资料来源:
《集体智慧编程》&网络
一.推荐系统 概述
定义
维基百科定义:
推荐系统属于资讯过滤的一种应用。
推荐系统能够将可能受喜好的资讯或实物(例如:电影、电视节目、音乐、书籍、新闻、图片、网页)推荐给使用者。
形成过程
随着互联网的发展,人们正处于一个信息爆炸的时代。相比于过去的信息匮乏,面对现阶段海量的信息数据,对信息的筛选和过滤成为了衡量一个系统好坏的重要指标。一个具有良好用户体验的系统,会将海量信息进行筛选、过滤,将用户最关注最感兴趣的信息展现在用户面前。这大大增加了系统工作的效率,也节省了用户筛选信息的时间。
搜索引擎的出现在一定程度上解决了信息筛选问题,但还远远不够。搜索引擎需要用户主动提供关键词来对海量信息进行筛选。当用户无法准确描述自己的需求时,搜索引擎的筛选效果将大打折扣,而用户将自己的需求和意图转化成关键词的过程本身就是一个并不轻松的过程。
在此背景下,推荐系统出现了,推荐系统的任务就是解决上述的问题,联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对他感兴趣的人群中,从而实现信息提供商与用户的双赢。
例子
接着以亚马逊(http://www.amazon.cn/)为例,让大家对推荐系统有一个初步的印象。
在亚马逊用自己的账号登录以后,主页会根据你浏览过的商品进行推荐。

随意进入一本书的链接,里边还会推荐看过该商品以后其它顾客买了什么。

协作型过滤
一个协作型过滤算法通常的做法是对一大群人进行搜索,并从中找出与我们品味相近的一小群人。
算法对这些人所偏爱的其它内容进行考察,并将它们组合起来构造出一个经过排名的推荐列表。
一.一个影评推荐例子
(一)搜集偏好
我们要做的第一件事情,就是寻找一种表达不同人及其偏好的方法。在python中,达到这一目的的一种非常简单的方法是使用一个嵌套的字典。
大概格式为:评价 = {评价者名称:{电影名称:评分},评价者名称:{电影名称:评分}}
新建一个名为recommendations.py的文件,并加入以下代码
########要做的第一件事就是寻找一种表达不同人及其偏好的方法,可以用嵌套的字典构造一个数据集:
critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5, 'The Night Listener': 3.0},'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0, 'You, Me and Dupree': 3.5}, 'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,'Superman Returns': 3.5, 'The Night Listener': 4.0},'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,'The Night Listener': 4.5, 'Superman Returns': 4.0, 'You, Me and Dupree': 2.5},'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0,'You, Me and Dupree': 2.0}, 'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}}
启动python的交互式环境(我用的是python 2.7.11 Shell),可以开始输入代码查询用户的偏好了
在python用import或者from...import来导入相应的模块。模块其实就一些函数和类的集合文件,它能实现一些相应的功能,当我们需要使用这些功能的时候,直接把相应的模块导入到我们的程序中,我们就可以使用了。
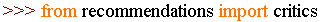
假如我们想查询某个用户对所有影片的评分,在本例中,相当于查询字典critics中相应用户的key的value值。

假如我们想知道某个用户对某个影片的评分,就需要找到这个用户名所对应的字典的key下的value,因为在这里用的是嵌套的字典,也就是说第一层字典的value也是一个字典,我们暂且称之为“字典中的字典”,我们需要的,是“字典中的字典”中相应影片名对应的key的value值,也即该用户对该影片的评分。
举个例子,要查询用户Lisa Rose对影片Lady in the Water的评分,我们可以输入以下代码并获得相应的评分。

(二)寻找相近的客户
搜集完人们的偏好数据之后,我们需要有一种方法来确定人们在品味方面的相似程度。
为此,我们可以将每个人与所有其他人进行对比,并进行他们的相似度评价值。
1.欧几里得距离评价
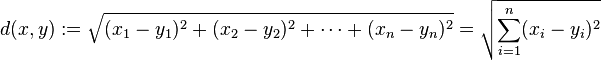
计算相似度评价值的一个非常简单的方法是使用欧几里得距离评价方法。
它以人们一直评价的物品为坐标轴,然后将参与评价的人绘制到图上,并考察他们彼此距离远近。

为了计算图上Toby和LaSalle之间的距离,我们可以按照上上图的公式进行计算,在交互式环境中用以下代码进行计算。
p.s.坐标Toby(1,4.5),LaSalle(2,4)

偏好越相似的人,其距离就越短,但是为了使得偏好越相近得到一个越大的值,同时为了让函数总是返回介于0~1之间的值,对公式进行一些加工,新的相似度公式为 1/(1+欧氏距离),分母加1是为了避免分母为0的情况出现,如果返回1,则表示两人具有一样的偏好。

我们将上述只是结合起来,就可以构造出一个计算相似度的公式了。
构造一个sim_distance函数以返回根据欧式距离计算出来的相似度公式,代码思路如下(以影评数据为例):
遍历person1评价过的电影,如果person2也评价过这个电影,把他俩都评价过的电影加入字典si,如果他俩没有同样评价的电影,返回0。
#######寻找相近的用户:欧几里得距离评价 from math import sqrt #返回一个有关person1和person2的基于欧式距离的相似度评价 def sim_distance(prefs,person1,person2): si={} #建立空字典si for item in prefs[person1]: #遍历person1看过的电影(item) if item in prefs[person2]: #如果person1看过的电影(item)也包含在person2的字典里 si[item]=1 #把person1和person2共同看过的电影名称填入空字典si if len(si)==0: return 0 #如果person1和person2没有共同看过的影片,则返回0 #计算相似度 sum_of_squares=sum([pow(prefs[person1][item]-prefs[person2][item],2) for item in prefs[person1] if item in prefs[person2]]) return 1/(1+sum_of_squares)
2.皮尔逊相关度评价

代码思路同上,只是最后的计算公式换了
######寻找相近的用户:皮尔逊相关度评价 ##返回p1和p2的皮尔逊相关系数 def sim_pearson(prefs,p1,p2): si={} #建立空字典si #得到双方都评价过的物品 for item in prefs[p1]: if item in prefs[p2]: si[item]=1 # 如果没有共同评价过得物品,则返回0 if len(si)==0: return 0 n=len(si) #Python 字典(Dictionary) len() 函数计算字典元素个数,即键的总数。 #计算过程 sum1=sum([prefs[p1][it] for it in si]) sum2=sum([prefs[p2][it] for it in si]) sum1Sq=sum([pow(prefs[p1][it],2) for it in si]) sum2Sq=sum([pow(prefs[p2][it],2) for it in si]) pSum=sum([prefs[p1][it]*prefs[p2][it] for it in si]) num=pSum-(sum1*sum2/n) den=sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n)) if den==0: return 0 r=num/den return r
(三)为评价者打分
根据指定人员对每个人进行打分。
def topMatches(prefs,person,n=5,similarity=sim_pearson): #参数n为返回的人数,默认为5;similarity为相似度评价方法,默认为皮尔逊相关度评价 scores=[(similarity(prefs,person,other),other) for other in prefs if other!=person] #列表推导式:scores=[(相似度,要对比的人名)] #for other in prefs if other!=person 意思为遍历prefs中和person不同的元素 scores.sort() #排序,sort为从低分到高分排序 scores.reverse() #转置一下让scores从高分到低分排序 return scores[0:n] #返回前n名
(四)推荐物品
代码思路书里写得很清楚啦P16最下边
# ##########推荐物品 # 利用所有他人评价值的加权平均,为某人提供建议 def getRecommendations(prefs,person,similarity=sim_pearson): ##相似度默认为皮尔逊相关度,可以改 totals={} simSums={} #####循环遍历位于字典prefs中的其他人,计算person和其它人的相似度 #以防出现自己和自己比较 for other in prefs: if other==person: continue #continue:跳出本次循环; break:跳出整个for循环 sim=similarity(prefs,person,other) ##相似度,遍历到一个人得到该人和person的相似度 if sim<=0: continue #忽略评价值为0或为负数的情况 for item in prefs[other]: if item not in prefs[person] or prefs[person][item]==0: # #此时item为other评价过而person没评价过的电影名称 totals.setdefault(item,0) ##此时totals={影片:0,影片:0,...} totals[item]+=prefs[other][item]*sim ##相当于totals[item]=totals[item]+prefs[other][item]*sim #此时totals={影片:评价值*相似度,影片:评价值*相似度,...} #totals[item]=评价值*相似度求和 simSums.setdefault(item,0) #此时simSums={影片:0,影片:0,...} simSums[item]+=sim #simSums[item]=相似度求和 #建立一个归一化列表 rankings=[(total/simSums[item],item) for item,total in totals.items()] ##此刻rankings=[(加权后的评价值,影片),...] #返回经过排序的列表 rankings.sort() rankings.reverse() return rankings ##返回从高分到低分排序的rankings #可以得到一个经过排名的影片列表,同时还可以推测出自己对每部影片评分的情况
(五)匹配商品
比较简单
############匹配商品(和之前用来决定人与人之间的相似度的方法是一样的,只需要将人员与物品对换即可) #人员和物品的对换代码: ##将人和物品对调,把{人:{影片:评分}}转为{影片{人:评分}} def transformPrefs(prefs): result={} for person in prefs: for item in prefs[person]: result.setdefault(item,{}) #将物品和人员对调 result[item][person]=prefs[person][item] return result
(六)构造物品比较数据集
##为了对物品进行比较,我们要做到的第一件事就是编写一个函数,构造一个包含相近物品的完整数据集 def calculateSimilarItems(prefs,n=10): #建立字典,以给出与这些物品最为相近的所有其他物品 result={} #建立空字典result itemPrefs=transformPrefs(prefs)# 以物品为中心对偏好矩阵实施倒置处理 c=0 #赋初值 for item in itemPrefs: #遍历每项物品 # 针对大数据集更新状态变量 c+=1 if c%100==0: print "%d / %d" % (c,len(itemPrefs)) #c%100==0 :取模,c除以100的余数 #寻找最为相近的物品 scores=topMatches(itemPrefs,item,n=n,similarity=sim_distance) result[item]=scores #往空字典result填入数据,key为item,value为scores return result
(七)获得推荐
#######获得推荐 #我们可以取到用户评价过的所有物品,找出其相近物品,并根据相似度对其进行加权。 def getRecommendedItems(prefs,itemMatch,user): userRatings=prefs[user] #得到用户评价过的物品 scores={} totalSim={} #循环遍历由当前用户评分的物品 for (item,rating) in userRatings.items( ): # 循环遍历与当前物品相近的物品 for (similarity,item2) in itemMatch[item]: # 如果该用户已经对当前物品做过评价,则将其忽略 if item2 in userRatings: continue # 评价值与相似度的加权之和 scores.setdefault(item2,0) scores[item2]+=similarity*rating #全部相似度之和 totalSim.setdefault(item2,0) totalSim[item2]+=similarity # 将每个合计值除以加权和,求出平均值 rankings=[(score/totalSim[item],item) for item,score in scores.items( )] # 排序 rankings.sort( ) rankings.reverse( ) return rankings
二.构建一个基于delicious的链接推荐系统
这儿需要安装pydelicious,安装pydelicious前需要安装feedparser,安装feedparser还好,pip install即可,然而安装pydelicious略曲折。
懒人方法在我的电脑上全都不适用,pip install报错,easy_install也报错,最后只好上网安装了个包然后python setup.py install23333,还好最后解决了。ps.需要pydelicious安装包的同学可以找我要~

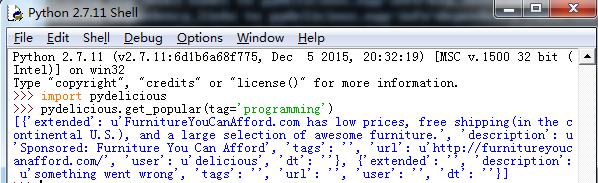
基本导入
from pydelicious import get_popular,get_userposts,get_urlposts import time
(一)构造数据集
找到一组近期提交过某一热门链接,且连接附带指定标签(tag)的用户。
def initializeUserDict(tag,count=5): user_dict={} #建立空字典user_dict for p1 in get_popular(tag=tag)[0:count]: #此时p1为前count个最受欢迎的链接的张贴记录 #get_popular得到一个包含字典的列表,包含URL、描述、提交者;
#get_userposts返回给定用户的所有张贴记录
#get_urlposts返回给定URL的所有张贴记录
for p2 in get_urlposts(p1['href']): #貌似'href'现在应该改为'url' #get_urlposts返回给定url的所有张贴记录 user=p2['user'] user_dict[user]={} return user_dict #返回一个包含若干用户数据的字典,其中每一项都各自指定向一个等待填入具体链接的空字典 #count默认值为5,所以上述函数值搜集了前五个链接相对应的用户数据
##利用API来建立一个填充所有用户评价值的函数(0:用户没有张贴这一链接;1:用户张贴了这一链接。) def fillItems(user_dict): all_items={} # 查找所有用户都提交过的链接 for user in user_dict: for i in range(3): try: posts=get_userposts(user) #posts=user_dict中每个user的张贴记录 break #跳出所有循环 except: print "Failed user "+user+", retrying" #异常处理,记录没有爬到的user time.sleep(4) for post in posts: url=post['href'] #获得url user_dict[user][url]=1.0 #如果有url张贴记录,赋值1 all_items[url]=1 #填充空字典all_items,key=url,value=1 #用0填充缺失的项 for ratings in user_dict.values(): for item in all_items: if item not in ratings: ratings[item]=0.0
三.使用MovieLens数据集
#########使用MovieLens数据集(涉及电影评价的真实数据集) def loadMovieLens(path='/data/movielens'): # Get movie titles movies={} for line in open(path+'/u.item'): #u.item包含一组有关影片ID和片名的列表 (id,title)=line.split('|')[0:2] movies[id]=title # 加载数据 prefs={} for line in open(path+'/u.data'): #u.data包含实际评价情况(P26) (user,movieid,rating,ts)=line.split(' ') prefs.setdefault(user,{}) prefs[user][movies[movieid]]=float(rating) #float(x ) 将x转换到一个浮点数 return prefs