这次学会了一点抓包的内容,总结一下如何爬取ajax链接中的内容,如果抓包的时候看到有http请求其他的url(text/html) ,很可能就是ajax请求,一般用来获取动态数据,在页面中显示。发出ajax请求的时候 http请求头部一般有这个字段:X-Requested-With:XMLHttpRequest ,不过不一定都有!所谓python模拟ajax请求,实际上就是用python发起http请求,发送这个http请求所需要的数据可以通过抓包获取,构造一个一样的数据发送过去。Ajax的的全称是异步javascript and XML,说的是用javascript调用浏览器后台线程来进行http请求,这样做的好处是不会阻塞浏览器主线程,主要表现就是用户可以继续操作页面,比如鼠标复制页面中的文字等。总之不要纠结Ajax, 它其实就是在浏览器后台线程进行http请求而已。然后看一下爬取的过程:
爬取链接为http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow,打开谷歌浏览器自带的开发者工具进行抓包,当点击下一页的时候,出现了下面的数据:
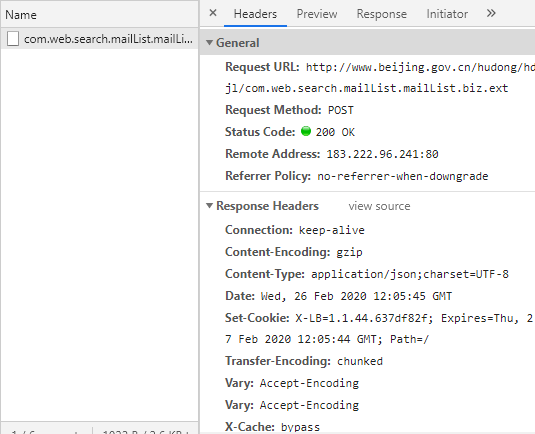
可以看到浏览器发送请求到了http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.mailList.biz.ext,而且请求头部中含有X-Requested-With:XMLHttpRequest字段,再看一下response中的数据:
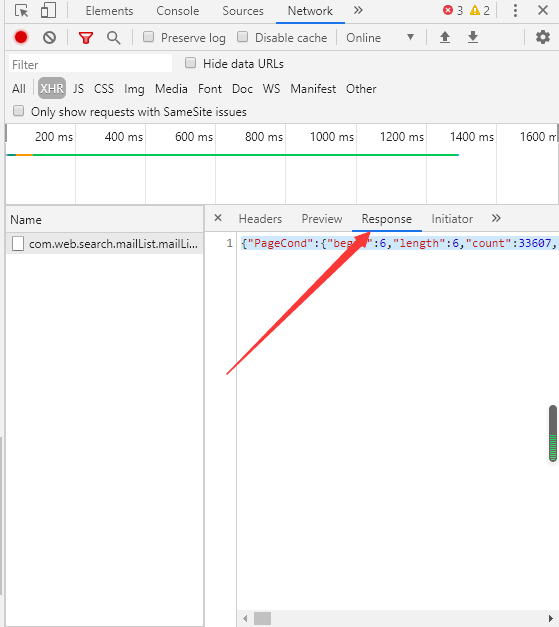
{"PageCond":{"begin":6,"length":6,"count":33607,"totalPage":5602,"currentPage":2,"isCount":true,"isFirst":false,"isLast":false,"size":6},"mailList":[{"letter_type":"咨询","original_id":"AH20022500044","catalog_id":"住房公积金提取","letter_title":"进城务工人员与单位解除劳动关系,还可以申请销户提取住房公积金吗?","create_date":"2020-02-25","org_id":"北京住房公积金管理中心","keywords":null,"letter_status":"L07","ask_same_num":0,"reply_num":0,"support_num":0,"supervise_num":0,"isReply":true},{"letter_type":"咨询","original_id":"AH20022500027","catalog_id":"住房公积金提取","letter_title":"咨询公积金提取问题","create_date":"2020-02-25","org_id":"北京住房公积金管理中心","keywords":null,"letter_status":"L07","ask_same_num":null,"reply_num":null,"support_num":null,"supervise_num":null,"isReply":true},{"letter_type":"咨询","original_id":"AH20022400384","catalog_id":"住房公积金贷款","letter_title":"住房公积金是否可以跨区买房使用?","create_date":"2020-02-24","org_id":"北京住房公积金管理中心","keywords":null,"letter_status":"L07","ask_same_num":null,"reply_num":null,"support_num":null,"supervise_num":null,"isReply":true},{"letter_type":"咨询","original_id":"AH20022400286","catalog_id":"住房公积金提取","letter_title":"之前购买沈阳的住房提取过一次住房公积金,现在还需要提取怎样办理?","create_date":"2020-02-24","org_id":"北京住房公积金管理中心","keywords":null,"letter_status":"L07","ask_same_num":0,"reply_num":0,"support_num":0,"supervise_num":0,"isReply":true},{"letter_type":"咨询","original_id":"AH20022400284","catalog_id":"公积金缴纳","letter_title":"缓缴住房公积金","create_date":"2020-02-24","org_id":"北京住房公积金管理中心","keywords":null,"letter_status":"L07","ask_same_num":null,"reply_num":null,"support_num":null,"supervise_num":null,"isReply":true},{"letter_type":"咨询","original_id":"AH20022400256","catalog_id":"住房公积金贷款","letter_title":"公积金存款为零会不会导致销户或影响后续公积金贷款?","create_date":"2020-02-24","org_id":"北京住房公积金管理中心","keywords":null,"letter_status":"L07","ask_same_num":0,"reply_num":0,"support_num":0,"supervise_num":0,"isReply":true}]}
可知其中包括了我们需要的数据字段,不仅如此,里面PageCond中还包括了返回的数据个数,数据的起始位置等信息;
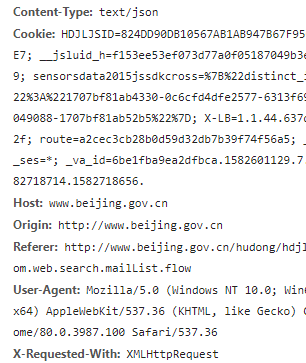
再查看一下请求的preview也就是请求的body:

里面包括了请求所需要的返回的数据个数,所需数据的起始位置等信息,这样我们就可以在设置请求body时规定请求中的这类信息;
附上爬取代码(用到了scrapy框架,需要了解的兄台可以看自学笔记1和2):
# -*- coding: utf-8 -*- import json import scrapy class DemoSpider(scrapy.Spider): name = 'demo' allowed_domains = ['www.beijing.gov.cn'] custom_settings = { #是对settings文件进行覆盖 "DEFAULT_REQUEST_HEADERS": { #DEFAULT_REQUEST_HEADERS用于覆盖settings中headers的内容 # 请求报文可通过一个“Accept”报文头属性告诉服务端 客户端接受什么类型的响应。 'accept': 'application/json, text/javascript, */*; q=0.01', # 指定客户端可接受的内容编码 'accept-encoding': 'gzip, deflate', # 指定客户端可接受的语言类型 'accept-language': 'zh-CN,zh;q=0.9', 'Connection': 'keep-alive', # 就是告诉服务器我参数内容的类型,该项会影响传递是from data还是payload传递 'Content-Type': 'text/json', # 跨域的时候get,post都会显示origin,同域的时候get不显示origin,post显示origin,说明请求从哪发起,仅仅包括协议和域名 'origin': 'http://www.beijing.gov.cn', # 表示这个请求是从哪个URL过来的,原始资源的URI 'referer': 'http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow', # 设置请求头信息User-Agent来模拟浏览器 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36', 'x-requested-with': 'XMLHttpRequest', # cookie也是报文属性,传输过去 'Cookie': 'HDJLJSID = A39ABB5803EDEF95C60A2415C0FE8CC4;X - LB = 1.1.44.637df82f;__jsluid_h = f153ee53ef073d77a0f05187049b3e69;route = a2cec3cb28b0d59d32db7b39f74f56a5;_va_id = 6be1fba9ea2dfbca.1582601129.4.1582616679.1582608434.;_va_ses = *' } } # 需要重写start_requests方法 def start_requests(self): # 网页里ajax链接 url = "http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.mailList.biz.ext" requests = [] for i in range(0, 33750, 1000): my_data = {'PageCond/begin': i, 'PageCond/length': 1000}#这里在设置请求体,两个属性分别为请求获取数据开始的位置和每次获得数据的条数(每次获取数据量最好不要太大) # 模拟ajax发送post请求 request = scrapy.http.Request(url, method='POST', callback=self.parse_model, body=json.dumps(my_data),#json.dumps()是对数据进行编码,形成json格式的数据,这是对请求body的要求 encoding='utf-8') requests.append(request) return requests def parse_model(self, response): # 可以利用json库解析返回来得数据 jsonBody = json.loads(response.text) size = jsonBody['PageCond']['size'] data = jsonBody['mailList'] listdata = {} fb = open('result.txt', 'a', encoding='utf-8') for i in range(size): listdata['letter_type'] = data[i]['letter_type'] # 信访类型 listdata['letter_title'] = data[i]['letter_title'] # 信访标题 listdata['create_date'] = data[i]['create_date'] # 信访时间 listdata['org_id'] = data[i]['org_id'] # 回复单位 fb.write(listdata['letter_type'] + ",") fb.write(listdata['letter_title'] + ",") fb.write(listdata['create_date'] + ",") fb.write(listdata['org_id']) fb.write(' ')
爬取结果:

python小白的第一次抓包。。。