一、索引概述
索引是一种数据结构,
- 优势:相当于书籍目录,能提高查询速度,提升I/O效率,降低数据排序的时间
- 劣势:占用磁盘空间,很小可以忽略;影响数据更新操作,增删改等。
- 索引结构
默认b+tree(innodb引擎)
- 索引类型
- 单值索引:一个索引只包含一个列,一个表可以有多个单值索引:
- 唯一索引:列值必须唯一
- 复合索引:一个索引包含多列
- 索引语句
- 查看索引
show index from tablename;
- 创建索引
create index indexname on tablename(column_name);
- 删除索引
drop index indexname on tablename;
- 索引设计原则
- 查询操作,数据量大
- 使用where的字段,查询效率好
- 使用唯一索引,区分度越高,索引效率越高
- 索引不宜创建过多,一方面增加了某些字段的增删改,一方面增加了选择索引的时间
- 利用最左前缀N个列组合而成的组合索引,相当于创建了N个索引,如果查询时where子句中使用了组成该索引的前几个字段,那么这条sql使用了这个组合索引
二、性能检测
- 查看sql的执行频率
检测哪个sql需要性能提升,查看数据库的各操作的执行频次
show status like "Com_____";
查看innodb的增删改查操作的记录数
show status like 'Innodb_rows_%';
- explain分析执行计划
- explain值id,tablename等没有作用
- 重点explain之type,不通知代表查询的效率,下表展示了查询sql的扫面效率。如果type为ALL就必须考虑优化了,range基本满足要求了。
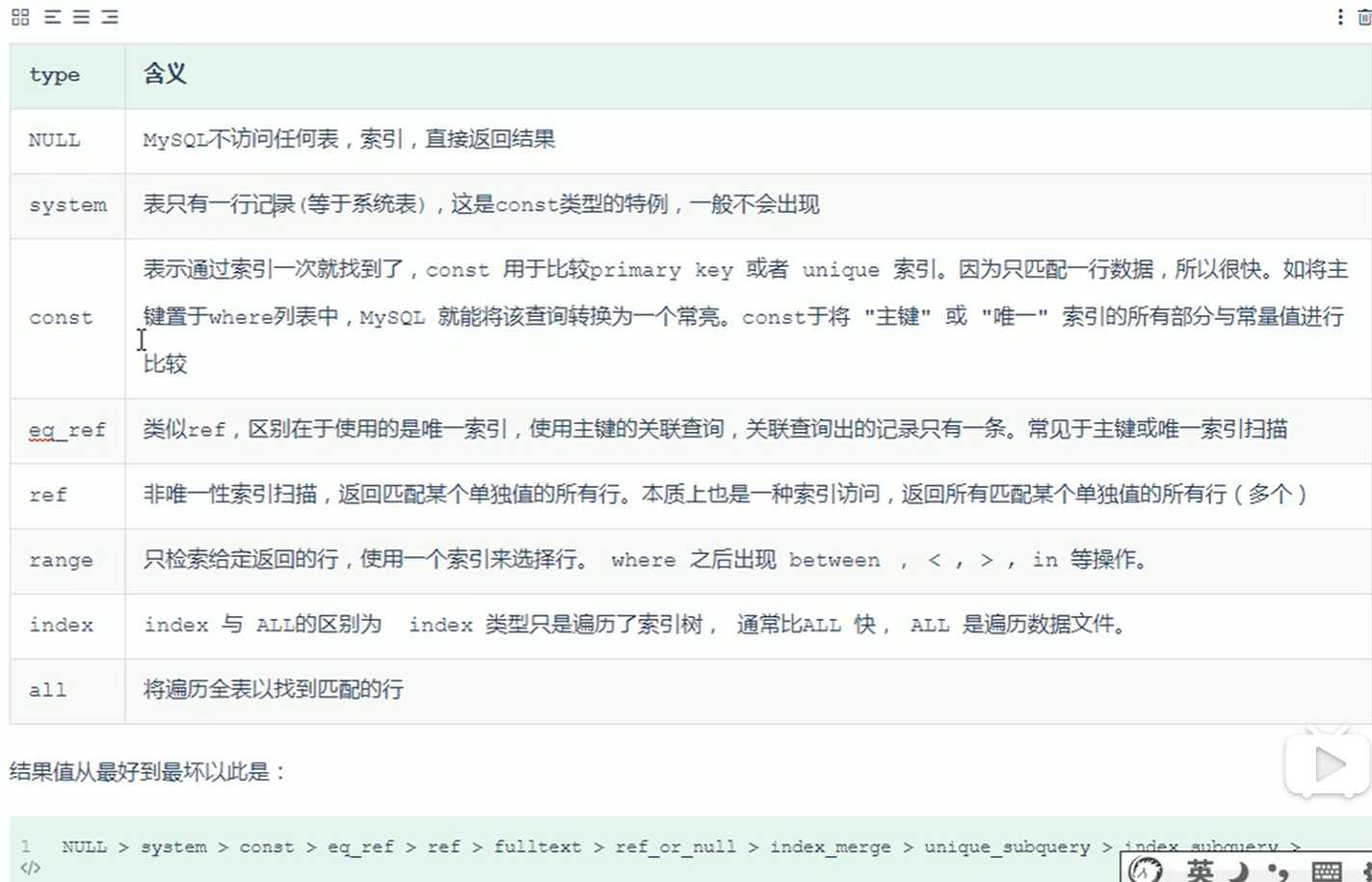
3.possible_key表示可能用到的key;key表示用到的key;key_length 表示kedy的长度;raws表示查询的行数,也可以大概反映查询的效率
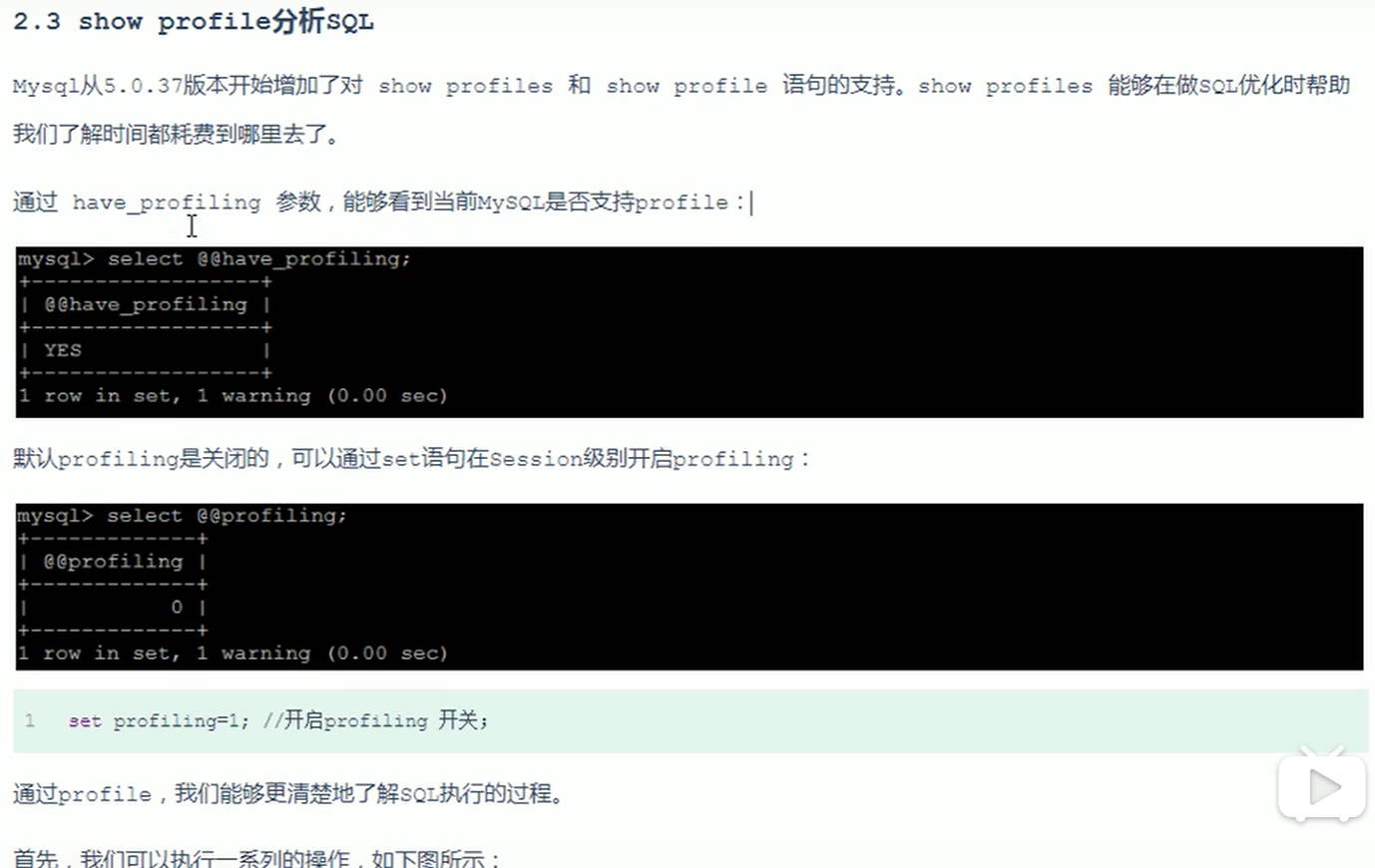
- show profile分析SQL
- have_profilling查看当前Mysql是否支持profile;
- set profilling =1;开启profile
- show profilling;可以直接查看前面的sql查询时间
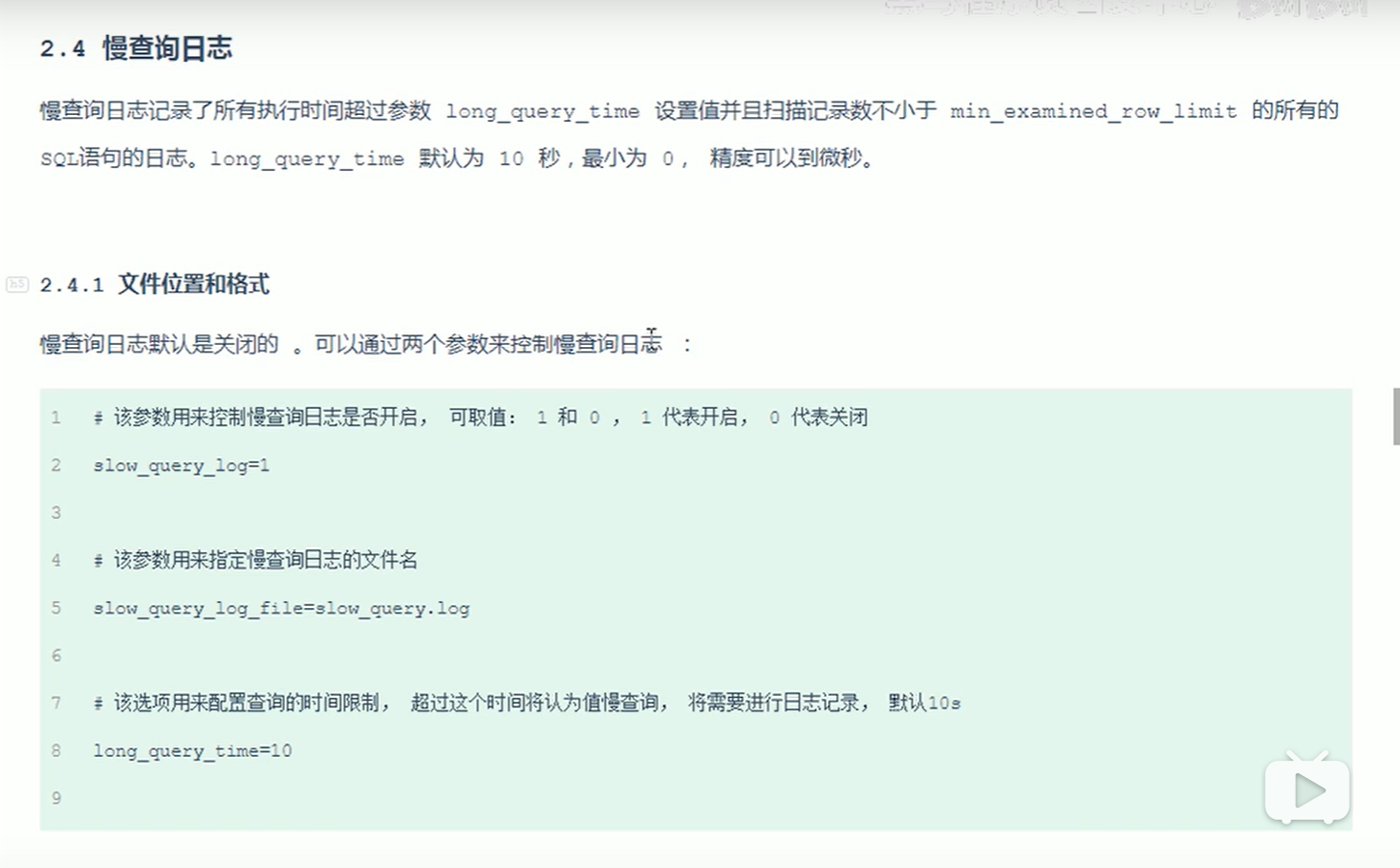
- 慢查询
三、索引的使用
- 最左前缀法则
当建立复合索引时,只有当查询时包含复合索引中最左侧的字段,才会走索引查询,即只要包含最左边的字段,都可使用索引查询,否则不会使用索引查。
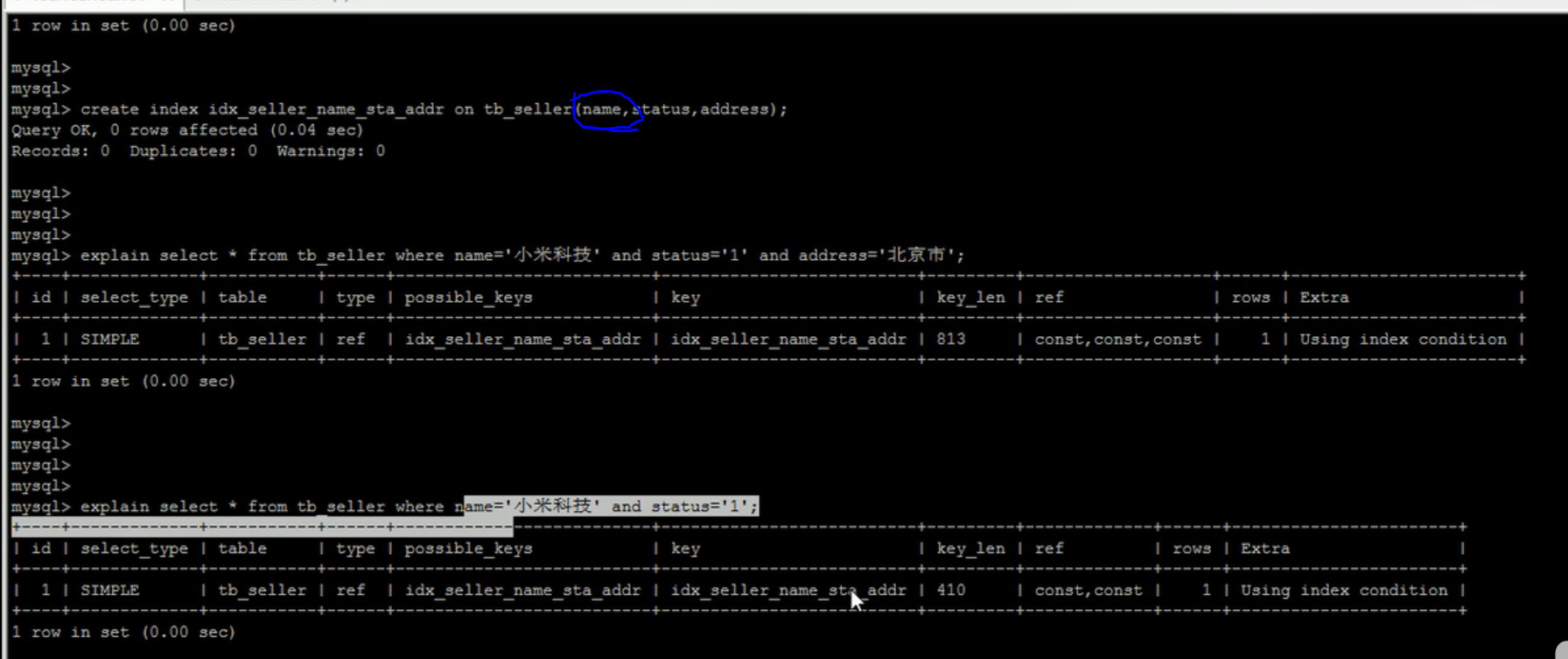
如,创建复合索引:
create index idx_seller_name_sta_addr on tb_seller(name,status,sddress);
只有当查询时where中包含name字段,才会走索引,否则一律非索引查询。当复合最左前缀索引时,但出现条约某一列,只有最左索引生效,并且索引顺序不影响查询结果
- 范围查询右边的列,不能使用索引
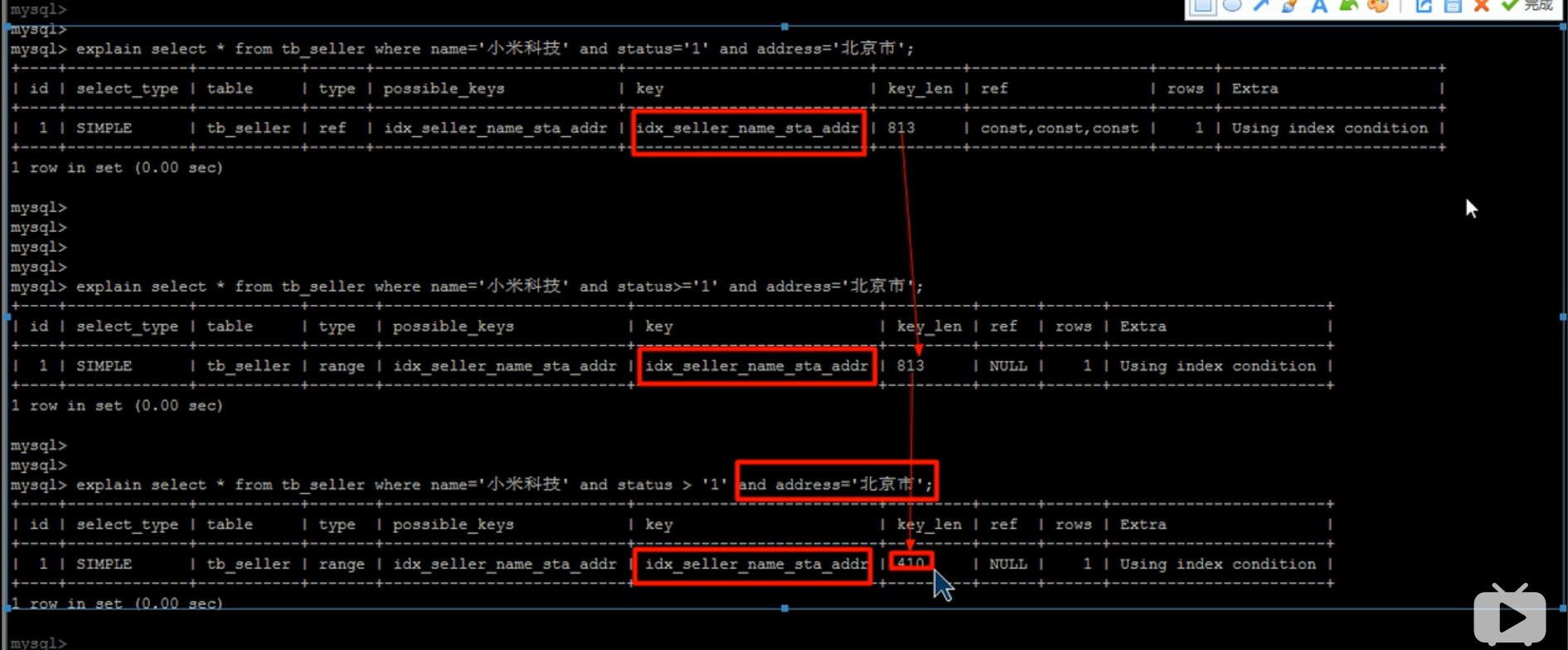
- 不要在索引列上进行算术运算,否则索引失效

-
字符串不加单引号,造成索引失效
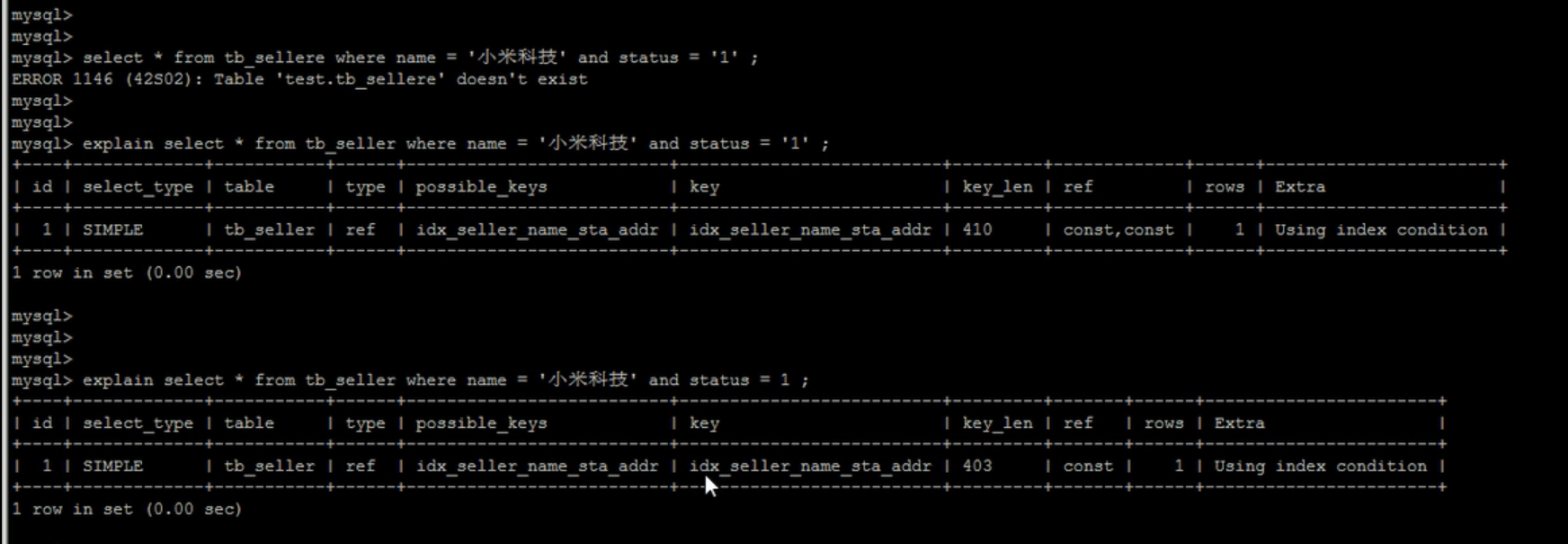
-
尽量使用覆盖索引,减少使用select *
其实就是,尽量返回索引包含的字段,当需要返回索引不包含的字段时,需要回表查,会降低性能

用or分割开的条件,如果or前的条件列有索引而后面列没有,那么索引失效,涉及到的索引不会被使用。
- 以%开头的like模糊查询,索引会失效。而%在最后则索引会生效

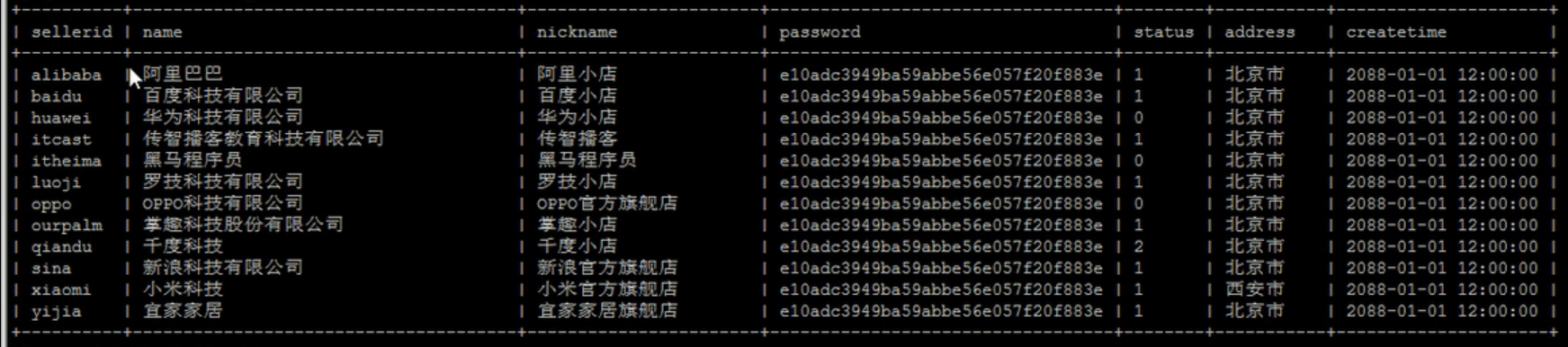
- 如果mysql评估使用索引比全表扫描慢,则不使用索引。
下面的北京市的数据几乎占了全部数据,西安市就一条数据,所以不如查北京市时,直接全表扫描,不用索引。而西安市会用索引

- is null 和is not null 有时索引会失效
- 原因同上,根据查询数据量的情况,mysql会自动判断是否使用索引
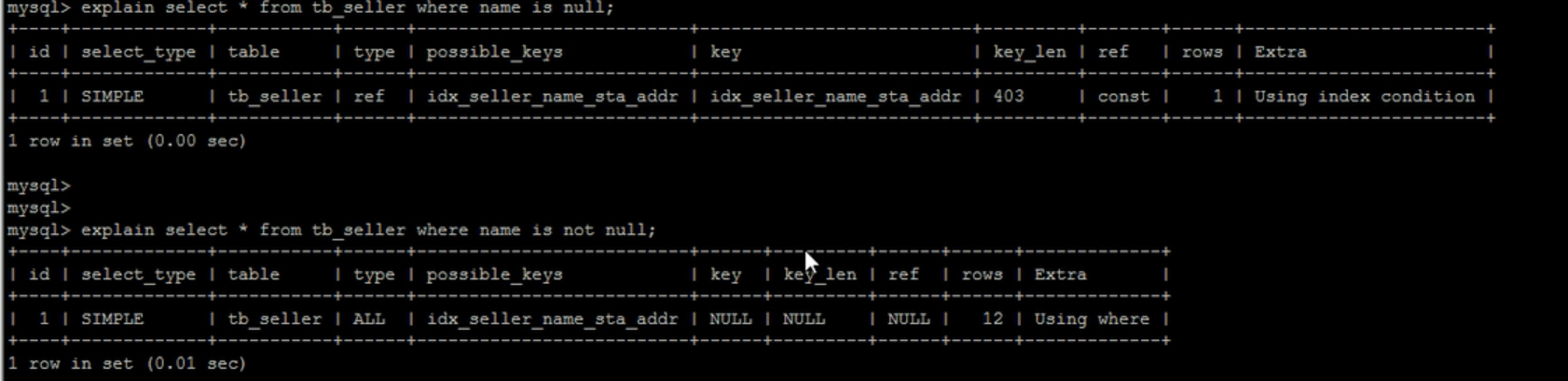
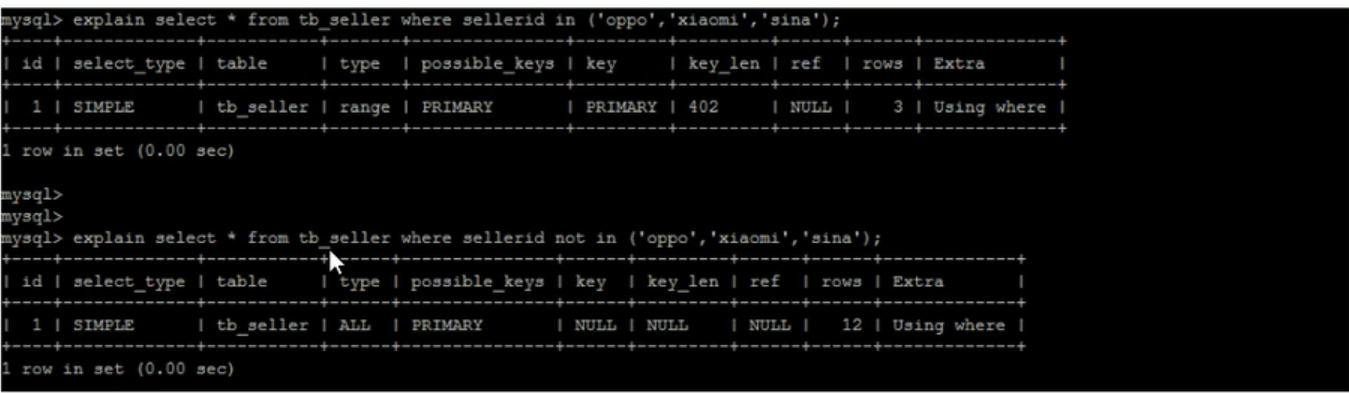
- in 走索引,not in 不走索引,同理
- 尽量创建复合索引,少创建单列索引
创建复合索引相当于创建了多个单列索引,这样使用查询的涵盖的情况更多一些
四、常见性能优化
- 优化insert语句


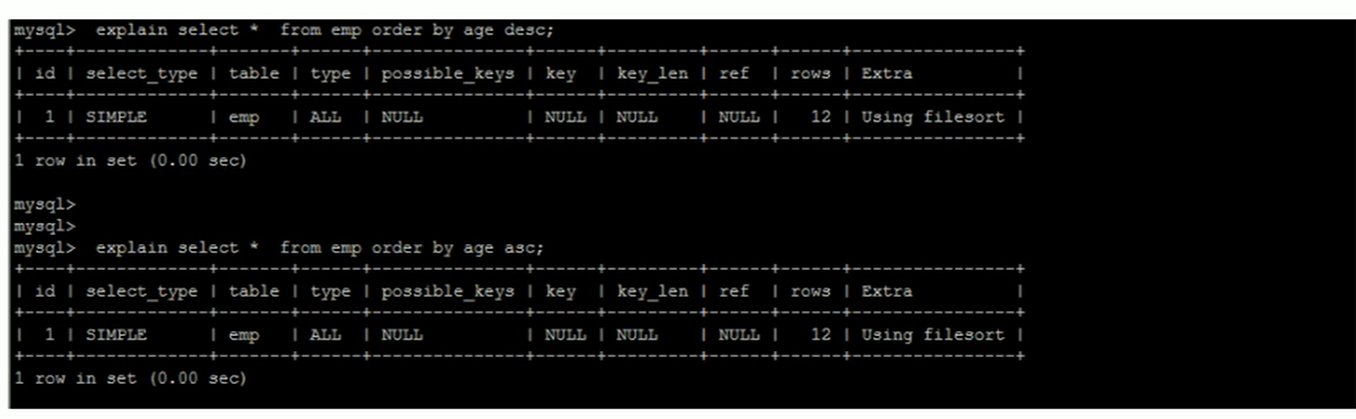
- 优化order by,两种排序方式,filesort和index
- 第一种时通过队返回数据进行排序,也就是filesort排序,所有不是通过索引直接返回排序结果的排序都是filesort排序。
这种查询结果中包含无索引的字段,就会出现索引失效情况,变成filesort排序。
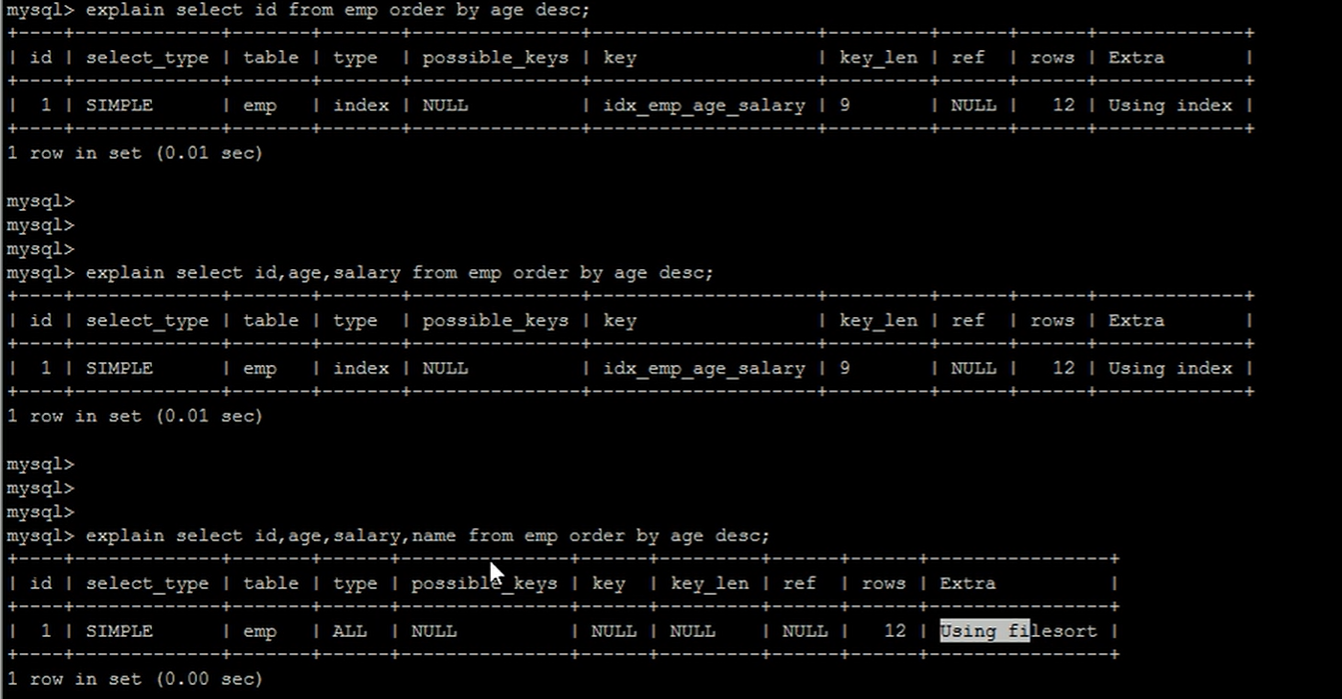
2.通过有序索引 排序,当需要排序时选择复合索引,并且排序字段和查询返回字段尽量使用有索引的字段。这样会使用索引提高效率。
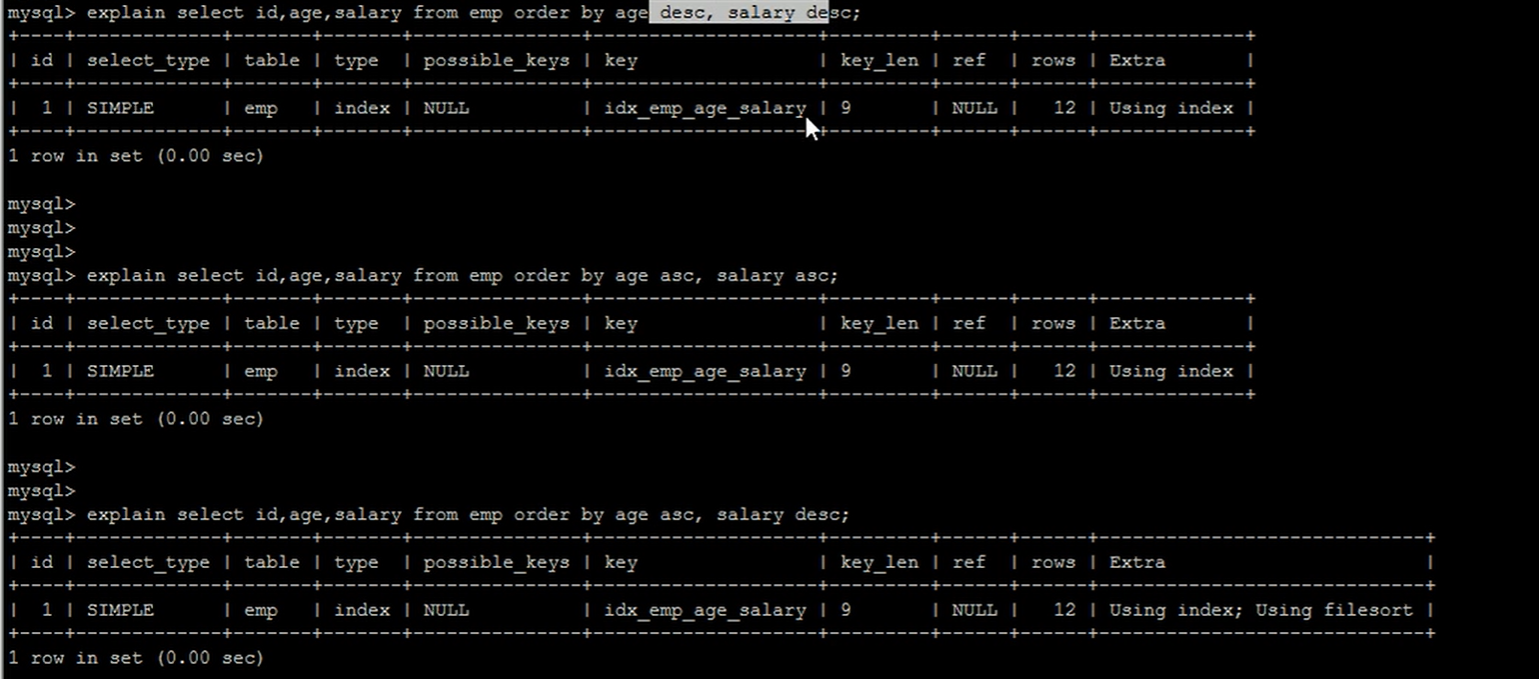
对于多字段排序,尽量同时使用升序或者降序,这样效率会高些。如果一个升序一个降序,可能只有一个排序字段索引有效,另外一个字段索引无效。
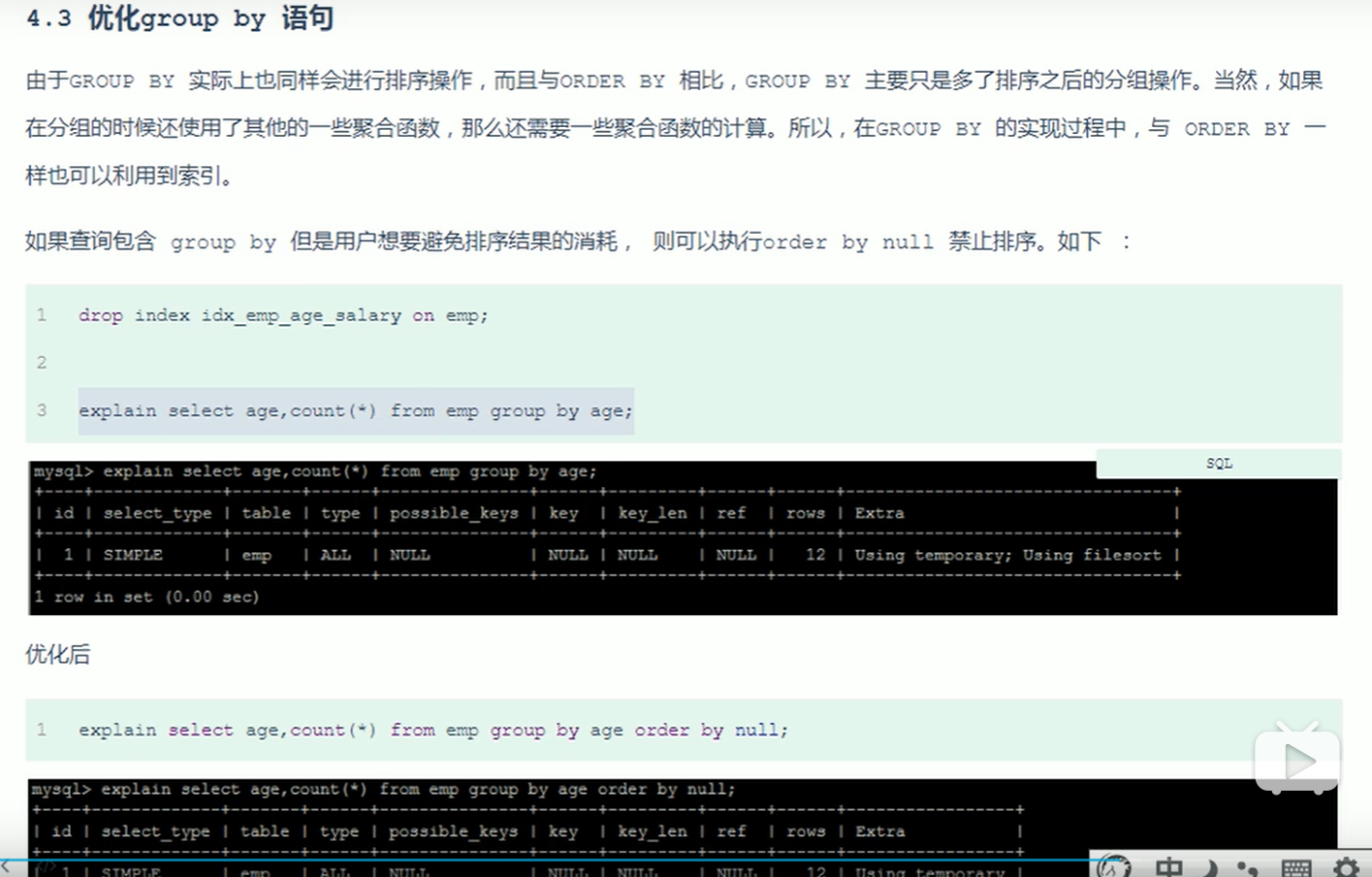
- 优化分组group by
- 分组时不需要排序可以去掉排序过程,提高性能。在group by 后加 order by null
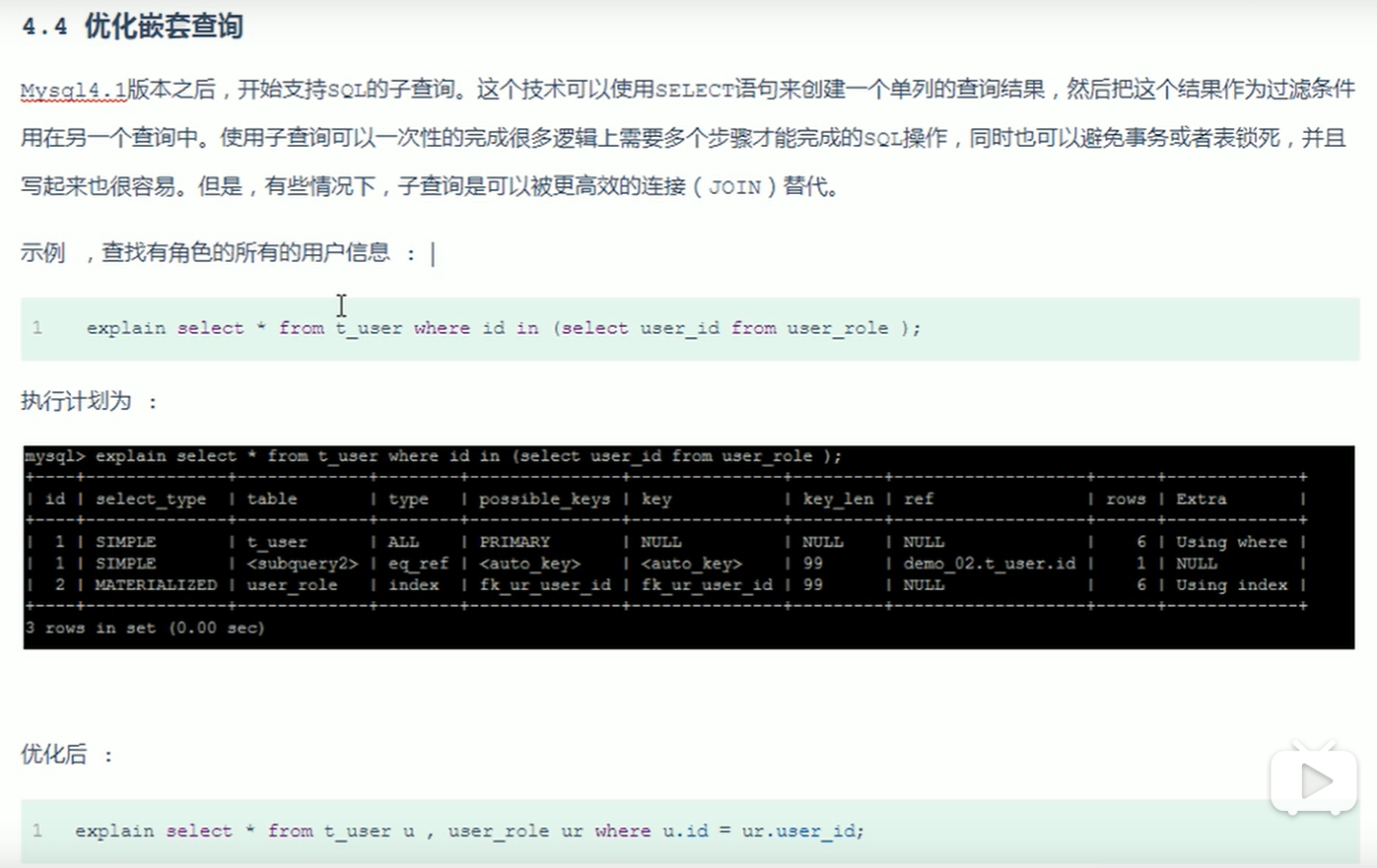
2.嵌套查询优化 ,减少嵌套查询,可以使用一些连接查询
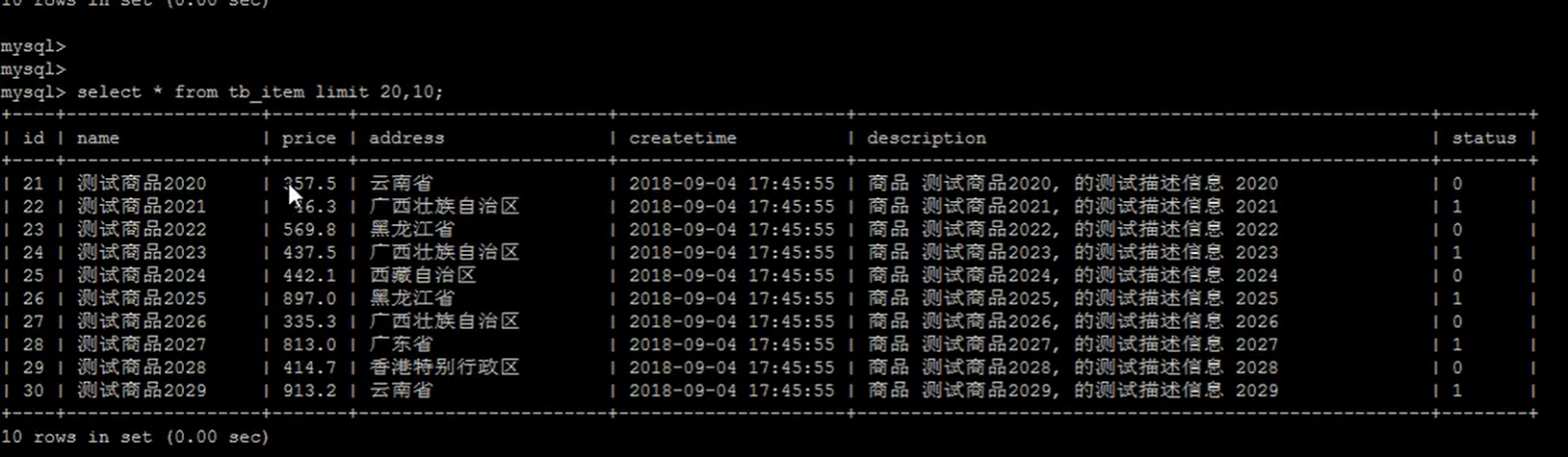
- 优化分页查询
下面的普通的分页查询是全表查,用不上索引;但是用优化方案,通过主键索引返回相关数据id,这里用上了索引,再连表查询相关信息。这样就提升了分页查询的速度。但是数据量大情况下,性能提升有限。

-
数据量越大,查询的分页数据越多,越慢,针对这样的查询可以使用分页优化查询
摘自:两小时拿下MySQL优化 记录一下,学习使用。