详细参考文档:https://www.cnblogs.com/Zhi-Z/p/8728168.html
https://zhuanlan.zhihu.com/p/104917232
数据挖掘、机器学习和推荐系统中的评测指标——准确率precision、召回率(Recall)、F值(F-Measure)
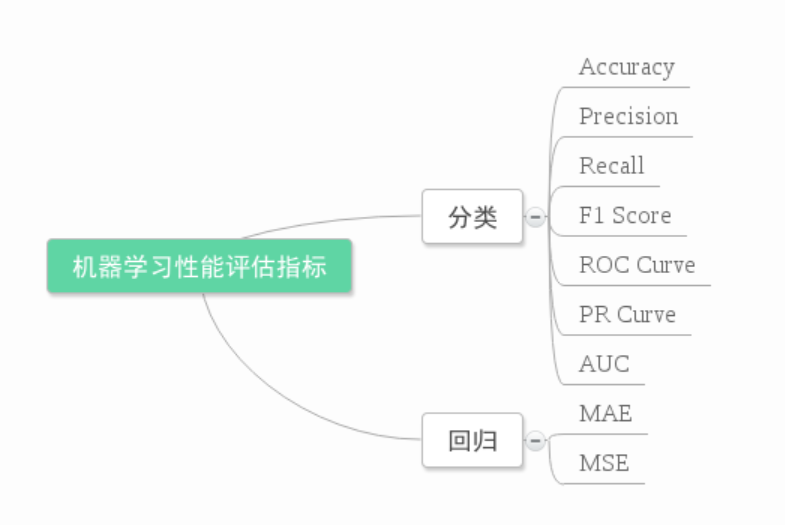
不同机器学习算法的评价指标也不一样,如下图所示:
本文针对二元分类器对几个常用的性能评估指标进行介绍
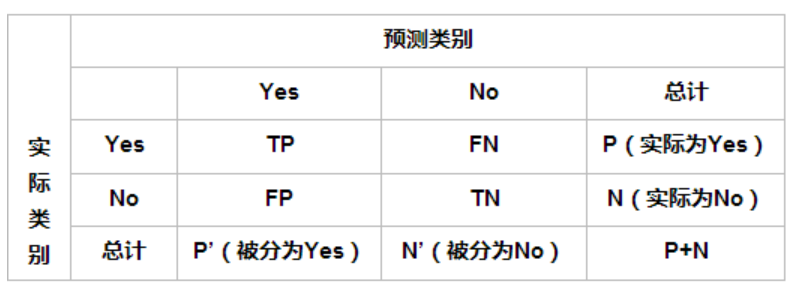
- 混淆矩阵
False Positive (假正, FP):将负类预测为正类数---->误报
False Negative(假负,FN):将正类预测为负类数---->漏报

- 准确率(Accuracy)
计算公式:
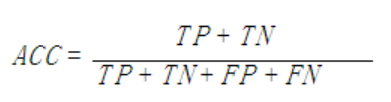
被分对的样本数除以所有的样本数,通常来说正确率越高,分类器越好。但是在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷,所以单纯靠准确率来评价一个算法模型是远远不够的。
2. 错误率(Error rate)
错误率则与准确率相反,描述被分类器错分的比例,accuracy = 1-error rate
3. 灵敏度(sensitive)
sensitive = TP/P, 表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
4. 特效度(specificity)
specificity= TN/N 表示是所有负例中被分对的比例,衡量了分类器对负例的识别能力
5、精确率、精度(precision)
精确率(precision):表示被分为正例的示例中实际为正例的比例
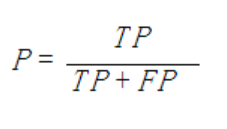
6、召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,与灵敏度一样recall = TP/(TP+FN) = TP/P
7、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(F-score)

8、 其他评价指标
计算速度:分类器训练和预测需要时间
鲁棒性: 处理缺失值和异常值的能力
可扩展性: 处理大数据集的能力
可解释性: 分类器的预测标准的可理解性
9、PR曲线和ROC曲线
TPR真正率=TP/(TP+FN) 指实际正样本中真正被预测为正样本的概率
FPR假正率=FP/(FP+TN) 指实际负样本中错误被预测为正样本的概率
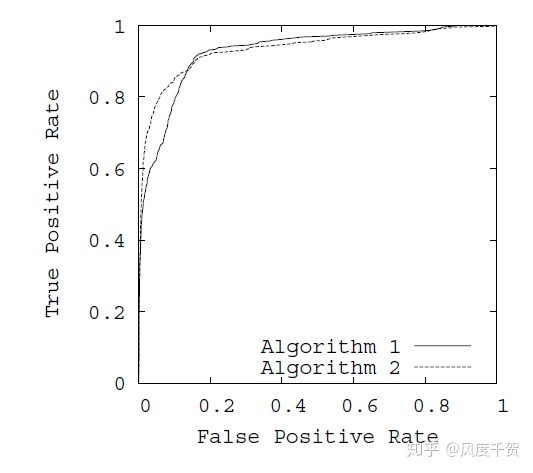
在ROC曲线中,以FPR为x轴,TPR为y轴,如下图所示:
在PR曲线中,以Recall(貌似翻译为召回率或者查全率)为X轴,Precision为y轴。Recall指的是所有正样本中被识别成正样本的概率等于TPR。而Precision指正确分类的正样本数占总的被分类成正样本的比例(被分成正样本例中实际为正样本的概率)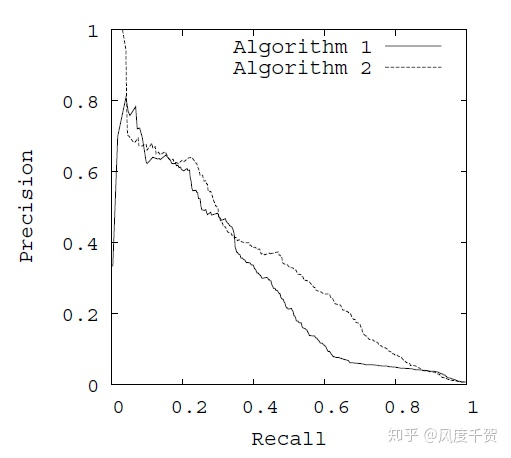
如何绘制ROC曲线和PR曲线,预测效果如下图所示:
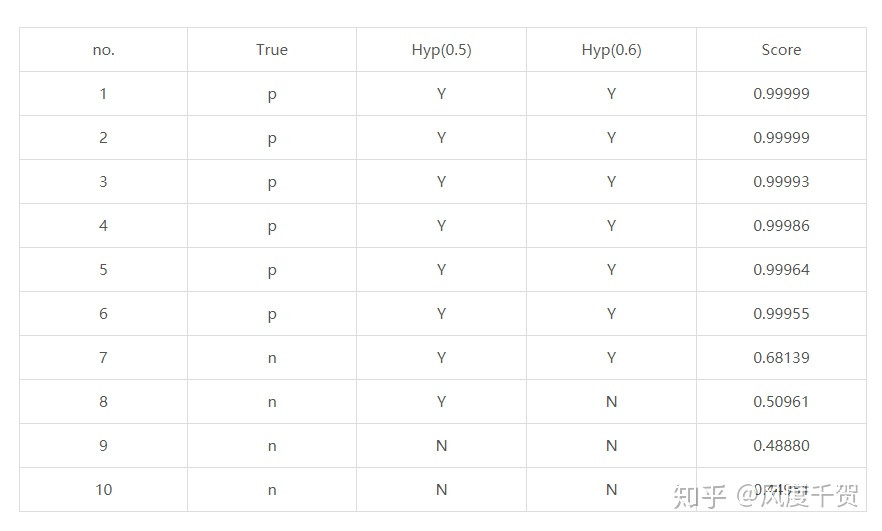
no那一栏是样本号,True是样本实际的属性(P/N),Hyp(x)是在x阈值下该样本被预测的属性(Y/N),Score是得分,通常分类器输出的都是score,如SVM,神经网络等。
当阈值x=0.5时,可以根据样本实际/预测属性算出TPR和FPR即可得到ROC的一个坐标(FPR,TPR),不同的阈值(给定数据集中)/不同参数的模型都有不同的ROC值,每次训练一段时间都需要进行测试,每次测试的ROC坐标即可绘制出ROC曲线,观察算法的性能。
在ROC空间,ROC曲线越凸向左上方向效果越好。与ROC曲线左上凸不同的是,PR曲线是右上凸效果越好。ROC和PR曲线都被用于评估机器学习算法对一个给定数据集的分类性能,每个数据集都包含固定数目的正样本和负样本。

Recall----x轴,Precision----y轴 构成PR曲线; False Positive Rate------x轴,True Positive Rate-----y轴 构成 ROC曲线;
在给定数目的正负样本数据集中,ROC和PR曲线存在一一对应关系,当正负样本差距不大时,ROC和PR的趋势差不多,但是当负样本很多时,两者差异较大,ROC效果依然很好,但是PR反映效果一般。
10、 AUC
AUC(Area Under Curve)指的是曲线下面积占总方格的比例,当不同分类算法的ROC曲线存在交叉,很多时候可以用AUC值作为算法好坏的评判标准,面积越大,表示分类性能越好,跟左上角方向凸和右上角方向凸的评判标准一个道理。