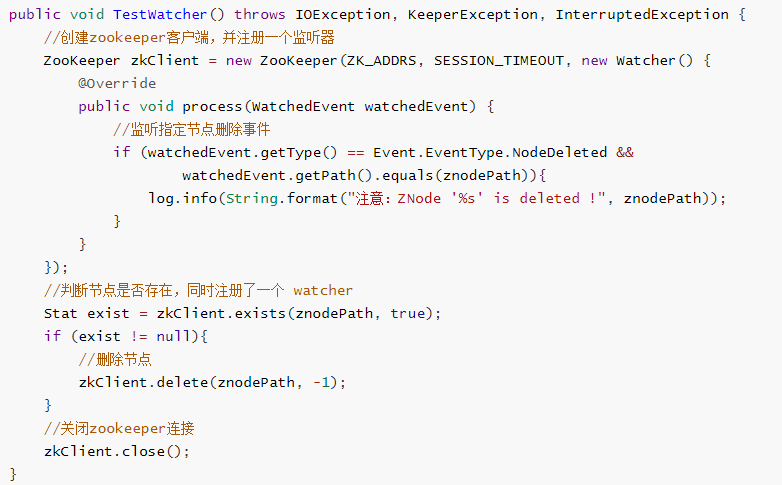
代码演示 Zookeeper 监听器
首先,当前有一个包含3个节点的 Zookeeper 集群,我们根据 Zookeeper 版本引入了相应依赖,如下

演示代码
-
创建 ZNode

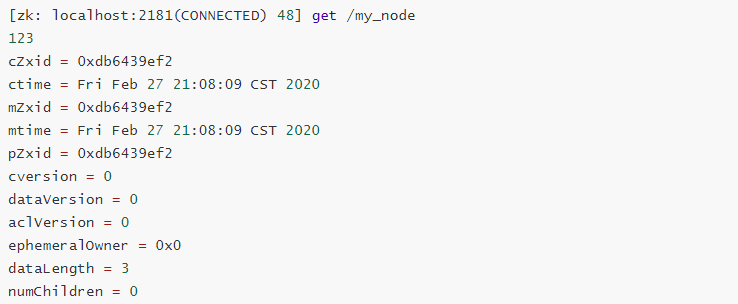
执行完这个单元测试后,我们通过命令行在服务端查看一下该数据节点:
-
删除 ZNode 节点,并监听该节点的删除动作
代码执行后,可以看到控制台打印出了znode被删除的日志:
再去服务端查看该节点,可以看到已经不存在了:

Zookeeper分布式锁的原理
Zookeeper分布式锁恰恰应用了临时顺序节点。具体如何实现呢?让我们来看一看详细步骤:
获取锁
首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端Client1想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下再创建一个临时顺序节点Lock2,Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态。
这时候,如果又有一个客户端Client3前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock3。Client3查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3是不是顺序最靠前的一个,结果同样发现节点Lock3并不是最小的。于是,Client3向排序仅比它靠前的节点Lock2注册Watcher,用于监听Lock2节点是否存在。这意味着Client3同样抢锁失败,进入了等待状态。
这样一来,Client1得到了锁,Client2监听了Lock1,Client3监听了Lock2
释放锁
释放锁分为两种情况:
1.任务完成,客户端显示释放
当任务完成时,Client1会显示调用删除节点Lock1的指令。
2.任务执行过程中,客户端崩溃
获得锁的Client1在任务执行过程中,如果发生了崩溃,则会断开与Zookeeper服务端的链接。根据临时节点的特性,与其相关联的节点Lock1会随之自动删除。
由于Client2一直在监听着Lock1节点,当Lock1节点被删除,Client2会立刻收到通知。这时候Client2会再次查询ParentLock下面的所有节点,确认自己创建的节点Lock2是不是目前最小的节点。如果是最小,则Client2顺理成章获得了锁。
同理,如果Client2也因为任务完成或者节点崩溃而删除了节点Lock2,那么Client3就会接到通知。
参考: