HashTable的特点
HashTable继承自Dictionary类,Dictionary 类是一个抽象类,在JDK 1.0中提供用来存储键/值对,作用和Map类相似。

HashTable类中,其数据结构与HashMap是相同的。依然是采用“链地址法”实现的哈希表,保存实际数据的,依然是Entry对象。
Entry<K,V> implements Map.Entry<K,V> {
int hash;
final K key;
V value;
Entry<K,V> next;
}
和HashMap很类似
不同点:
1、HashTable是线程安全的(synchronized),HashMap线程不安全
2、HashTable是key和value不能为null,而HashMap允许key和value为空。
3、使用的迭代器不同,Hashtable的迭代器(enumerator)。
put方法
put方法的主要逻辑如下:
1. 先获取synchronized锁。
2. put方法不允许null值,如果发现是null,则直接抛出异常(key和value都不能为null)。
3. 计算key的哈希值和index
4. 遍历对应位置的链表,如果发现已经存在相同的hash和key,则更新value,并返回旧值。
5. 如果不存在相同的key的Entry节点,则增加节点。在新增节点时,考虑是否需要扩容,如果需要则进行扩容,之后添加新节点到链表头部。
rehash扩容方法
数组长度增加一倍((oldCapacity << 1) + 1)(如果超过上限,则设置成上限值)。
更新哈希表的扩容限值。
遍历旧表中的节点,计算在新表中的index,插入到对应位置链表的头部
get方法
1. 先获取synchronized锁。
2. 计算key的哈希值和index。
3. 在对应位置的链表中寻找具有相同hash和key的节点,返回节点的value。
4. 如果遍历结束都没有找到节点,则返回null。
remove方法
1. 先获取synchronized锁。
2. 计算key的哈希值和index。
3. 在对应位置的链表中寻找具有相同hash和key的节点,将该key对应的节点从当前链表中删除。
4. 如果遍历结束都没有找到节点,则返回null。
LinkedHashMap
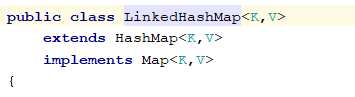
继承自HashMap。
适用场景:
存储的数据是键值对,且需要保证数据按插入顺序有序的话需要使用LinkedHashMap。
数据存储结构
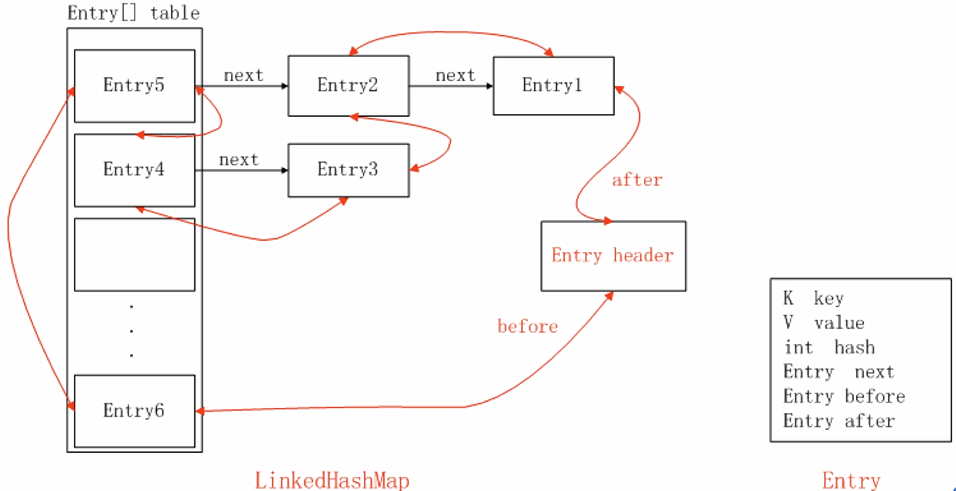
重写了void init()方法:
void init() { //创建了一个hash=-1,key,value,next都为null的Entry header = new Entry<>(-1, null, null, null); //让创建的Entry的before和after都指向自身(其实就是创建了一个职业头部节点的双向链表) header.before = header.after = header; }
属性:accessOrder (默认是false)
true:按照访问顺序组织数据
false: 按照插入顺序组织数据
当accessOrder属性为默认时,进行get操作:
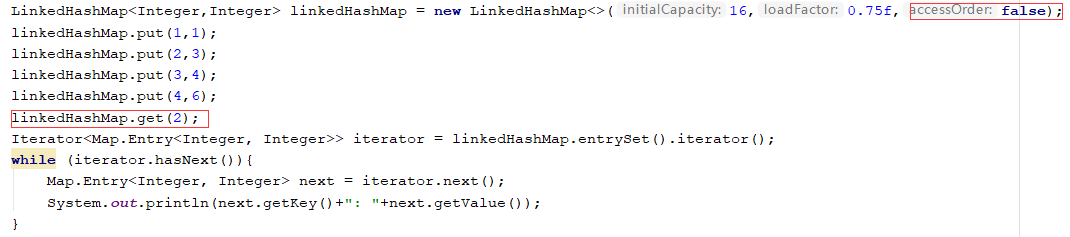
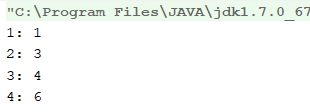
当accessOrder属性为true时,进行get操作:(会按照访问得顺序重新排列)
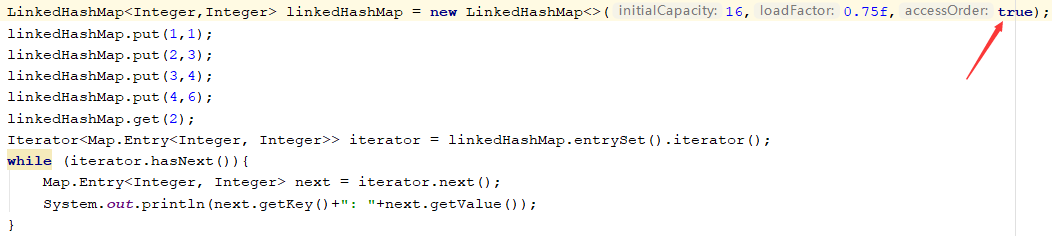
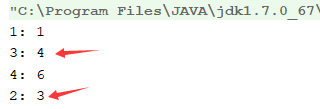
put方法(重要)
它么有重写put方法,只是重写了 void addEntry(),void createEntry(),这两方法,从而实现它的双链表结构。
public V put(K key, V value) { //先判断当前的Entry[] 数组是否为空数组 if (table == EMPTY_TABLE) { inflateTable(threshold); //如果为空,对表进行初始化 } //判断key键是否为空 if (key == null) return putForNullKey(value); //在HashMap中允许value值为空 int hash = hash(key); //计算key的hash值 int i = indexFor(hash, table.length); //通过哈希值和当前的数据长度,计算出在数组的存放位置 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果计算的hash值位置有值,并且key值相同,覆盖原来的value,将原值返回 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); //存放值的具体实现,LinkedHashMap重写了其方法 return null; } //重写 void addEntry(int hash, K key, V value, int bucketIndex) { super.addEntry(hash, key, value, bucketIndex);//先调用父类的方法 //删除最近最少使用元素的策略定义 // Remove eldest entry if instructed Entry<K,V> eldest = header.after; if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key); } } //调用的父类的addEntry()方法 void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex);//将新元素以双向链表的形式加入 } //重写 void createEntry(int hash, K key, V value, int bucketIndex) { HashMap.Entry<K,V> old = table[bucketIndex]; Entry<K,V> e = new Entry<>(hash, key, value, old); table[bucketIndex] = e; e.addBefore(header); // 调用元素的addBrefore方法,将元素加入到哈希、双向链接列表。 size++; }
以上部分源码基于JDK1.7。