数据库设计理论范式,粘贴过来的:
什么是范式:简言之就是,数据库设计对数据的存储性能,还有开发人员对数据的操作都有莫大的关系。所以建立科学的,规范的的数据库是需要满足一些
规范的来优化数据数据存储方式。在关系型数据库中这些规范就可以称为范式。
什么是三大范式:
第一范式:当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。满足第一范式是关系模式规范化的最低要
求,否则,将有很多基本操作在这样的关系模式中实现不了。
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF.
注:关系实质上是一张二维表,其中每一行是一个元组,每一列是一个属性
自己的理解:
第一范式
保证每一列的原子性,不能再拆分多列;
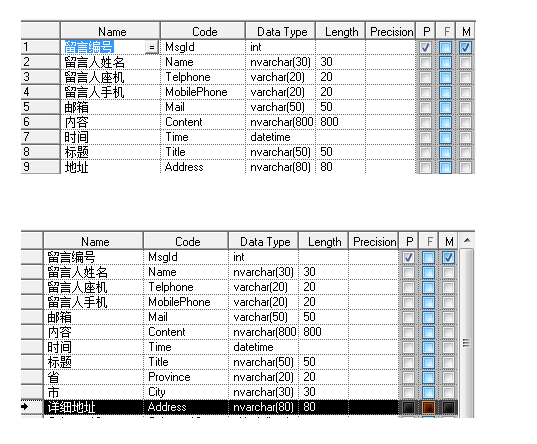
第一个表中,如果地址是按照省市区分查询,则不能满足需求;
第二范式
满足1NF后,要求表中的所有列,都必须依赖于主键,而不能有任何一列与主键没有关系,也就是说一个表只描述一件事情,不产生冗余数据;

上图为酒店订单表,后面的联系人信息和订单是没有直接关联的,如果某个人同时订了10个房间,则联系人相关数据则会大量重复,可以把所有用户存储为一个表,这个订房表中只保存联系人的唯一id关联;
第三范式
个人感觉第二和第三范式有点重复的意思,第三范式和第二范式正好相反,拆分出来的表关联中只能有其他表的唯一主键,不能存在其他不相关的列;
如上图拆分出来两个表后,订单表中只能有客户的主键id,想查询客户信息则只能去客户表中查询信息;
简述三大范式区别
第一范式和第二范式在于有没有分出两张表,第二范式是说一张表中包含了所种不同的实体属性,那么要必须分成多张表, 第三范式是要求已经分成了多张表,那么一张表中只能有另一张表中的id(主键),而不能有其他的任何信息(其他的信息一律用主键在另一表查询)。
数据库的五大约束:
1.primary KEY:设置主键约束;
2.UNIQUE:设置唯一性约束,不能有重复值;
3.DEFAULT 默认值约束,height DOUBLE(3,2)DEFAULT 1.2 height不输入是默认为1,2
4.NOT NULL:设置非空约束,该字段不能为空;
5.FOREIGN key :设置外键约束。