爬取豌豆荚的安卓软件信息:
1、主要目的
爬取豌豆荚的软件信息可以了解到什么样的软件是当前最热门的,什么软件是最好的,使用率、好评率是最受欢迎的,人们可以利用这些数据来进行性对性的操作以及分析。作为信息爆炸、软件横行的时代,我们应当对软件的信息由一个更好、更高的了解,也为我们以后的软件的开发作出相对应的路线。所以说爬取安卓软件信息数据的必要性会更加的需要。
2、实现准备阶段
首先先进行对豌豆荚官网中的安卓软件信息进行观察,以及对网站的排版找出相对应的规律,再然后根据需求进行相对应的爬取数据的大概简要,进行初步判断是否可以爬取数据的分析可行性。
对爬取的数据需要分析,要使用第三方软件进行实现,导入的第三方软件有requests、BeautifulSoup、pandas、wordcloud等相应的包,并在python环境下导入以下包。
import requests from bs4 import BeautifulSoup import pandas as pd from PIL import Image import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator
3、实现步骤
获取单个app的详情信息,例如app名字、app安装人数、好评率、评价人数、app链接存储到字典中,这样可以更详细的看出app信息的基本内容,并返回相应的字典信息,这里我定义了一个全局变量字典app,获取APP名字和安装人数,进行生成相对应的词云,更客观的看出app的欢迎程度和使用率;
#获取单个软件的详情
def getappDetail(Url):
res = requests.get(Url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
Software = {}
if len(soup.select('.app-info')) > 0:
Software['软件名字'] = soup.select('.app-name')[0].text # app名
x= soup.select('.num-list')[0].select('span')[0].select('i')[0].text.split("万")# 安装人数
y = soup.select('.num-list')[0].select('span')[0].select('i')[0].text.split("亿")# 安装人数
if len(x)==2:
Software['安装人数']=float(x[0])*10000
if len(y) == 2:
Software['安装人数'] =float(y[0]) * 100000000
if len(x)==1&len(y)==1:
Software['安装人数'] =float(soup.select('.num-list')[0].select('span')[0].select('i')[0].text)
Software['好评率'] = soup.select('.num-list')[0].select('span')[-1].select('i')[0].text # 好评率
Software['软件链接'] = Url # app链接
Software['评价人数'] = int(soup.select('.comment-area')[0].select('i')[0].text) # 评价人数
app[Software['软件名字']] =Software['安装人数']
return (Software)
获取一个列表的中单个app链接进行调用以上的函数,进行相对应的处理,并且定义了一个列表,返回一个列表中的所有app信息列表;
#获取一个列表的app链接
def getListPage(pageUrl):
res = requests.get(pageUrl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
Softwaresum=[]
for n in soup.select('li'):
if len(n.select('.icon-wrap')) > 0:
url = n.select('a')[0].attrs['href'] # app链接
Softwaresum.append(getappDetail(url))
return (Softwaresum)
获取安卓app中网站的页数,处理所有的app信息进行排布;
#获取网站的页数
def getPageN():
res = requests.get('http://www.wandoujia.com/category/5029')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
pagenumber=int(soup.select('.pagination')[0].select('a')[-2].text)
return pagenumber
主函数是来处理第一页的app链接和除了第一页外所有页数的app链接,对获取到的app信息的总列表进行排版,排序以及整合到Excel表中进行更详细的查看信息;生产词云是对安装人数的大小进行对app名字进行排版,这样可以更客观的看app使用的情况。
apptotal=[]
app={}
pageUrl = 'http://www.wandoujia.com/category/5029'
apptotal.extend(getListPage(pageUrl))
n = getPageN()
for i in range(2, n+1):
listPageUrl = 'http://www.wandoujia.com/category/5029/{}'.format(i)
apptotal.extend(getListPage(listPageUrl))
df=pd.DataFrame(apptotal)
dfs=df.sort_index(by='安装人数',ascending=False)
dfs.to_excel('Software.xlsx')
image= Image.open('./豌豆.jpg')
graph = np.array(image)
font=r'C:WindowsFontssimkai.ttf'
wc = WordCloud(font_path=font,background_color='White',max_words=50,mask=graph)
wc.generate_from_frequencies(app)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()
4、实验结果
词云结果图:


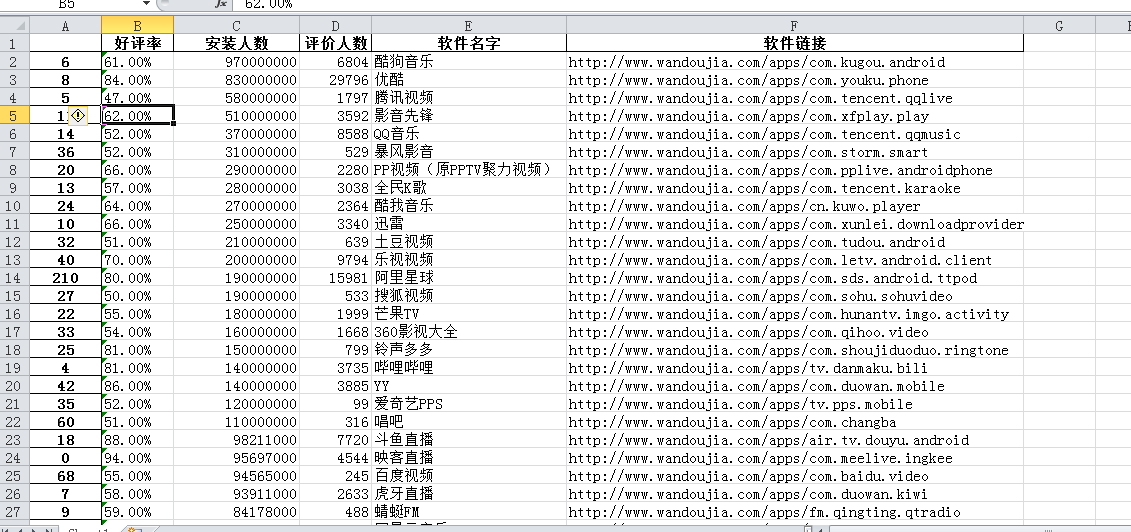
Excel表结果图:
5、遇到的问题及解决办法
a、爬取多个链接时,会出现报错信息,例如有些链接会找不到相对应的app名字中的soup.select('.app-name')[0].text,就会出现报错终止程序;解决办法是利用if语句进行判断上一个div中是否存在,存在则进行处理;
b、读取‘安装人数’中出现了‘万’和‘亿’,导致不能进行判断大小以及不能生成词云的统计;解决办法是分别去除‘万’和‘亿’,分别判断列表中的元素是否为2,为2则强制转浮点型再进行相对应的乘法运算,否则直接强制转为浮点型。
c、导入Wordcloud包时直接在cmd中使用pip install Wordcloud是不能直接安装,解决办法是先安装wordcloud-1.4.1-cp36-cp36m-win32.whl文件 再进行pip就可以了。
d、导入Excel表时排序是小到大的,不符合要求,解决办法是使用ascending为false就可以生成符合要求的大到小的排序。
6、数据分析思想及结论
词云的结果可以看出酷狗音乐、优酷和影音先锋在安卓手机中是最多人安装使用的,可以看得出来它在安卓的受欢迎程度最高;在Excel表中可以详细的看出app中经过安装人数的排序基本信息,有数据的显示更容易让人相信此app的热门度。
在这次爬虫中,让自己更懂得了怎么在网站中爬取自己需要的数据,对爬取的数据进行相对应的分析以及处理,有点不足之处可能是爬取的数据不是太精密或者太核心的,这还需要自己多加学习大数据技术。
7、全部源代码以及全部数据
import requests
from bs4 import BeautifulSoup
import pandas as pd
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
#获取单个软件的详情
def getappDetail(Url):
res = requests.get(Url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
Software = {}
if len(soup.select('.app-info')) > 0:
Software['软件名字'] = soup.select('.app-name')[0].text # app名
x= soup.select('.num-list')[0].select('span')[0].select('i')[0].text.split("万")# 安装人数
y = soup.select('.num-list')[0].select('span')[0].select('i')[0].text.split("亿")# 安装人数
if len(x)==2:
Software['安装人数']=float(x[0])*10000
if len(y) == 2:
Software['安装人数'] =float(y[0]) * 100000000
if len(x)==1&len(y)==1:
Software['安装人数'] =float(soup.select('.num-list')[0].select('span')[0].select('i')[0].text)
Software['好评率'] = soup.select('.num-list')[0].select('span')[-1].select('i')[0].text # 好评率
Software['软件链接'] = Url # app链接
Software['评价人数'] = int(soup.select('.comment-area')[0].select('i')[0].text) # 评价人数
app[Software['软件名字']] =Software['安装人数']
return (Software)
#获取一个列表的app链接
def getListPage(pageUrl):
res = requests.get(pageUrl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
Softwaresum=[]
for n in soup.select('li'):
if len(n.select('.icon-wrap')) > 0:
url = n.select('a')[0].attrs['href'] # app链接
Softwaresum.append(getappDetail(url))
return (Softwaresum)
#获取网站的页数
def getPageN():
res = requests.get('http://www.wandoujia.com/category/5029')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
pagenumber=int(soup.select('.pagination')[0].select('a')[-2].text)
return pagenumber
apptotal=[]
app={}
pageUrl = 'http://www.wandoujia.com/category/5029'
apptotal.extend(getListPage(pageUrl))
n = getPageN()
for i in range(2, n+1):
listPageUrl = 'http://www.wandoujia.com/category/5029/{}'.format(i)
print(listPageUrl)
apptotal.extend(getListPage(listPageUrl))
df=pd.DataFrame(apptotal)
dfs=df.sort_index(by='安装人数',ascending=False)
dfs.to_excel('Software.xlsx')
image= Image.open('./豌豆.jpg')
graph = np.array(image)
font=r'C:WindowsFontssimkai.ttf'
wc = WordCloud(font_path=font,background_color='White',max_words=50,mask=graph)
wc.generate_from_frequencies(app)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()