1.LinkedHashSet



1 import java.util.LinkedHashSet; 2 3 public class LinkedHashSetDemo { 4 5 public static void main(String[] args) { 6 // TODO Auto-generated method stub 7 8 LinkedHashSet linkedHashSet = new LinkedHashSet(); 9 10 linkedHashSet.add(new Car("奥拓",1000)); 11 linkedHashSet.add(new Car("奥迪",300000)); 12 linkedHashSet.add(new Car("法拉利",10000000)); 13 linkedHashSet.add(new Car("奥迪",300000)); 14 linkedHashSet.add(new Car("保时捷",70000000)); 15 linkedHashSet.add(new Car("奥迪",300000)); //这条加入不了,因为重复了. 16 17 //当我们遍历后,发我们发现LinkedHashSet的特点 18 //1. 添加时,仍然是有HashSet规则. 19 //2. 维护了双向链表,保证遍历的顺序 20 for (Object object : linkedHashSet) { 21 System.out.println(object); 22 } 23 24 } 25 26 } 27 28 class Car { 29 private String name; 30 private double price; 31 32 33 //使用eclipse生成 34 //这里hashCode将属性考虑到. 如果我们的属性相同,则hashCode就相同 35 //重写hashCode的目录:就是希望通过你(程序员)指定的属性,返回一个唯一的hashCode值. 36 //目的是希望只要你给的的属性值相同,那么返回的hashCode() 37 38 // @Override 39 public int hashCode() { 40 final int prime = 31; 41 int result = 1; 42 result = prime * result + ((name == null) ? 0 : name.hashCode()); 43 long temp; 44 temp = Double.doubleToLongBits(price); 45 result = prime * result + (int) (temp ^ (temp >>> 32)); 46 return result; 47 } 48 49 50 //这里比较时重写equals, 主要是比较属性值是否相同 51 // @Override 52 public boolean equals(Object obj) { //== 53 if (this == obj) 54 return true; 55 if (obj == null) 56 return false; 57 if (getClass() != obj.getClass()) 58 return false; 59 Car other = (Car) obj; 60 if (name == null) { 61 if (other.name != null) 62 return false; 63 } else if (!name.equals(other.name)) 64 return false; 65 if (Double.doubleToLongBits(price) != Double.doubleToLongBits(other.price)) 66 return false; 67 return true; 68 } 69 70 71 public Car(String name, double price) { 72 super(); 73 this.name = name; 74 this.price = price; 75 } 76 77 78 public String getName() { 79 return name; 80 } 81 82 public void setName(String name) { 83 this.name = name; 84 } 85 86 public double getPrice() { 87 return price; 88 } 89 90 public void setPrice(double price) { 91 this.price = price; 92 } 93 94 @Override 95 public String toString() { 96 return "Car [name=" + name + ", price=" + price + "]"; 97 } 98 99 }
2.Map



1) HashMap和Hashtable 实行了Map接口,使用虚线表示
2) Properties 是Hashtable的子类
3) LinkedHashMap 是HashMap的子类
4) SortedMap是一个Map子接口
5) TreeMap 是SortedMap的实现子类,是可以进行排序处理.
3.Map常用方法


1 import java.util.HashMap; 2 import java.util.Map; 3 4 public class MapDemo { 5 6 public static void main(String[] args) { 7 // TODO Auto-generated method stub 8 Map map = new HashMap();//这是一个hashmap对象实例 9 10 //1. 映射关系的数据:Key-Value 11 //2. Map 中的 key 和 value 都可以是任何引用类型的数据 12 //3. Map 中的 key 用Set来存放,不允许重复, 如果有重复key,则后面的value覆盖前面value, 等同于修改 13 //4. Map 中的 value 可以重复 14 //5. Map 的key 可以为 null, value 也可以为null 15 //6. Map元素是无序的,因为key是用Set来存放的 16 map.put("邓超", new Book("天龙八部",100)); 17 map.put("邓超", "孙俪"); 18 map.put("王宝强", "马蓉"); 19 map.put("宋喆", "马蓉"); 20 map.put("刘令博", null); 21 map.put(null, "刘亦菲"); 22 map.put("鹿晗", "关晓彤"); 23 24 25 26 //这时我们遍历Map是使用其他的方案(仍然是迭代器,但是使用方法有变化) 27 System.out.println(map); 28 29 //通过get 可以获取到对应的值 30 Object object = map.get("邓超"); 31 System.out.println("object=" + object); 32 //通过remove可以删除某对key-value 33 map.remove("鹿晗"); 34 System.out.println(map); 35 36 //containsKey 用于判断该map中是否有该key,返回boolean 37 //containsValue 用于判断该map中是否有该value,返回boolean 38 System.out.println(map.containsKey("王宝强")); // true 39 System.out.println(map.containsKey("王宝强~")); // false 40 System.out.println(map.containsValue("刘亦菲"));// true 41 System.out.println(map.containsValue("刘亦菲~"));// false 42 43 //size和isEmpty 44 System.out.println(map.size()); // 5 45 System.out.println(map.isEmpty()); // false 46 47 //clear:清除 48 map.clear();//将map中的所有key-value全部清空 49 System.out.println(map); 50 51 } 52 53 } 54 55 class Book { 56 private String name; 57 private int price; 58 public Book(String name, int price) { 59 super(); 60 this.name = name; 61 this.price = price; 62 } 63 64 }
4.Map的遍历



5.HashMap的扩容机制
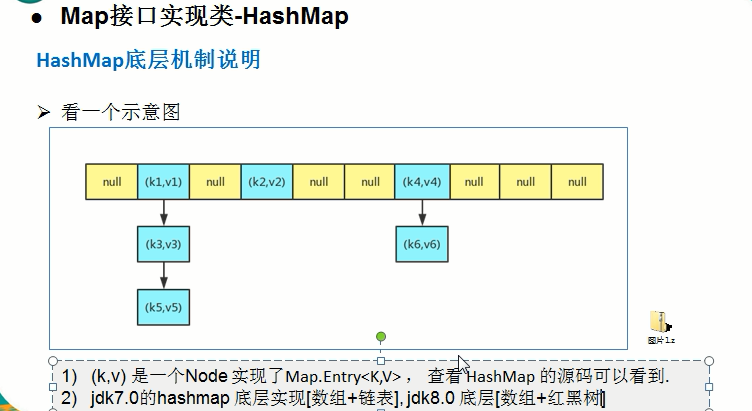


1) ashMap底层维护了Node类型的数组table,默认为null [看源码]
2) 当创建对象时,将加载因子(loadfactor)初始化为0.75.
3) 当添加元素时(调用putVal方法),需要通过该元素的哈希值获取在table中的索引。然后判断该索引处是否有元素,如果没有元素直接添加。如果该索引处有元素,需要继续判断是否相等(equals),如果 相 等,则直接覆盖;如果不相等需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。
4) 如果第一次添加,则需要扩容table容量为16,临界值(threshold)为12.[即使用到12个空间,就要扩容, 公式=table容量* loadfactor = 16 * 0.75 = 12 ]
5) 如果其他次添加,则需要扩容table容量为原来的2倍,临界值为原来的2倍[公式=table容量* loadfactor = 16 * 0.75 = 12]。
6.TreeMap

7. Map接口实现类-Hashtable
HashTable的基本介绍
1) This class implements a hash table[该类实现hashtable]
2) which maps keys to values [元素是键值对]
3) Any non-null object can be used as a key or as a value [hashtable的键和值都不能为null]
4) 所以是从上面看,hashTable 基本上和hashMap一样的.
8.集合的选择

9.Collection工具类

- 查找、替换
1) Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
2) Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
3) Object min(Collection)
4) Object min(Collection,Comparator)
5) int frequency(Collection,Object):返回指定集合中指定元素的出现次数
6) void copy(List dest,List src):将src中的内容复制到dest中
7) boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值