python基础python的语法比较简单,采用缩进方式

以#号表示注释, 当语句以冒号:结尾时,缩进的语句视为代码块(相当于java程序当中的大括号)
请注意python识别大小写
数据类型和变量:
数据类型:
整数:可以处理任意大小的整数。十六进制的数字前缀加上ox,例如:oxff00等
浮点数:浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数位置是可变的,
字符串:以单引号‘‘或双引号“”括起来的文本,比如‘abc’,注意 ' ' , " "只是一种表示方式,不是字符串的一部分。转义字符为 。
允许 r' '表示' '内的字符串默认不转义。 pritn(r'" ')输出"
布尔值:和布尔代数的表示完全一致,一个布尔值只有True、False两种值,可以进行 and 、not 、or 操作
空值:空值是python里一个特殊的值,用None表示。None不能理解为0,None是一个特殊的空值。
还有 列表、字典等多种类型,可以自定义类型。
变量: 变量在程序中就是用一个变量名表示了,变量名必须是大小写英文、数字和_的组合,且不能用数字开头
a=12 a='123' a=True 同一个变量可以反复赋值,而且可以是不同类型的变量
python的这种变量本身的类型不固定的语言叫动态语言。与之对应的是静态语言,定义时必须指定变量的类型 如java语言
常量 PI=3.14.159
/ 除法最后得到的是浮点数 9/3=3.0 10/3=3.3333333
// 称为地板除 两个整数相除结果为整数 9//3=3,即使是浮点数相除结果是保留整数位的浮点数 10.0//3.0=3.0 10.123//3.12=3
% 取余,得到两个整数相除的余数 10%3
整数运算结果永远是精确的,而浮点数的运算可能会四舍五入
字符串和编码:
字符编码 ASCII码也叫美国标准信息交换码,是一个字节的编码方式
Unicode编码 通常是两个字节的编码方式,如果遇到比较生僻的字,可能需要4个字节
UTf-8编码 可变长的编码格式,可以用1-6个字节编码。英文字母通常一个字节,汉字通常3个字节

UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
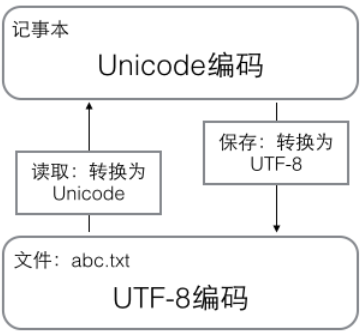
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或需要传输时,就转换为UTF-8编码
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
python字符串
在最新的python3.0中,字符串是以Unicode编码的,也就是说python字符串支持多种语言

字符串函数
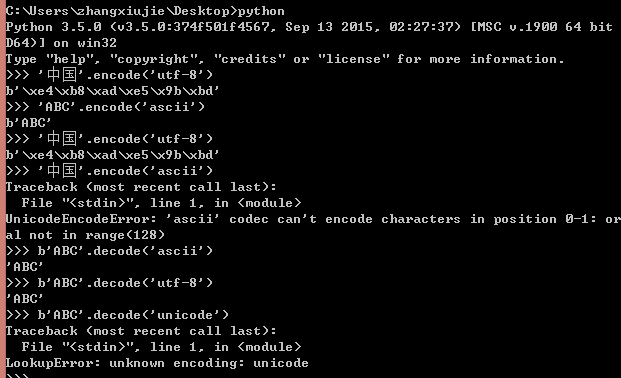
ord()函数获取字符串的整数值,chr() 把编码转换为对应的字符串, len()函数计算字符的个数

encode()函数表述编码操作,把字符串编码为指定格式,decode()函数表示解码操作,把相应的bytes数据解码成指定格式
格式化
python中,采用的格式化方程式和C语言是一致的,用%实现。

%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,%f 表示浮点数替换,%x 表示十六进制整数
有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
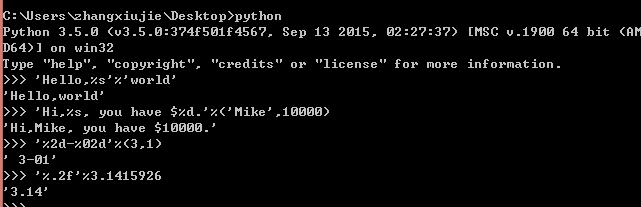
如果不确定应该用什么类型,%s永远适用,它会把任何类型转换为字符串

如果字符串里面%是普通字符呢?这个时候就需要转义,用%%来表示一个%

使用 list和tuple
list:python内置的一种数据类型是列表:list是一种有序的集合,可以随时添加和删除其中的元素
定义一个list集合 classmates=['zhangx','wangb','lings'] 求出list集合中的元素个数=len(classmates)
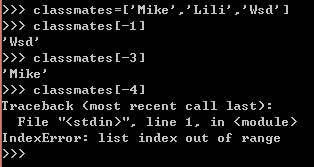
用索引访问list中每一个元素的位置是从零开始的,-1直接获取倒数第一个元素,-2,-3依次类推
list集合的操作函数 append()可以追加元素到末尾,insert(position,element)可以插入元素到指定位置,
pop()可以删除末尾元素,pop(i)可以删除指定位置的元素 。当然可以在list中嵌套list

tuple:另一种有序列表叫元组:tuple。tuple和list非常相似,但是tuple一旦初始化就不能修改
定义classmates=('ss','mm','kk',True), 注意list和tuple一样里面的元素类型可以不一致。
当tuple元组只有一个元素时,定义如下 ss=('mm',),而不是ss=('mm').后者表示的是 把字符串赋给变量ss
