本文基于Hadoop1.X
概述
分布式文件系统主要用来解决如下几个问题:
- 读写大文件
- 加速运算
对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整个硬盘的容量的文件,这时需要将文件分割为若干较小的块,然后将这些块按照一定的规则分放在集群中若干台节点计算机里。
分布式文件系统的另一个作用是加速运算,在多台计算机上对每个子文件进行计算最后再汇总结果通常比在一台计算机上处理大量文件的运算要块。这种分而治之的思想倡导:与其追求造价昂贵的高性能计算机,不如多找几个性能普通的廉价机器来搞。
廉价的机器集群还有一个比单个高性能计算机更有优势的地方是灵活性,可以非常方便的增加或减少集群中节点的数量,比起单个高性能机器,这种设计在计规模小时也不会造成资源(CPU,内存)的浪费,在规模膨胀时又能通过简单的增加节点的动作轻松应对。
然而,任何事情都有两面性,集群的弱点在于出现故障的几率变大了,假设单台机器故障率是p,那么具有n台机器节点的集群故障率就是pn,为了能够在某些节点出现故障的情况下不影响整个集群的健康,集群中不得不将每个节点中的数据备份多份放在别的节点,这样当某个节点的数据不可用时还可以读取备份节点的数据。集群以冗余为代价换取高可用性。
HDFS(Hadoop Distrbuted File System)是当今世界上最流行的分布式大数据处理系统Hadoop所依赖的文件系统,它的思想源头是伟大的Google公司发表的论文:The Google File System,受此启发,雅虎的若干大神包括Doug Cutting等把它搞出来的。
HDFS的特点
- 适合处理超大文件:超大文件是指大小超过几百M,几百G甚至几百T的文件。HDFS不适合处理小文件,首先,HDFS的文件块(block)默认为64M,太小的文件会造成磁盘的浪费;其次,HDFS的元数据信息(记录文件、路径和分块情况等信息)保存在某个节点(NameNode)的内存中,大量的小文件需要大量的元素据来记录,大量的元素据需要大量的内存;
- 流式数据访问:一次写入数据,然后多次读取数据的大部分甚至全部进行分析,不支持随机读取操作
- 对节点计算机的要求较低:无需昂贵的高性能机器,集群可由廉价机器组成
- 不适合对数据读写延时有严格要求的场景:HDFS重在高吞吐量,付出的代价之一就是提高了延迟时间
- 不支持多用户写入,不支持随机写操作:只能顺序将数据添加到文件结尾
想要实现随机读写以及延时较低的数据读写,请考虑使用基于HDFS的HBase数据库。
HDFS的结构
HDFS是一个基于操作系统本身的文件系统之上的虚拟文件系统,和常见的文件系统一样,HDFS文件存储的最小单元是块(block),默认的块的大小是64M,一个文件的若干块可分布在不同的机器上(DataNode),所以才“分布式”了。
集群节点由三部分组成,分别是
- NameNode (只有一个)
- DataNode
- Secondary NameNode(只有一个)
NameNode节点负责保存和维护整个集群的元数据(Hadoop2并不是这样,希望后续文章会涉及),包括文件名、文件分块(block)、文件的块分布在哪些节点、整个文件系统的运行状态等信息,一个集群中只有一个节点是NameNode节点。
DataNode节点负责实际存放数据。
由于整个集群只有一个NameNode节点,该节点如果挂了整个集群也就完蛋了,所有又搞了一个Secondary NameNode出来,它会定时获取NameNode的快照,当NameNode挂掉后可以通过Secondary NameNode快速恢复(Hadoop2并不是这样,希望后续文章会涉及)。
下图来自《Hadoop 实战》:
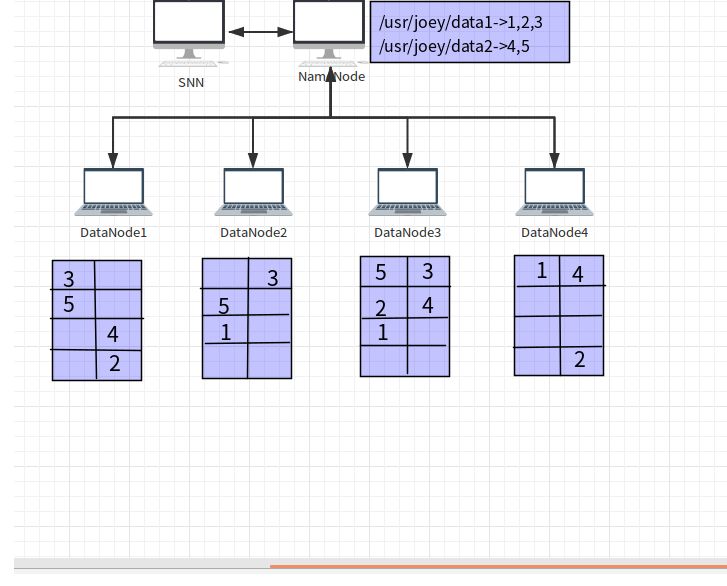
文件data1和data2的元数据信息保存在NameNode节点中,元数据中记录了data1文件由3个文件块1,2和3组成,文件data2由2个文件块4和5组成,并且记录了每个块所在的DataNode节点。文件块分布在4个DataNode节点上,每个文件块有都保存3份(3份是默认的设置)。DataNode还定时给NameNode发送心跳数据,如果NameNode长时间没有收到心跳数据,则认为DataNode挂掉了。
HDFS的命令行接口
下载并安装Hadoop后,即可使用HDFS了,Hadoop的安装和配置请参考Hadoop学习之旅一:Hello Hadoop。HDFS类似于Unix的文件系统,权限的设定也是分w、r和x(可执行ls命令查看,该命令类似Unix的ls -l 命令),常用命令和Unix的文件操作命令相同或类似,下面介绍几个常用的命令:
- ls:
bin/hadoop fs -ls /user#列出路径/user下的所有文件和路径 - lsr: `bin/hadoop fs -lsr /user #列出路径/user下的所有文件并递归列出子路径及子路经下的文件
- mkdir: bin/hadoop fs -mkdir /user/hdfs_test #创建路径 /user/hdfs_test
- rmr: bin/hadoop fs -rmr /user/hdfs_test #删除路径 /user/hdfs_test
- put: bin/hadoop fs -put hello.txt /user/hdfs_test #拷贝本地文件到HDFS路径/user/hdfs_test
- get: bin/hadoop fs -get /user/hdfs_test/hello.txt /home/joey #将hello.txt文件从HDFS拷贝到本地文件系统
- cat: bin/hadoop fs -cat /user/hdfs_test/hello.txt #查看文件内容
更多命令请查看官方文档。
HDFS的Java编程接口
实际上,上面的命令行接口就是一个Java应用,下面利用编程接口写一个示例程序,该程序使用FileSysgem类读取本地参数指定的路径下以“hadoop”开头的文件并将其复制到参数指定的HDFS路径:
package test.joye.com;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Copy {
public static void main(String[] args) {
Path localPath = new Path(args[0]); // /home/joey/test"
String hdfsPath = args[1]; // /user/hdfs
Configuration conf = new Configuration();
conf.set("fs.default.name", "hdfs://localhost:9000");
try {
FileSystem hdfs = FileSystem.get(conf);
FileSystem local = FileSystem.getLocal(conf);
FileStatus[] inputFiles = local.listStatus(localPath);
for(int i = 0; i < inputFiles.length; i++){
String fileName = inputFiles[i].getPath().getName();
if(fileName.startsWith("hadoop")){
FSDataOutputStream out = hdfs.create(new Path(hdfsPath + "/" + fileName));
FSDataInputStream in = local.open(inputFiles[i].getPath());
byte[] buffer = new byte[256];
int bytesRead = 0;
while((bytesRead = in.read(buffer)) > 0){
out.write(buffer, 0, bytesRead);
}
in.close();
out.close();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
该程序引用了如下包:
关于更多的API可以参考官方文档
参考资料
-
《Hadoop权威指南》
-
《Hadoop实战》
-
网易云课堂:大数据工程师