一、第一次作业
1.类图

第一次作业使用了两个类:
ComputePoly类中包含了:
属性:
polyList:存多项式的数组
opList:存操作符的数组
num:多项式的个数
opcount:操作符的个数
方法:
parsePoly(string s):提取多项式的方法
parseOperator(string s):提取操作符的方法
compute():进行多项式运算的方法
exceptionHandler(string s):判断错误类型并输出错误提示的方法
Poly类中包含了:
属性:
terms:存多项式的系数的数组
deg:多项式的阶
tags:记录多项式的阶是否已经输入的数组
方法:
initPoly(c,n):将多项式的系数存到terms的相应位置,即terms[n]=c;
degree():返回多项式的阶
coeff(int d):返回多项式某项的系数
addPoly(Poly q):将两个多项式相加
subPoly(Poly q):将讲个多项式相减
printPoly():按照格式输出多项式
2.度量
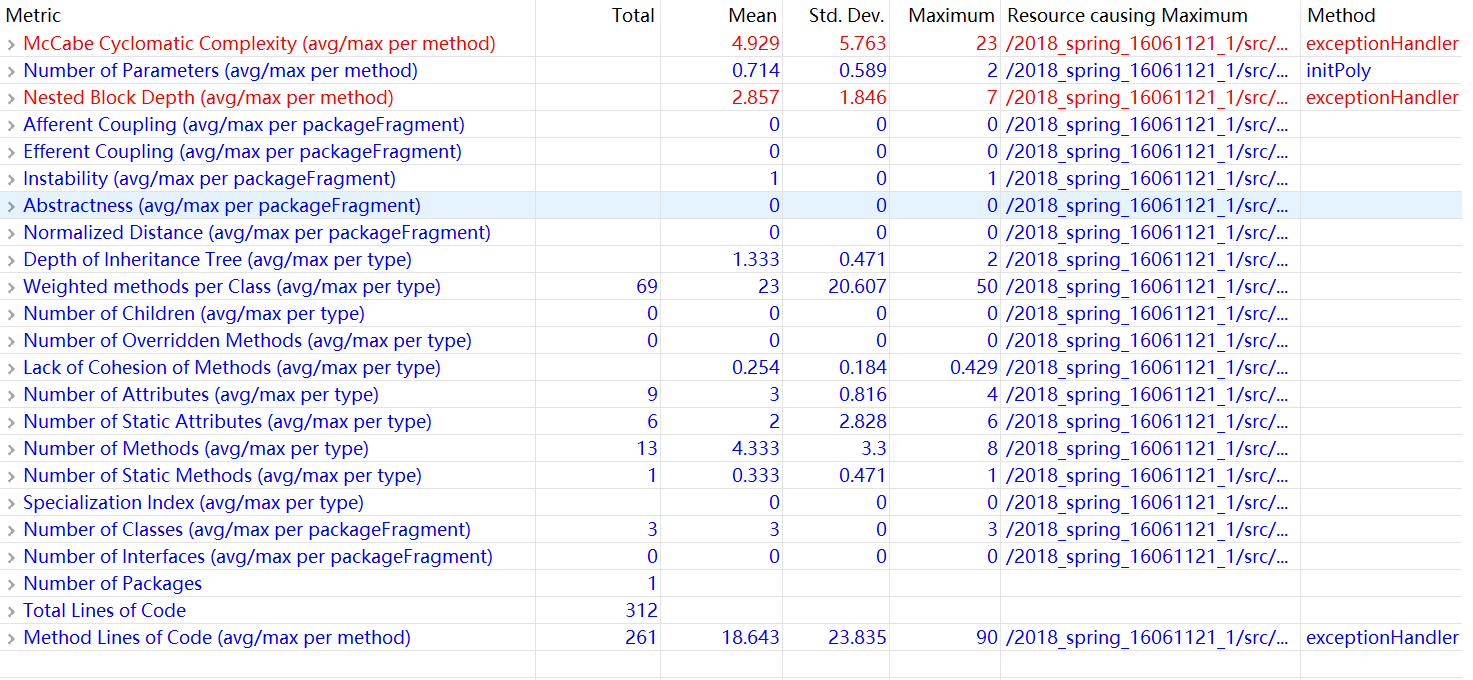
3.分析
在完成这次作业的过程中,我踩了一些坑。首先是正则表达式的使用上,我看是是写了匹配整个输入字符串的正则表达式,正则表达式冗余不说,当输入的字符串太长就会出现StackOverflowError异常。在查找资料(http://www.importnew.com/26560.html)之后发现,在使用正则表达式的时候,底层是通过递归方式调用执行的,每一层的递归都会在栈线程的大小中占一定内存,如果递归的层次很多,就会报出stackOverFlowError异常。所以出现这种问题可以简单理解为方法的嵌套调用层次太深,上层的方法栈一直得不到释放,导致栈空间不足。我尝试了一些正则性能的优化点来规避这种深层次的递归调用,但是效果甚微。因此我推翻了之前的匹配模式,换成了分步匹配,首先匹配多项式外部的格式,再匹配多项式内部的格式,这样正则表达式的嵌套没有那么深,程序也不会出现StackOverflowError异常。其次是在比较字符串的时候,我用“==”来比较时,发现程序并不能正确地判断,因此我换成了string1.equals(string2)来判断。由于我想要区分非法输入的种类,因此我写了一个exceptionHandler类来输出特定的非法字符的输出信息,但是,我没有规划好这个方法的判断逻辑,这直接导致了我的圈复杂度太高,代码看起来也很冗长。
初识oo,完全是用速成的java按照老师上课提到的思路来写程序,虽然没有被找到bug,但代码写的比较冗余,风格也不是很好,从我的度量就可以看出我的块嵌套太深,圈复杂度太高,代码的判断逻辑太复杂,想必拿到我代码的同学应该挺头大的。相比之下我拿到的那位同学的代码的逻辑就很清晰,代码也不像我的那么冗余,把那位同学的代码看过一遍之后,我就觉得他应该是个大佬吧,按照分支树测试了很多样例,并没有找到bug。
二、第二次作业
1.类图
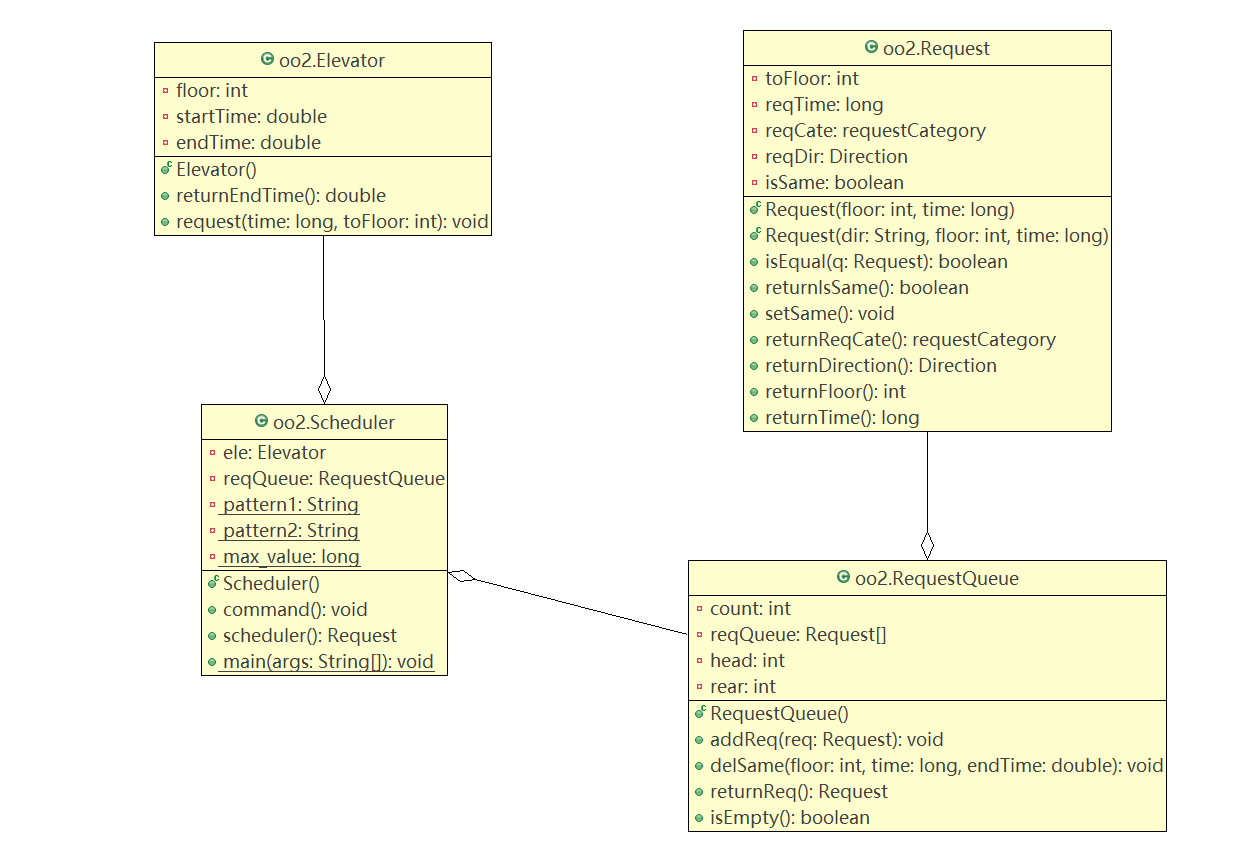
第二次作业实际用到了四个类:
Request类存储请求的信息,包括请求的类别,请求的目标楼层,请求发出的时间,还有楼层请求的方向等,并且还有一个标记请求是否是同质的属性。Request的方法中除了返回请求的相关属性的方法外,还有判断两个请求是否类型相同的方法,用于同质请求的判断。
RequestQueue类存储请求队列,队列头和尾的下标,以及队列中元素的个数。并且addReq(Request req)方法负责将请求加入队尾,delSame负责找出请求队列中所有与当前请求同质的请求,returnReq()负责取出对头的元素,isEmpty()返回队列是否为空。
Scheduler类负责调度请求队列中的请求,scheduler()方法返回一个请求,command()方法调用scheduler()方法获得请求交给电梯类调度。
Elevator类记录了电梯执行的上一个请求结束的时间和电梯当前所处的楼层。request()方法负责改变电梯的属性,并输出。
2.度量

3.分析
由于本次作业采用的傻瓜策略,所以代码的逻辑并不是很复杂,只不过开始理解错了同质的判断条件,后来改过来了。在这次作业中,请求的时间T是4字节的非负整数,也就是说T的最大值是无符号整数的最大值,但是java中的int都是有符号型的,输出Integer.MAX_VALUE也可以印证这一点。所以作业中就不能用int来存储T值,而是用long或者double来存储T。但是为了不让输入的数字太长超出了long或者double的范围,我限制输入的数字除去前导零位数不能超过10。
由于这次作业我是自己规划的类的属性和方法,所以我的类并不均衡,这也是我需要不断磨练的地方吧。我的作业实际上只用了四个类(还有一个僵尸类被我用来凑数来着),我并没有模拟真实的时间来运行,因为我觉得那样可能跑的慢,所以我在电梯类里存了电梯上一任务结束的时间,使用这个属性就可以很方便的判断同质请求了。
在这次测试时,由于想样例太麻烦,我就写了一个python程序来随机生成合法的测试样例。但是我测合法输入测的太high,导致我没有完全的测试非法输入,互测就被找到了一个bug。因为在匹配楼层时,需要限制楼层必须是1-10的数字,因此我写的\+?0{1,6}[1-9]|(10),但是这样写的问题在于10前面如果有+或者0,就会被判为非法输入,所以我应该改为\+?0{0,6}([0-9]|(10))。这次作业虽然没有给别人测到bug,但是我在测试上还是长进了不少的,心态也变化了很多,可以静下心来阅读和测试别人的代码。然鹅在互测阶段,我还是没有找到对方的bug。
三、第三次作业
1.类图
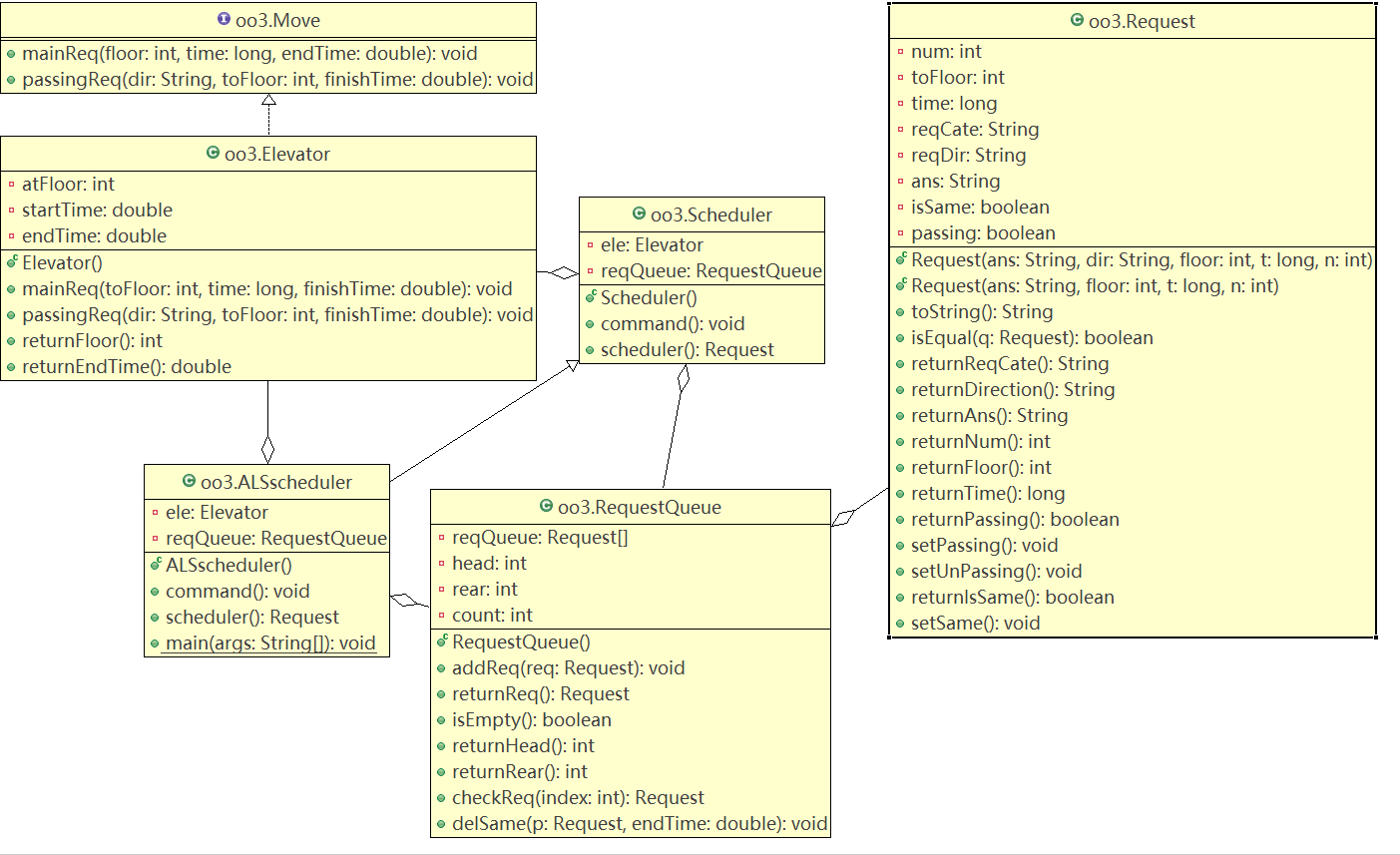
第三次作业实际用到了四个类:
Request类与第二次作业大致相同,该类存储请求的信息,包括请求的类别,请求的目标楼层,请求发出的时间,还有楼层请求的方向等,并且还有一个标记请求是否是同质的属性。Request的方法中除了返回请求的相关属性的方法外,还有判断两个请求是否类型相同的方法,用于同质请求的判断。同时该类重写了toString方法用来输出请求的信息。
RequestQueue类存储请求队列,队列头和尾的下标,以及队列中元素的个数。并且addReq(Request req)方法负责将请求加入队尾,delSame负责找出请求队列中所有与当前请求同质的请求,returnReq()负责取出对头的元素,isEmpty()返回队列是否为空。
ALSscheduler类继承自第二次的Scheduler类,但重写了scheduler()方法和command()方法,该类负责调度请求队列中的请求,scheduler()方法返回一个请求,command()方法判断该请求是否可被捎带,并调用scheduler()方法获得请求交给电梯类调度。
Elevator类记录了电梯执行的上一个请求结束的时间和电梯当前所处的楼层。request()方法负责改变电梯的属性,并输出。
2.度量
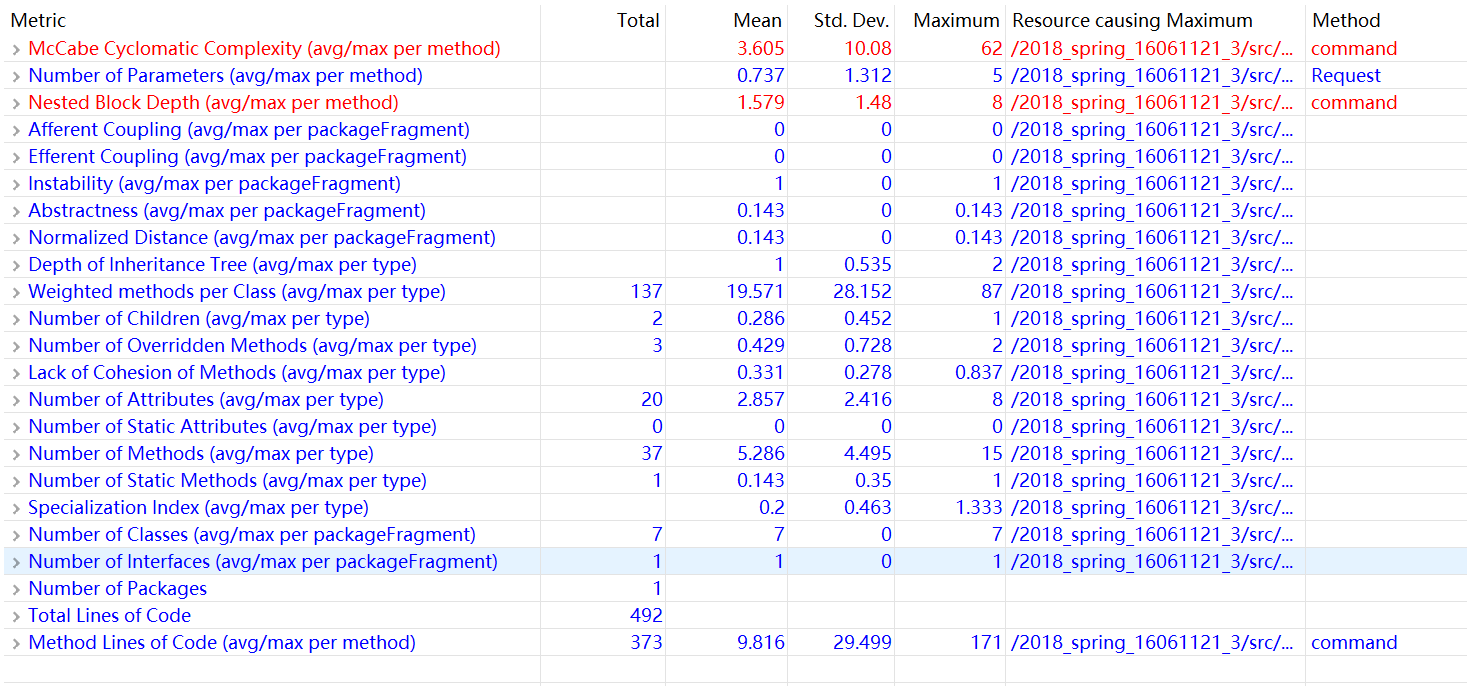
3.分析
本次作业加上了捎带要求,在理解清楚捎带策略上,我就花了不少的时间。但是由于动手写代码开始的太早,没有完全想清楚就开始写,导致我写的代码逻辑改到后面变得有点复杂,再加上第二次作业的类规划的就不好,所以我在写完之后找出来很多很多很多很多的bug,第三次作业从第二次作业继承的scheduler类也很冗余。因为这次作业做了很多的测试,我认为测试程序的时候,不能满足于输入规模很小的数据,当数据规模变大的时候,有些问题才容易出现,所以这次作业我用了很多工具来测试我的程序。比如说,我们随机生成了几万行的测试数据,然后用vimdiff来比对输出,找出了不少的bug。同时我吸取了第二次的教训,对不合法的输入也进行了很多测试,所以这次作业我没有被找出bug。
在互测阶段我发现了对方在输出同层请求时顺序不对的一个小bug。
四、测试策略
我认为写代码之后的测试环节还是很重要的,从前总是依赖评测机,AC了总有一种万事大吉的感觉,但是现在不行了,要想尽办法耐心地去debug。我觉得在debug之前首先要确保自己指导书上的规定搞明白了,这个时候可以对着指导书和issue上的提问,通读一下自己的代码,看看逻辑上是不是有疏漏。然后就可以动手debug了。我一般先确保合法输入的输出是正确的,我先构造一些特殊的小样例,来看看自己的输出是不是和想的一样。之后我就会随机出很多测试样例,超级长的那种,然后和室友同学比对输出,这样可以测试出一些隐藏的bug。最后也不能忽视非法输入的测试,我会对着bug分支树,各种测试,怎么非法怎么来。测试对方代码的时候也是这样,看看他的readme,通读一下他的代码,找找漏洞,要是没找到啥漏洞的话就按照bug分支树来测他的代码,基本上可以测的比较完全了。
五、总结
1.在设计上,我认为我在类的规划上做的并不好,导致我有的类很长有的类却很短,而且我都main函数有时习惯会顺手放在某个类里,不会单独放在一个类里,这样我的类就会很混乱,这不是一个很好的习惯。所以我认为在编码之前,我应该仔细思考,规划好类的属性和方法,想的越清楚就写起来就越顺利。
2.在调试时,我一般是混合使用System.out和debug,开始的时候我觉得debug那个功能很烦,因为它老是跳到乱七八糟的方法里去,所以我开始并没有使用debug来调试,但是在第三次作业时,出现的bug太多而且都很迷,我就开始使用debug的功能,后来发现debug会用了之后,还是很方便的。另外测试的时候一定要耐心,不要烦躁,心中默念,世界如此美妙,我却如此暴躁,这样不好不好。
3.几次互测中,我看过了其他同学的代码,我感觉我的思想还是停留在面向过程的阶段,我还需要加强面向对象的编程能力。
4.还有就是不要有拖延症,最好周末就要开始研究指导书,不要拖到周一才开始动手不然会很痛苦。