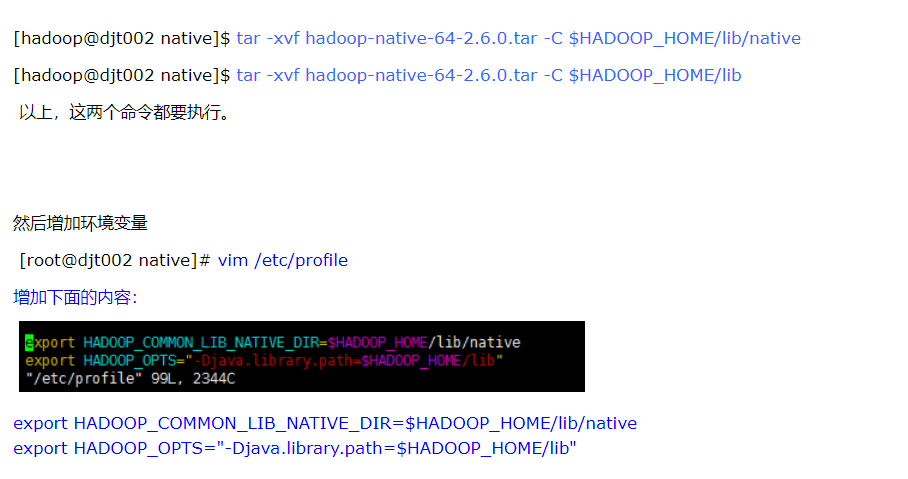
1:修改主机名称 vim /etc/hostname
2:防火墙关闭:ufw disable 关闭 ufw enable 开启防火墙
3:修改完interfaces文档中的内容后,需要修改/etc/NetworkManager/NetworkManager.conf文档中的managed参数,使之为true,并重启。否则,会提示说“有线网络设备未托管”。
4:设置静态ip
vim /etc/netplan/01-network-manager-all.yaml
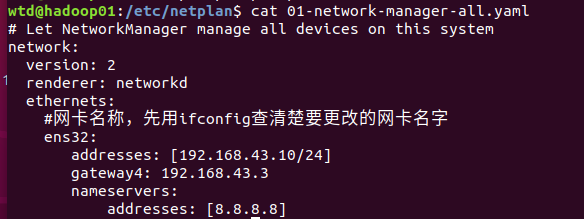
然后 sudo netplan apply 执行修改
address是我的静态ip地址,gateway是win10下面的的网关地址。
5:实现ssh远程的登录
sudo ps -e | grep ssh命令查看当前是否有ssh服务, 有这个即为有服务
有这个即为有服务
没有的话sudo apt-get install openssh-server,此时会遇到错误说 ,
,
然后再进行sudo apt-get install openssh-server,然后就连接上了。。开心
6:Ubuntu的路径显示

7:克隆机器。修改主机名称,修改ip地址,sudo vim /etc/hosts 在这里面增加其他主机的ip地址。
8:将服务器连接起来,做一个集群一键配置
在下面创建一个xsync文件,修改权限777,写入内容
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for((host=1; host<4; host++)); do echo ------------------- hadoop$host -------------- echo -------$pdir/$fname $user@hadoop0$host:$pdir--- rsync -rvl $pdir/$fname $user@hadoop0$host:$pdir done
这样实现了集群的一体化部署。
9:实现集群间SSH授权登录。
ssh-keygen -t rsa 生成自己的密钥和公钥,ssh-copy-id hadoop02 将公钥授权给其他用户,这样的话集群一键部署就不需要一个一个的输入密码了
10:开始配置集群
按照文件上面的来
链接:https://pan.baidu.com/s/13nruwiY-3Il1Qvco9GuyPw
提取码:heiw


4.3.3 集群配置 1. 集群部署规划 表2-3 hadoop102 hadoop103 hadoop104 HDFS NameNode DataNode DataNode SecondaryNameNode DataNode YARN NodeManager ResourceManager NodeManager NodeManager 2. 配置集群 (1)核心配置文件 配置core-site.xml [atguigu@hadoop102 hadoop]$ vi core-site.xml 在该文件中编写如下配置 <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> (2)HDFS配置文件 配置hadoop-env.sh [atguigu@hadoop102 hadoop]$ vi hadoop-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144 配置hdfs-site.xml [atguigu@hadoop102 hadoop]$ vi hdfs-site.xml 在该文件中编写如下配置 <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:50090</value> </property> (3)YARN配置文件 配置yarn-env.sh [atguigu@hadoop102 hadoop]$ vi yarn-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144 找不到JAVA_HOME的话,找到export把#删掉 配置yarn-site.xml [atguigu@hadoop102 hadoop]$ vi yarn-site.xml 在该文件中增加如下配置 <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> (4)MapReduce配置文件 配置mapred-env.sh [atguigu@hadoop102 hadoop]$ vi mapred-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144 找到export把#删掉 配置mapred-site.xml [atguigu@hadoop102 hadoop]$ cp mapred-site.xml.template mapred-site.xml [atguigu@hadoop102 hadoop]$ vi mapred-site.xml 在该文件中增加如下配置 <!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> 3.在集群上分发配置好的Hadoop配置文件 [atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-2.7.2/ 4.查看文件分发情况 [atguigu@hadoop103 hadoop]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
群起配置slaves时候删掉localhost
注意 sbin/start-yarn.sh,资源管理器配置给哪个节点,就从哪个节点上面执行这个语句,切记!!!!!!!!!!!
11:IDEA连接HDFS
12:namenode作用方式:由于NameNode存储元数据的一切信息,
断电就完蛋了,需要有日记记录,以及本地磁盘检查点信息,每次namenode信息点启动之后依据磁盘检查点信息和日记文件恢复元数据信息,然后等待DataNode注册的信息,此时DataNode信息返回节点信息,比如借点有没有坏掉还是啥的提供给NameNode更新操作。日记文件只有追加功能。在NameNode和DataNode节点准备好之前都属于安全模式,只能读。
secondnode:有checkpoint检查点到了一定的时间点或者日记文件存储的信息量达到了一百万条,把NameNode节点里面的日记信息弄一个新的存放新来的操作信息,旧的取过来和磁盘文件进行合并,然后合并好之后返回给NameNode里面的磁盘文件,这样就进行了更新操作。
13:NameNode和DataNode一样都可以拥有多层目录,但是NameNode里面的data1和data2的内容一样,但是DataNode里面的data1和data2内容不一样,就是能设置文件烦旨在不同的文件夹.
14:NameNode里面用150字节存放文件信息元数据,无论文件大小是多大,都是这样子存储的数据。
15:目前见过的协议:http,hdfs协议链接hdfs集群,har:协议翻译小文件打包后的har文件夹 ,同做这个链接来访问文件。
,同做这个链接来访问文件。
16:快照功能:指定目录开启或者禁用快照功能,仅用快照之前必须把当前的快照全都删除才能禁用快照功能,不删除的话不能禁用快照功能。快照的功能比较两个快照之间的不同之处
web端查看HDFS文件系统
http://hadoop101:50070/dfshealth.html#tab-overview
YARN的浏览器页面查看,如图2-35所示
http://hadoop101:8088/cluster
查看JobHistory
http://hadoop101:19888/jobhistory
查看日志,如图2-37,2-38,2-39所示
http://hadoop101:19888/jobhistory
java连接hdfs
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)”/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.7.1.jar和haoop-hdfs-nfs-2.7.1.jar;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
log4j:WARN No appenders could be found for logger (com.netease.qa.testng.TestngRetry).
log4j:WARN Please initialize the log4j system properly.
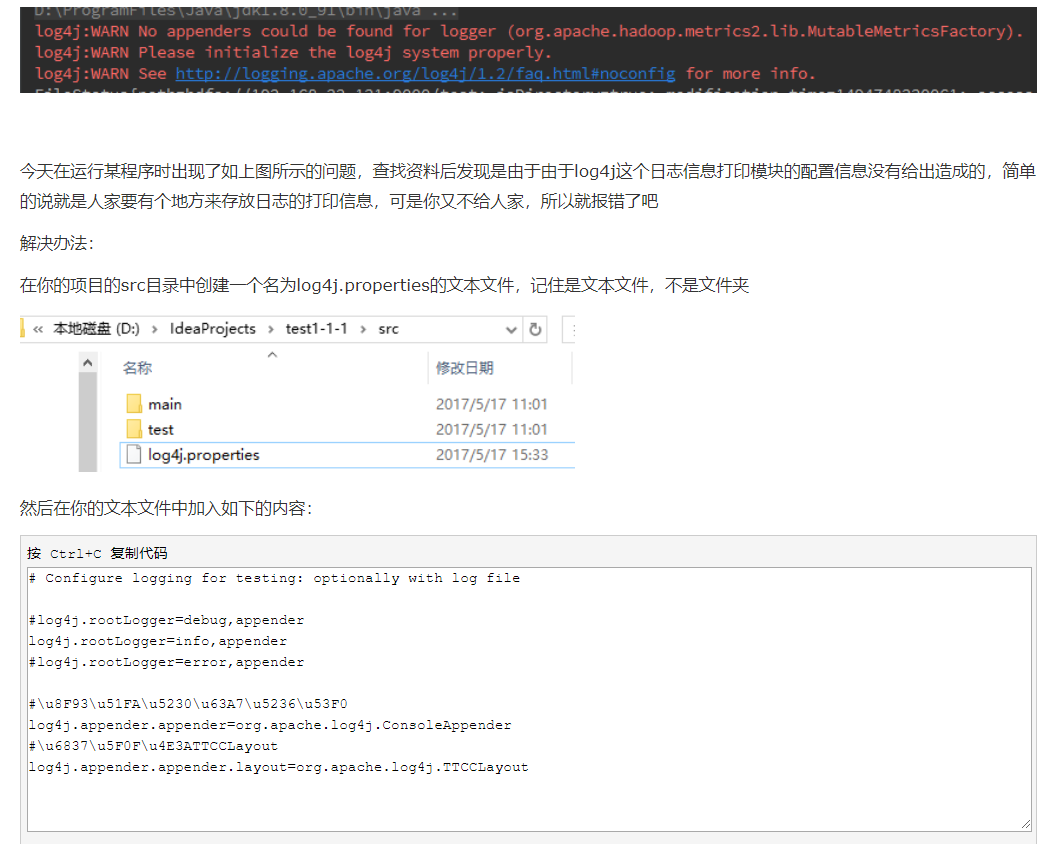
# Configure logging for testing: optionally with log file #log4j.rootLogger=debug,appender log4j.rootLogger=info,appender #log4j.rootLogger=error,appender #u8F93u51FAu5230u63A7u5236u53F0 log4j.appender.appender=org.apache.log4j.ConsoleAppender #u6837u5F0Fu4E3ATTCCLayout log4j.appender.appender.layout=org.apache.log4j.TTCCLayout
BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境。
下面的这个
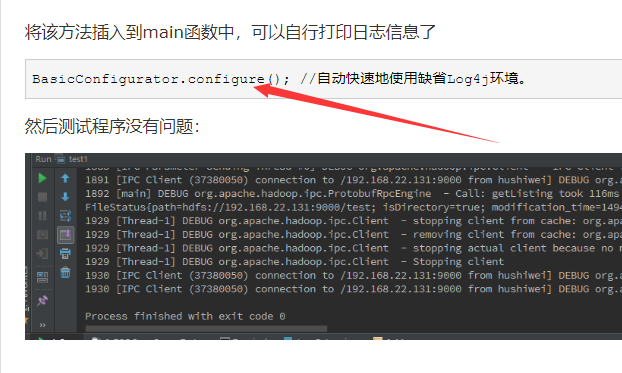
错误信息:Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
下载这个东西:http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.7.0.tar,然后执行下面的指令