1、字典实例:建立学生学号成绩字典,做增删改查遍历操作。
d={'55':100,'56':80,'57':85,'58':85,'59':66,'60':88}
print(d,'
')
d['61']=77
print('增加61号后的成绩字典为:',d,'
')
d.pop('58')
print('删除58号后的成绩字典为:',d,'
')
d['60']=88
print('修改60号后的成绩字典为:',d,'
')
print('56同学的成绩为:',d['56'],'
')
for i in d:
print('{} {}'.format(i,d[i]))

2、列表,元组,字典,集合的遍历。
li=list('21321233121213231211')
print('列表的遍历是:')
print(li)
for i in li:
print(i)
tu=tuple('12458151545554')
print('元组的遍历是:')
print(tu)
for i in tu:
print(i)
d={'01':100,'02':80,'03':96,'04':99,'05':55,'06':98}
print('字典的遍历是:')
print(d)
for i in d:
print(i,d[i])
s=set([1,2,3,1,2,3,1,2,3,1,1,3])
print('集合的遍历是:')
print(s)
for i in s:
print(i)

列表是Python的一种内置数据类型,list是一种有序的集合,可以随时添加和删除其中的元素。
元组与列表相似,只是tuple一旦定义了就不可修改
字典是另一种可变容器模型,且可存储任意类型对象。
集合是值不能重复的,所以遍历出来的值没有重复值,是无序的。
3、英文词频统计实例
- 待分析字符串
- 分解提取单词
- 大小写 txt.lower()
- 分隔符'.,:;?!-_’
- 单词列表
- 单词计数字典
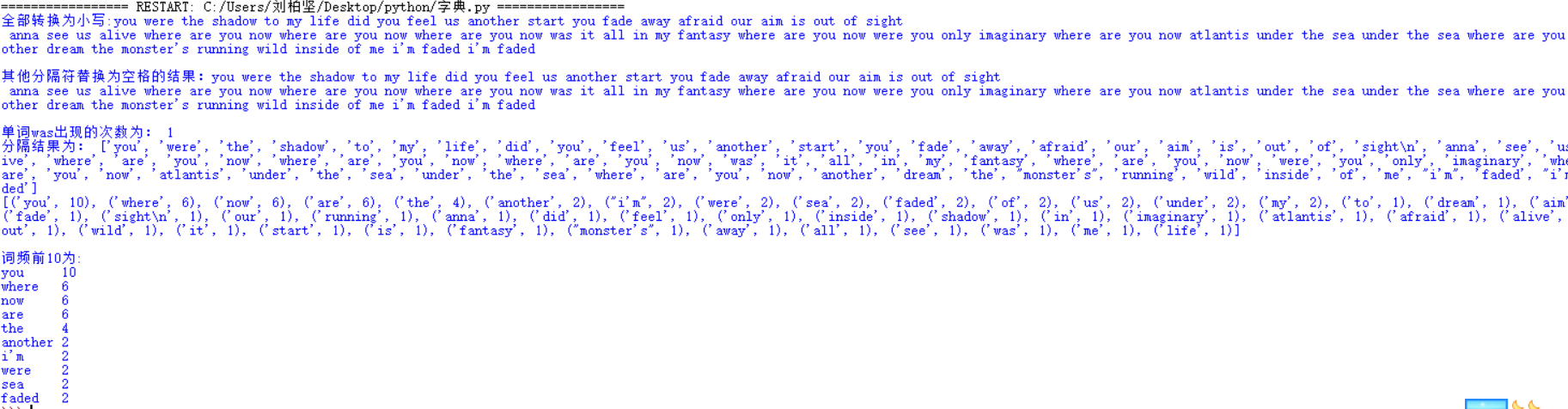
s='''You were the shadow to my life Did you feel us Another start You fade away Afraid our aim is out of sight
anna see us Alive Where are you now Where are you now Where are you now Was it all in my fantasy Where are you now Were you only imaginary Where are you now Atlantis Under the sea Under the sea Where are you now Another dream The monster's running wild inside of me I'm faded I'm faded'''
#将所有大写转换为小写
s=s.lower()
print('全部转换为小写:'+s+'
')
#将所有将所有其他做分隔符(,.?!)替换为空格
for i in ',.?!':
s=s.replace(i,' ')
print('其他分隔符替换为空格的结果:'+s+'
')
#统计单词‘was’出现的次数
count=s.count('was')
print('单词was出现的次数为:',count)
#分隔出一个一个单词
s=s.split(' ')
print('分隔结果为:',s)
word = set(s)
dic={}
for i in word:
dic[i]= s.count(i)
s=list(dic.items())
s.sort(key=lambda x:x[1],reverse=True)
print(s,'
')
print('词频前10为:')
for i in range(10):
word,count=s[i]
print('{} {}'.format(word,count))