前几天在做数据库实验时,总是手动的向数据库中添加少量的固定数据,于是就想如何向数据库中导入大量的动态的数据?在网上了解了网络爬虫,它可以帮助我们完成这项工作,关于网络爬虫的原理和基础知识,网上有大量的相关介绍,本人不想在累述,个人觉得下面的文章写得非常的好(网络爬虫基本原理一、网络爬虫基本原理二)。
本博客就以采集博客园首页的新闻部分为例吧。本例为了直观简单就采用MVC,将采集到的数据显示到页面中,(其实有好多小型网站就是采用抓取技术抓取网上各自需要的信息,再做相应的应用)。另外在实际的抓取过程中可以采用多线程抓取,以加快采集的速度。
下面我们先看看博客园的首页并做相关的分析:
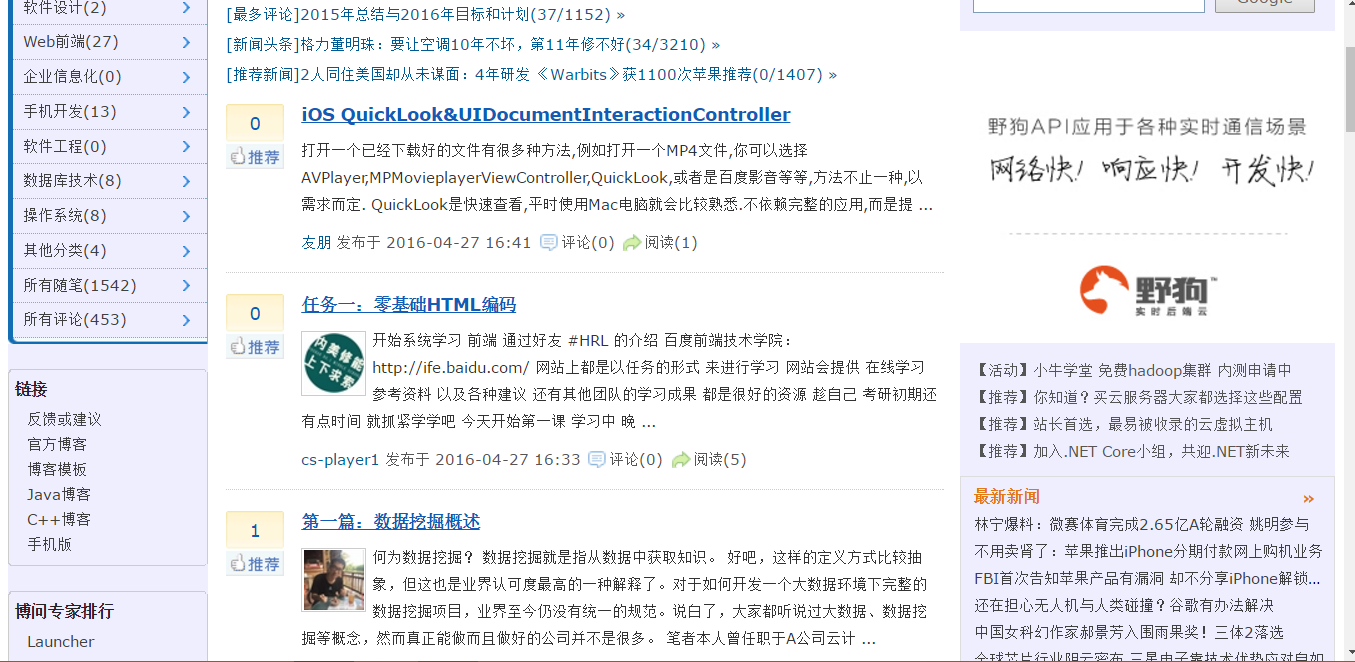
采集后的结果:

抓取的原理:先获取对应url页面的html内容,然后根据找出你要抓取的目标数据的的html结构,看看这个结构是否有某种规律,然后用正则去匹配这个规则,匹配到了以后就可以采集出来。我们可以先看看页面源码,可以发现新闻部分的规律:位于id="post_list"的<div>之间

于是,我们便可以得到相应的正则表达式了。
"<div\s*class="post_item">\s*.*\s*.*\s*.*\s*.*\s*.*\s*.*\s*.*\s*<div\s*class="post_item_body">\s*<h3><a\s*class="titlelnk"\s*href="(?<href>.*)"\s*target="_blank">(?<title>.*)</a>.*\s*<p\s*class="post_item_summary">\s*(?<content>.*)\s*</p>"
原理很简单,下面我就给出源代码:线建立一个MVC空项目,再在Controller文件下添加一个控制器HomeController,再为控制器添加一个视图Index
HomeController.cs部分代码:

using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
/// <summary>
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
/// </summary>
/// <param name="strUrl"></param>
/// <returns></returns>
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "<div\s*class="post_item">\s*.*\s*.*\s*.*\s*.*\s*.*\s*.*\s*.*\s*<div\s*class="post_item_body">\s*<h3><a\s*class="titlelnk"\s*href="(?<href>.*)"\s*target="_blank">(?<title>.*)</a>.*\s*<p\s*class="post_item_summary">\s*(?<content>.*)\s*</p>";
List<List<string>> list = new List<List<string>>();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List<string> one_list = new List<string>();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}
Index视图部分代码:
@{
Layout = null;
}
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width" />
<title>Index</title>
<style type="text/css">
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
</style>
</head>
<body>
<div>
<table id="customers">
<tr>
<th>标题</th>
<th>内容</th>
<th>链接</th>
</tr>
@foreach (var a in ViewBag.list)
{
int count = 0;
<tr>
@foreach (string b in a)
{
if (++count == 3)
{
<td><a href="@b">@HttpUtility.HtmlDecode(b)</a></td>@*使转义符正常输出*@
}
else if(count==1)
{
<td><font color="red">@HttpUtility.HtmlDecode(b)</font></td>
}
else
{
<td>@HttpUtility.HtmlDecode(b)</td>
}
}
</tr>
}
</table>
</div>
</body>
</html>
博客写到这,一个完整的MVC项目就可以运行了,但是我只采集了一页,我们也可以将博客园首页中的分页那部分(即pager_buttom)采集下来 ,再添加实现分页的方法即可,在此代码我就不贴了,自己试试看。不过如果要将信息导入数据库,则需要建立相应的表,然后按照表中的属性在从html中一一采集抽取出所需要的相应信息即可,另外我们不应该将采集到的每条新闻对应的页面源码存入数据库,而应该将每个新闻对应的链接存入数据库即可。原因是下载大量的新闻对应的页面需要大量的时间,印象采集的效率,并且将大量的新闻页面文件存入数据库,会需要大量的内存,还会影响数据库的性能。
,再添加实现分页的方法即可,在此代码我就不贴了,自己试试看。不过如果要将信息导入数据库,则需要建立相应的表,然后按照表中的属性在从html中一一采集抽取出所需要的相应信息即可,另外我们不应该将采集到的每条新闻对应的页面源码存入数据库,而应该将每个新闻对应的链接存入数据库即可。原因是下载大量的新闻对应的页面需要大量的时间,印象采集的效率,并且将大量的新闻页面文件存入数据库,会需要大量的内存,还会影响数据库的性能。