实验一:大数据同步技术datax的使用
目的:利用datax将.csv文件中的数据同步导入mysql中(乱码问题可通过输入命令 CHCP 65001解决)
1.Navicat里面建立数据表
2.仿照dataxjob中的job.json进行修改,新建立job_yq.json文件
reader中修改输入源

index 对应数据表三个字段 0 1 2

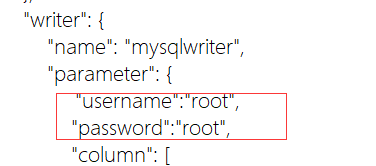
3.修改输出源 用户名及密码
4.输出源中添加数据表对应字段

5.连接数据表修改表名
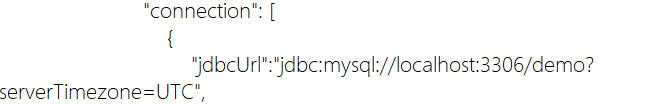

附上我的json文件可以参考修改


{ "job": { "setting": { "speed": { "channel": 3 } }, "content": [ { "reader": { "name": "txtfilereader", "parameter": { "path":["D:/Projects/phython/pycharm/PythonEX/learn_six/疫情省.csv"], "encoding":"GBK", "column": [ { "index":0, "type":"string" }, { "index":1, "type": "string" }, { "index":2, "type": "string" } ], "fieldDelimiter":"," } }, "writer": { "name": "mysqlwriter", "parameter": { "username":"root", "password":"root", "column": [ "riqi", "pro", "que_num" ], "preSql": [ "truncate table yq_province" ], "connection": [ { "jdbcUrl":"jdbc:mysql://localhost:3306/demo", "table":[ "yq_province" ] } ] } } } ] } }
到此配置好后直接运行命令: python datax json目录即可, 这里需要在datax/bin目录下运行此命令。
例如:python datax.py E:xitongmajordataxjobjob_yq.json
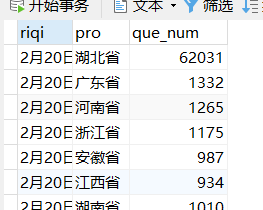
易错点:这里路径一定要用/ 反斜杠会出错

实验二:大数据清洗技术kettle的使用
待更新
实验三:大数据日志采集技术Logstash
待更新
实验四:大数据实时采集技术Kafka
待更新
实验五:动态感知舆情热点大数据采集技术
待更新