Ⅰ、什么是索引
索引是一种提高数据库查询效率的数据结构(我们说的一般都是B+ tree索引)
(root@localhost) [test]> show create table l G
*************************** 1. row ***************************
Table: l
Create Table: CREATE TABLE `l` (
`a` int(11) NOT NULL,
`b` int(11) DEFAULT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`a`), -- 主键
UNIQUE KEY `c` (`c`), -- 唯一索引
KEY `b` (`b`) -- 普通索引
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.08 sec)
一张表可以有多个索引,索引就是对创建索引的这些列进行排序
优点:
使查询速度变得非常快,且这个快基本上和数据量没关系
缺点:
很多索引都要排序则要对这些索引列进行维护,直接插入本来很快,但是有了索引做ddl操作则代价比较大,虽说不能太多索引列,但是大场景下很难做到
tips:
主键和唯一索引的区别:
- 一张表只能有一个主键,唯一索引可以有多个
- 主键不可以为NULL,唯一索引可以
MySQL一张表的大小是多少?
很多人说一张表不能太大,太大要拆表?这么说的两个原因(oracle没这个说法):
a.MySQL之前的DDL操作,比较麻烦,创建了索引,再做这些会表锁(全局读锁),数据量太大会锁时间太长,也就是之前不支持online ddl嘛。以前都是先在slave上搞,搞好做个主从的切换
b.之前MySQL的索引源代码的实现上有一把大锁,导致性能比较一般,不过没有淘宝这个业务量基本上影响不大,但是5.7也解决了这个问题
综上:MySQL5.7这时候,索引本身已经实现地很完整了(管理和性能两个方面),一亿不是什么问题
tips:
- 大锁:索引排序的时候做一个split的操作(也不会一直做split),拆分,本来把拆分的两个页锁住即可,但是那时候是整个B+ tree锁住了,并发性就受到影响比较大了,
- 用MySQL就得上SSD,单表能承受1亿根本不是什么大问题,一个亿和一千万,查询和维护代价基本上都是一样的,五年前五百万分表或许是适合的,现在就算了吧
- sas盘的iops再怎么优化也只有一千,拆了最多是管理操作方便点,但也有问题,某个时间点数据不一定一致,比如某个时间点,这个表比另一个表多一个列,sas五百万或者一千万差不多了,可以做个raid10,ssd做raid5或者不做都可以
- 电商平台,快递行业,一个月前的订单,归档,用分区表来做,和性能没关系,只是一个管理操作,也就是说分区表不是用来提升性能的,反而会下降,除非都走分区字段,但是线上查询条件太多太多
再强调:
1.MySQL用SSD
2.拆表不会提升性能
3.现在不存在最多多少记录的问题
Ⅱ、B+ tree概述
2.1 B+ tree的定义
B+ tree是一种基于块(page)设备的存储中来有效的存取,检索数据的数据结构
show variables like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
默认16k,oracle默认8k
看数据库中.ibd文件,大小都是16k的倍数
tips:
文件系统都是基于块的
db 16k
-----------------------------------
filesystem(xfs) 4k 八个扇区 ,可以调大提升性能
-----------------------------------
disk 512字节
2.2 B+ tree的构成
- root leaf
根 - none leaf
非叶子节点存放指针和键值 - leaf
叶子节点,用来排序的,存放每一行的完整记录(页子节点之间是有序的,页子里面记录也是有序的) - fan out
扇出,多少个指针,一个块设备能存很多记录,这时候扇出非常大,性能也非常好
B+ tree基于块设备存储,一个页能存非常多记录,扇出非常高 - 指针
指向下一个层级,先找,找不到返回空
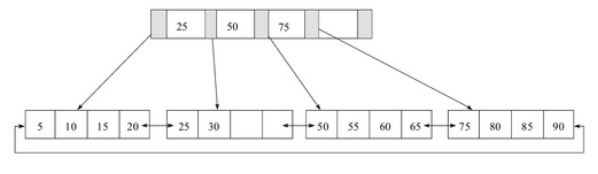
该B+ tree高度为2,每个叶子节点存放4条记录,扇出数为5,叶子节点由小到大有序
tips:
上面说的有序指的是逻辑有序,不是物理的,在磁盘上做不到有序,每个页之间有指针告诉他下一个页和前一个页,但是物理上可能跨了好几个页
Ⅲ、 B+ tree的维护
插入数据操作
如何插入28这条记录?
先找28所在的页,通过二分查找,找到指针指到的页,如果页中还有空闲就直接插
但是想插70,发现70所在的页已经满了,这时候就会做一个split操作(代价蛮大的),把这个页拆成两个页,最常用的是把这个页的中间值(这里是60)提取出来放到上面,两边往下拆
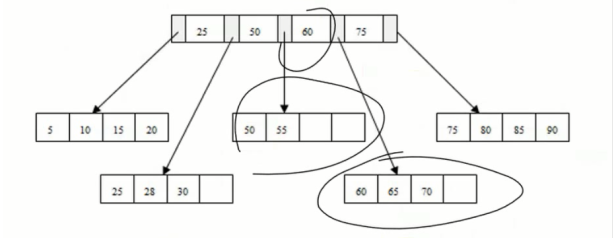
插95呢,发现也满了,想拆,但是发现上一层节点也满了,所以要做两次split
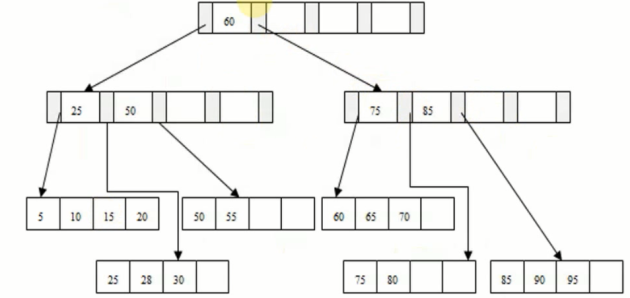
MySQL5.7之前split代价非常大,会把整棵树都锁住,这时候其他记录插入和更新就不方便了,但是通常分页本身也还是蛮快的额,也不会一直分页,只是页满了的情况才会分,所以问题也不是很大,5.7不会一下子锁住,会尽量用小的锁控制并发
插入95之后B+ tree的高度从2变成了3
删数据操作
如果一个页里面的数据很少了则会尝试和它左边或者右边的页进行合并
Ⅳ、索引实践
alter table x add index unique idx_b (b); -- 在b上创建一个唯一索引
alter table x add index index_a (a); -- 在a上创建一个普通索引
alter table x drop index index_a; -- 删除a上面的索引
在线上就不一样咯
还记得online ddl表嘛?
5.6之前创建索引并不是online的,会对这个表加一个读锁(S lock)只能select不能insert,会阻塞
5.6开始原生支持了在线索引添加,在添加索引过程中,应用程序对表依然可读可写
online ddl的这段时间内,对表做的操作会先记录到alter table的日志里,这个日志是内存的,如果内存大小太小记不下来就会报错
(root@localhost) [(none)]> show variables like 'innodb_online_alter_log_max_size';
+----------------------------------+-----------+
| Variable_name | Value |
+----------------------------------+-----------+
| innodb_online_alter_log_max_size | 134217728 |
+----------------------------------+-----------+
1 row in set (0.00 sec)
如果线上更新操作比较多,调大这个值set global innodb_online_alter_log_max_size = 128M,这是个全局变量,在my.cnf中也配上
在线索引添加存在的一个问题——主从延时(MySQL逻辑复制,oracle物理复制不存在这个问题)

alter table是执行完之后才告诉从机要执行(事务),从库也顺序执行,当执行到这个在线ddl,其他并行的dml语句,也要等待这个ddl执行完毕后才能并行
同步的是二进制日志,要等事务执行完之后才提交过去,并不是物理日志
真正在线上很少用alter table这种方式去执行ddl操作,即使5.7现在对越来越多的ddl操作读写不阻塞了,就是因为主从延时
现在就要percona toolkit出场了(备注,除了下面介绍的这个工具,里面的其他工具不建议使用,尽量使用官方的)
这里面最有用的就是pt-online-schema-change,其他工具官方工具包utlities里面都有了,官方也在做前面那个工具了
这个工具做在线ddl,主从延迟非常小,不是直接操作的,是通过触发器的机制来慢慢加,还有控制延时的参数呢
关于online ddl和pt-osc详见这里