题目:
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
1 2 4 5 6
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
2、数据处理:
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
完成情况:
目前完成了第一,二步。下面拿第二步的第一个来说:
第二步中主要是对数据进行处理,一开始看到这个题目,想到的是用mapreduce一步解决,但是不仅需要将相同id的video/article进行总和得到新的一列数据num,还要对num进行倒顺处理,一步解决难度有些大,所以进行两次mapreduce来对数据进行处理,然后导入hive,查询前十个数据即为所求。
第一个步骤:将相同id的video/article进行总和得到新的一列数据num,并且只保留num与id这两列数据。
1 import java.io.IOException; 2 import org.apache.hadoop.conf.Configuration; 3 import org.apache.hadoop.fs.Path; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Job; 6 import org.apache.hadoop.mapreduce.Mapper; 7 import org.apache.hadoop.mapreduce.Reducer; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 public class text_2_1 { 12 public static class Map extends Mapper<Object,Text,Text,Text>{ 13 private static Text newKey = new Text(); 14 private static Text newvalue = new Text("1"); 15 public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ 16 String line = value.toString(); 17 String arr[] = line.split(" "); 18 newKey.set(arr[5]); 19 context.write(newKey,newvalue); 20 } 21 } 22 public static class Reduce extends Reducer<Text, Text, Text, Text> { 23 private static Text newkey = new Text(); 24 private static Text newvalue = new Text(); 25 protected void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException { 26 int num = 0; 27 for(Text text : values){ 28 num++; 29 } 30 newkey.set(""+num); 31 newvalue.set(key); 32 context.write(newkey,newvalue); 33 } 34 } 35 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 36 Configuration conf = new Configuration(); 37 conf.set("mapred.textoutputformat.separator", " "); 38 System.out.println("start"); 39 Job job=Job.getInstance(conf); 40 job.setJarByClass(text_2_1.class); 41 job.setMapperClass(Map.class); 42 job.setReducerClass(Reduce.class); 43 job.setOutputKeyClass(Text.class); 44 job.setOutputValueClass(Text.class); 45 Path in=new Path("hdfs://localhost:9000/text/in/data"); 46 Path out=new Path("hdfs://localhost:9000/text/out1"); 47 FileInputFormat.addInputPath(job, in); 48 FileOutputFormat.setOutputPath(job, out); 49 boolean flag = job.waitForCompletion(true); 50 System.out.println(flag); 51 System.exit(flag? 0 : 1); 52 } 53 }
第二个步骤,对num进行倒顺处理。因为在MapReduce中默认为正序排序,所以新定义了一个比较的类。
1 import java.io.IOException; 2 import org.apache.hadoop.conf.Configuration; 3 import org.apache.hadoop.fs.Path; 4 import org.apache.hadoop.io.IntWritable; 5 import org.apache.hadoop.io.Text; 6 import org.apache.hadoop.mapreduce.Job; 7 import org.apache.hadoop.mapreduce.Mapper; 8 import org.apache.hadoop.mapreduce.Reducer; 9 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 10 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 11 public class m { 12 public static class Map extends Mapper<Object,Text,IntWritable,Text>{ 13 private static IntWritable newKey = new IntWritable (); 14 private static Text newvalue = new Text (); 15 public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ 16 String line = value.toString(); 17 String arr[] = line.split(" "); 18 newKey.set(Integer.parseInt(arr[0])); 19 newvalue.set(arr[1]); 20 context.write(newKey,newvalue); 21 } 22 } 23 public static class Reduce extends Reducer<IntWritable, Text, IntWritable, Text> { 24 protected void reduce(IntWritable key, Iterable<Text> values, Context context)throws IOException, InterruptedException { 25 for(Text text : values){ 26 context.write(key,text); 27 } 28 } 29 } 30 public static class IntWritableDecreasingComparator extends IntWritable.Comparator 31 { 32 public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) 33 { 34 return -super.compare(b1, s1, l1, b2, s2, l2); 35 } 36 } 37 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 38 Configuration conf = new Configuration(); 39 conf.set("mapred.textoutputformat.separator", " "); 40 System.out.println("start"); 41 Job job=Job.getInstance(conf); 42 job.setJarByClass(m.class); 43 job.setMapperClass(Map.class); 44 job.setReducerClass(Reduce.class); 45 job.setOutputKeyClass(IntWritable.class); 46 job.setOutputValueClass(Text.class); 47 job.setSortComparatorClass(IntWritableDecreasingComparator.class); 48 Path in=new Path("hdfs://localhost:9000/text/out1/part-r-00000"); 49 Path out=new Path("hdfs://localhost:9000/text/out2"); 50 FileInputFormat.addInputPath(job, in); 51 FileOutputFormat.setOutputPath(job, out); 52 boolean flag = job.waitForCompletion(true); 53 System.out.println(flag); 54 System.exit(flag? 0 : 1); 55 } 56 }
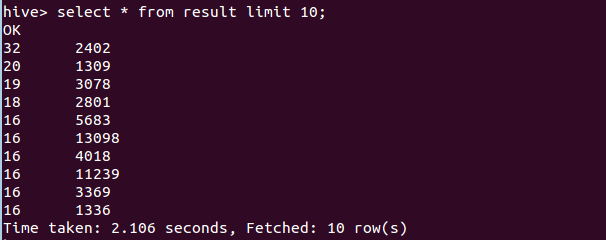
经过了上面两步骤的处理后,得到的数据是这样的:
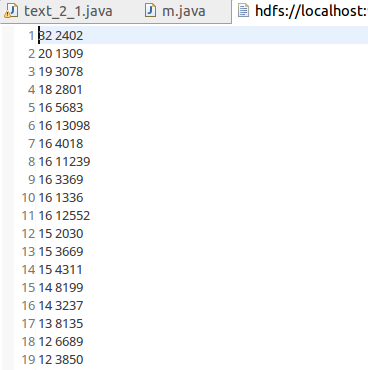
然后将其导入hive数据库,再查询前十行,即为所求。