简单了解
概述
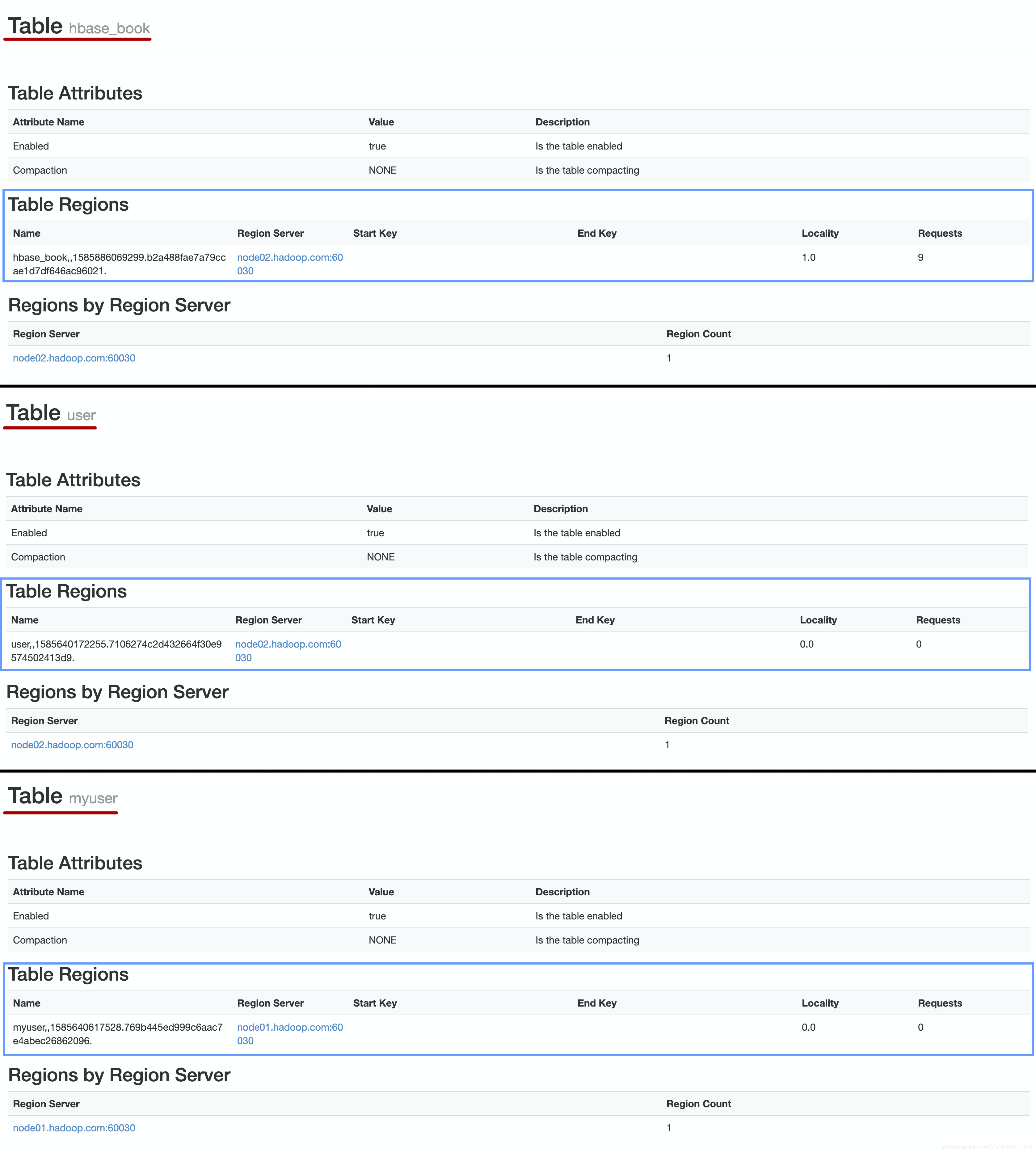
由上图可以看出,每一个表都有属于自己的一个Region,但Region内的数据达到10GB时,会进行分割,但仍会在同一个RegionServer上,而预分区的作用主要是增加数据读写效率、负载均衡、防止数据倾斜、方便集群容灾调度Region和优化Map数量
设置预分区
在设置预分区前要先明白一个概念,每一个Region都维护着从StartKey到EndKey的数据,如果加入的数据符合某个Region的rowKey范围,就把数据交给这个Region维护
比如说,现在有三个分区,它们的StartKey和EndKey分别是1-1000,1001-2000,2001-3000,现在如果有一条rowKey为1888的数据,那么他就会被分配到第二个Region中
预分区的设置方法一共有四种:
一、手动指定预分区
进入hbase shell输入一下命令
create 'staff','info','partition1',SPLITS => ['1000','2000','3000','4000']
二、使用16进制算法生成预分区
进入hbase shell输入一下命令
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
三、将分区规则写在文本文件中
首先在/export/servers目录下创建splits.txt文本文件,并输入一下内容
aaaa
bbbb
cccc
dddd
然后在hbase shell中执行以下命令
create 'staff3','partition2',SPLITS_FILE => '/export/servers/splits.txt'
四、使用JavaAPI进行预分区
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.testng.annotations.Test;
import java.io.IOException;
public class HbasePartition {
/**
* 通过javaAPI进行HBase的表的创建以及预分区操作
*/
@Test
public void hbaseSplit() throws IOException {
//获取连接
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = {{1,2,3,4,5},{'a','b','c','d','e'}};
//通过HTableDescriptor来实现我们表的参数设置,包括表名,列族等等
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("stuff4"));
//添加列族
hTableDescriptor.addFamily(new HColumnDescriptor("f1"));
//添加列族
hTableDescriptor.addFamily(new HColumnDescriptor("f2"));
admin.createTable(hTableDescriptor,splitKeys);
admin.close();
}
}

注意
在实际工作当中,创建表时一般都需要提前做预分区处理,一般来说每台服务器上面设置两个到五个的预分区,这么做可以更好地减少Split的过程,在设置预分区时,rowKey的设计尤为重要
关于rowKey的设计可以查看文章:【HBase】快速了解上手rowKey的设计技巧