在配置kafka和storm的时候, 经常的会出现一些问题, 主要在以下几个:
1. 打jar包上去storm集群的时候会出现jar包冲突,类似于log4j或者sf4j的报错信息.
2. kafka本地Java生产者和消费者无法消费数据
3. kafkaSpout的declareFields到底是什么
下面我们结合kafka_2.11-0.10.1.0 + apache-storm-1.1.0来详细的说明这三个问题.
1. 打jar包上去storm集群的时候会出现jar包冲突,类似于log4j或者sf4j的报错信息.
SLF4J: Detected both log4j-over-slf4j.jar AND slf4j-log4j12.jar on the class path, preempting StackOverflowError. SLF4J: See also http://www.slf4j.org/codes.html#log4jDelegationLoop for more details. |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
5370 [Thread-14-newKafka] ERROR backtype.storm.util - Async loop died!java.lang.NoClassDefFoundError: Could not initialize class org.apache.log4j.Log4jLoggerFactory at org.apache.log4j.Logger.getLogger(Logger.java:39) ~[log4j-over-slf4j-1.6.6.jar:1.6.6] at kafka.utils.Logging$class.logger(Logging.scala:24) ~[kafka_2.10-0.8.2.1.jar:na] at kafka.consumer.SimpleConsumer.logger$lzycompute(SimpleConsumer.scala:30) ~[kafka_2.10-0.8.2.1.jar:na] at kafka.consumer.SimpleConsumer.logger(SimpleConsumer.scala:30) ~[kafka_2.10-0.8.2.1.jar:na] at kafka.utils.Logging$class.info(Logging.scala:67) ~[kafka_2.10-0.8.2.1.jar:na] at kafka.consumer.SimpleConsumer.info(SimpleConsumer.scala:30) ~[kafka_2.10-0.8.2.1.jar:na] at kafka.consumer.SimpleConsumer.liftedTree1$1(SimpleConsumer.scala:74) ~[kafka_2.10-0.8.2.1.jar:na] at kafka.consumer.SimpleConsumer.kafka$consumer$SimpleConsumer$$sendRequest(SimpleConsumer.scala:68) ~[kafka_2.10-0.8.2.1.jar:na] at kafka.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:127) ~[kafka_2.10-0.8.2.1.jar:na] at kafka.javaapi.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:79) ~[kafka_2.10-0.8.2.1.jar:na] at storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:77) ~[storm-kafka-0.9.3.jar:0.9.3] at storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:67) ~[storm-kafka-0.9.3.jar:0.9.3] at storm.kafka.PartitionManager.<init>(PartitionManager.java:83) ~[storm-kafka-0.9.3.jar:0.9.3] at storm.kafka.ZkCoordinator.refresh(ZkCoordinator.java:98) ~[storm-kafka-0.9.3.jar:0.9.3] at storm.kafka.ZkCoordinator.getMyManagedPartitions(ZkCoordinator.java:69) ~[storm-kafka-0.9.3.jar:0.9.3] at storm.kafka.KafkaSpout.nextTuple(KafkaSpout.java:135) ~[storm-kafka-0.9.3.jar:0.9.3] at backtype.storm.daemon.executor$fn__3373$fn__3388$fn__3417.invoke(executor.clj:565) ~[storm-core-0.9.3.jar:0.9.3] at backtype.storm.util$async_loop$fn__464.invoke(util.clj:463) ~[storm-core-0.9.3.jar:0.9.3] at clojure.lang.AFn.run(AFn.java:24) [clojure-1.5.1.jar:na] at java.lang.Thread.run(Thread.java:744) [na:1.7.0_45] |
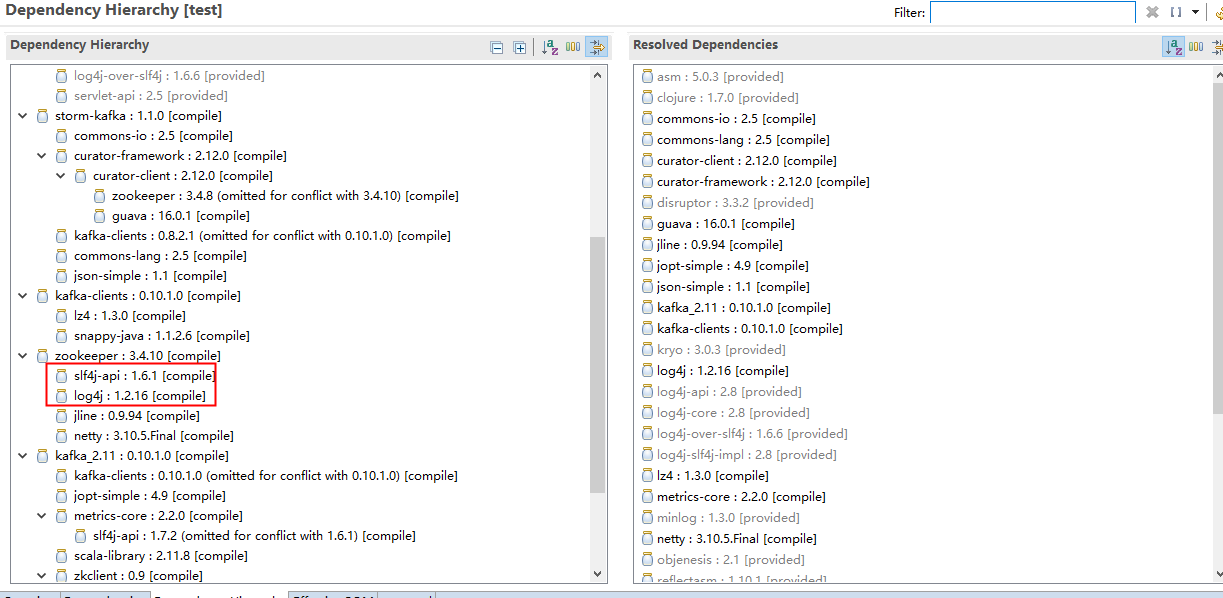
原因:KafkaSpout 代码里(storm.kafka.KafkaSpout)使用了 slf4j 的包,而 Kafka 系统本身(kafka.consumer.SimpleConsumer)却使用了 apache 的包.
解决办法:在依赖定义中去除问题依赖包
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10</artifactId> <version>0.10.1.1</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> </exclusions> </dependency> |
还有类似于zk和kafkaClient包冲突的情况:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
7630 [Thread-16-spout-executor[3 3]] INFO o.a.s.k.PartitionManager - Read partition information from: /test-topic/04680174-656f-41ad-ad6f-2976d28b2d24/partition_0 --> null7663 [Thread-16-spout-executor[3 3]] INFO k.c.SimpleConsumer - Reconnect due to error:java.lang.NoSuchMethodError: org.apache.kafka.common.network.NetworkSend.<init>(Ljava/lang/String;[Ljava/nio/ByteBuffer;)V at kafka.network.RequestOrResponseSend.<init>(RequestOrResponseSend.scala:41) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.network.RequestOrResponseSend.<init>(RequestOrResponseSend.scala:44) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.network.BlockingChannel.send(BlockingChannel.scala:112) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.liftedTree1$1(SimpleConsumer.scala:85) [kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.kafka$consumer$SimpleConsumer$$sendRequest(SimpleConsumer.scala:83) [kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:149) [kafka_2.11-0.10.0.1.jar:?] at kafka.javaapi.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:79) [kafka_2.11-0.10.0.1.jar:?] at org.apache.storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:75) [storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:65) [storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.PartitionManager.<init>(PartitionManager.java:103) [storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.ZkCoordinator.refresh(ZkCoordinator.java:98) [storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.ZkCoordinator.getMyManagedPartitions(ZkCoordinator.java:69) [storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.KafkaSpout.nextTuple(KafkaSpout.java:129) [storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.daemon.executor$fn__7990$fn__8005$fn__8036.invoke(executor.clj:648) [storm-core-1.0.2.jar:1.0.2] at org.apache.storm.util$async_loop$fn__624.invoke(util.clj:484) [storm-core-1.0.2.jar:1.0.2] at clojure.lang.AFn.run(AFn.java:22) [clojure-1.7.0.jar:?] at java.lang.Thread.run(Unknown Source) [?:1.8.0_111]7672 [Thread-16-spout-executor[3 3]] ERROR o.a.s.util - Async loop died!java.lang.NoSuchMethodError: org.apache.kafka.common.network.NetworkSend.<init>(Ljava/lang/String;[Ljava/nio/ByteBuffer;)V at kafka.network.RequestOrResponseSend.<init>(RequestOrResponseSend.scala:41) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.network.RequestOrResponseSend.<init>(RequestOrResponseSend.scala:44) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.network.BlockingChannel.send(BlockingChannel.scala:112) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.liftedTree1$1(SimpleConsumer.scala:98) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.kafka$consumer$SimpleConsumer$$sendRequest(SimpleConsumer.scala:83) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:149) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.javaapi.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:79) ~[kafka_2.11-0.10.0.1.jar:?] at org.apache.storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:75) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:65) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.PartitionManager.<init>(PartitionManager.java:103) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.ZkCoordinator.refresh(ZkCoordinator.java:98) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.ZkCoordinator.getMyManagedPartitions(ZkCoordinator.java:69) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.KafkaSpout.nextTuple(KafkaSpout.java:129) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.daemon.executor$fn__7990$fn__8005$fn__8036.invoke(executor.clj:648) ~[storm-core-1.0.2.jar:1.0.2] at org.apache.storm.util$async_loop$fn__624.invoke(util.clj:484) [storm-core-1.0.2.jar:1.0.2] at clojure.lang.AFn.run(AFn.java:22) [clojure-1.7.0.jar:?] at java.lang.Thread.run(Unknown Source) [?:1.8.0_111]7673 [Thread-16-spout-executor[3 3]] ERROR o.a.s.d.executor - java.lang.NoSuchMethodError: org.apache.kafka.common.network.NetworkSend.<init>(Ljava/lang/String;[Ljava/nio/ByteBuffer;)V at kafka.network.RequestOrResponseSend.<init>(RequestOrResponseSend.scala:41) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.network.RequestOrResponseSend.<init>(RequestOrResponseSend.scala:44) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.network.BlockingChannel.send(BlockingChannel.scala:112) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.liftedTree1$1(SimpleConsumer.scala:98) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.kafka$consumer$SimpleConsumer$$sendRequest(SimpleConsumer.scala:83) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:149) ~[kafka_2.11-0.10.0.1.jar:?] at kafka.javaapi.consumer.SimpleConsumer.getOffsetsBefore(SimpleConsumer.scala:79) ~[kafka_2.11-0.10.0.1.jar:?] at org.apache.storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:75) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.KafkaUtils.getOffset(KafkaUtils.java:65) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.PartitionManager.<init>(PartitionManager.java:103) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.ZkCoordinator.refresh(ZkCoordinator.java:98) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.ZkCoordinator.getMyManagedPartitions(ZkCoordinator.java:69) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.kafka.KafkaSpout.nextTuple(KafkaSpout.java:129) ~[storm-kafka-1.0.2.jar:1.0.2] at org.apache.storm.daemon.executor$fn__7990$fn__8005$fn__8036.invoke(executor.clj:648) ~[storm-core-1.0.2.jar:1.0.2] at org.apache.storm.util$async_loop$fn__624.invoke(util.clj:484) [storm-core-1.0.2.jar:1.0.2] at clojure.lang.AFn.run(AFn.java:22) [clojure-1.7.0.jar:?] at java.lang.Thread.run(Unknown Source) [?:1.8.0_111]7694 [Thread-16-spout-executor[3 3]] ERROR o.a.s.util - Halting process: ("Worker died")java.lang.RuntimeException: ("Worker died") at org.apache.storm.util$exit_process_BANG_.doInvoke(util.clj:341) [storm-core-1.0.2.jar:1.0.2] at clojure.lang.RestFn.invoke(RestFn.java:423) [clojure-1.7.0.jar:?] at org.apache.storm.daemon.worker$fn__8659$fn__8660.invoke(worker.clj:761) [storm-core-1.0.2.jar:1.0.2] at org.apache.storm.daemon.executor$mk_executor_data$fn__7875$fn__7876.invoke(executor.clj:274) [storm-core-1.0.2.jar:1.0.2] at org.apache.storm.util$async_loop$fn__624.invoke(util.clj:494) [storm-core-1.0.2.jar:1.0.2] at clojure.lang.AFn.run(AFn.java:22) [clojure-1.7.0.jar:?] at java.lang.Thread.run(Unknown Source) [?:1.8.0_111] |
原因:org.apache.kafka.common.network.NetworkSend 是一个Kafka客户端库,kafka 0.9以前,首先初始化这个类,pom.xml中未显示的声明Kafka-clients,故导致错误。
解决办法:加入Kafka-clients依赖.请参照以上的解决方法, 可以用eclipse去找冲突的包.
2. kafka本地Java生产者和消费者无法消费数据
这个问题一定要强调一下, 因为之前踩坑的时候的确很恼火, 明明在虚拟机里面是可以生产和消费的, 但是本地的JavaApi却始终无法访问.后来不经意间发现说要修改hosts文件.
本地的JavaApi如果hosts文件没有相关的ip地址是不会调通的.
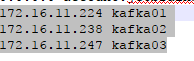
另外, 需要在虚拟机的host文件里面加上172.16.11.224 kafka01.
将server.config里面的配置改成advertised.listeners=PLAINTEXT://kafka01:9092
3. kafkaSpout的declareFields到底是什么
这个最开始是在一个kafka+storm热力图项目看到的, 老师根据查看kafkaSpout的源码发现它发送到下一层bolt的时候fileds的名称是bytes.

/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.storm.spout;
import java.nio.ByteBuffer;
import java.util.List;
import org.apache.storm.tuple.Fields;
import org.apache.storm.utils.Utils;
import static org.apache.storm.utils.Utils.tuple;
import static java.util.Arrays.asList;
public class RawMultiScheme implements MultiScheme {
@Override
public Iterable<List<Object>> deserialize(ByteBuffer ser) {
return asList(tuple(Utils.toByteArray(ser)));
}
@Override
public Fields getOutputFields() {
return new Fields("bytes");
}
}
而且分组的方法的也是shuffleGrouping, 这就为难了, 假如我想要在spout开始就按照fields分组呢? 或者在接收的时候不需要bytes字节而是自定义的格式呢?
这个时候就要更改kafkaSpout的源码和PartitionManager的相关代码了.
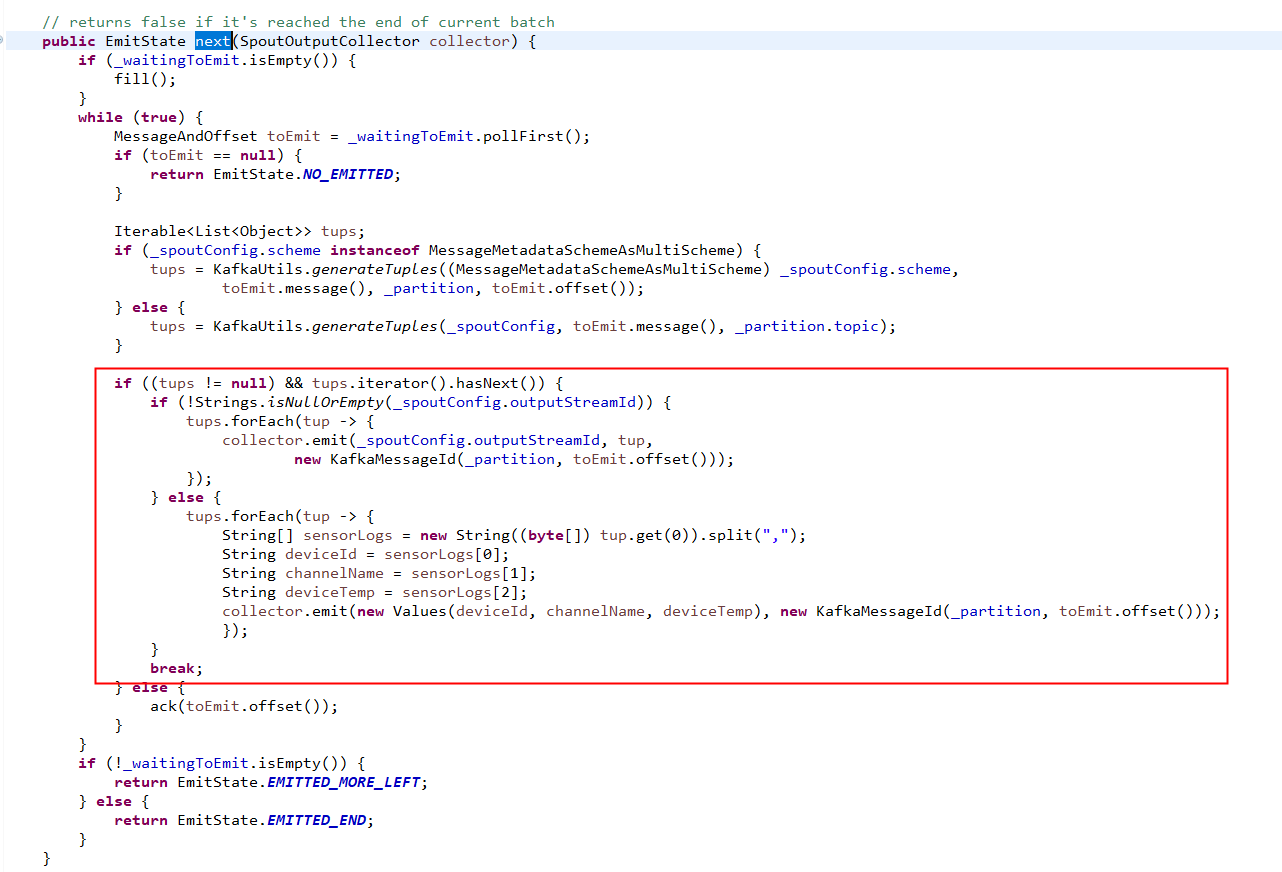

在这里也补充一个问题, 就是kafkaSpout有很多配置需要定.
通过SpoutConfig对象的startOffsetTime字段设置消费进度,默认值是kafka.api.OffsetRequest.EarliestTime(),也就是从最早的消息开始消费,如果想从最新的消息开始消费需要手动设置成kafka.api.OffsetRequest.LatestTime()。另外还有一个问题是,这个字段只会在第一次消费消息时起作用,之后消费的offset是从zookeeper中记录的offset开始的(存放消费记录的地方是SpoutConfig对象的zkroot字段,未验证)
如果想要当前的topology的消费进度接着上一个topology的消费进度继续消费,那么不要修改SpoutConfig对象的id。换言之,如果你第一次已经从最早的消息开始消费了,那么如果不换id的话,它就要从最早的消息一直消费到最新的消息,这个时候如果想要跳过中间的消息直接从最新的消息开始消费,那么修改SpoutConfig对象的id就可以了
下面是SpoutConfig对象的一些字段的含义,其实是继承的KafkaConfig的字段,可看源码
public int fetchSizeBytes = 1024 * 1024; //发给Kafka的每个FetchRequest中,用此指定想要的response中总的消息的大小
public int socketTimeoutMs = 10000;//与Kafka broker的连接的socket超时时间
public int fetchMaxWait = 10000; //当服务器没有新消息时,消费者会等待这些时间
public int bufferSizeBytes = 1024 * 1024;//SimpleConsumer所使用的SocketChannel的读缓冲区大小
public MultiScheme scheme = new RawMultiScheme();//从Kafka中取出的byte[],该如何反序列化
public boolean forceFromStart = false;//是否强制从Kafka中offset最小的开始读起
public long startOffsetTime = kafka.api.OffsetRequest.EarliestTime();//从何时的offset时间开始读,默认为最旧的offset
public long maxOffsetBehind = Long.MAX_VALUE;//KafkaSpout读取的进度与目标进度相差多少,相差太多,Spout会丢弃中间的消息
public boolean useStartOffsetTimeIfOffsetOutOfRange = true;//如果所请求的offset对应的消息在Kafka中不存在,是否使用startOffsetTime
public int metricsTimeBucketSizeInSecs = 60;//多长时间统计一次metrics