正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。
在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
得到正向索引的结构如下:
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。

一般是通过key,去找value。
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
注意这个打分模型,是可以自己设置调节的,在倒排索引当中,也有相应的打分模型,打分模型的打分决定了这些文档的排列先后顺序 ,也就是在那个链表中的先后位置,
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。

从词的关键字,去找文档。
单词——文档矩阵
单词-文档矩阵是表达两者之间所具有的一种包含关系的概念模型,图1展示了其含义。图3-1的每列代表一个文档,每行代表一个单词,打对勾的位置代表包含关系。
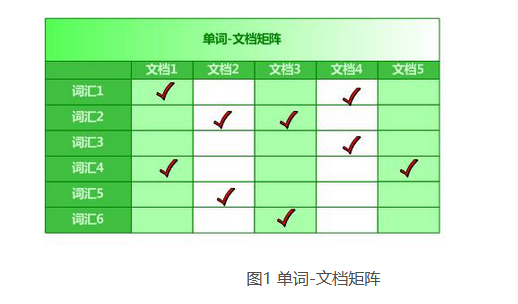
从纵向即文档这个维度来看,每列代表文档包含了哪些单词,比如文档1包含了词汇1和词汇4,而不包含其它单词。从横向即单词这个维度来看,每行代表了哪些文档包含了某个单词。比如对于词汇1来说,文档1和文档4中出现过单词1,而其它文档不包含词汇1。矩阵中其它的行列也可作此种解读。
搜索引擎的索引其实就是实现“单词-文档矩阵”的具体数据结构。可以有不同的方式来实现上述概念模型,比如“倒排索引”、“签名文件”、“后缀树”等方式。但是各项实验数据表明,“倒排索引”是实现单词到文档映射关系的最佳实现方式,所以本博文主要介绍“倒排索引”的技术细节。
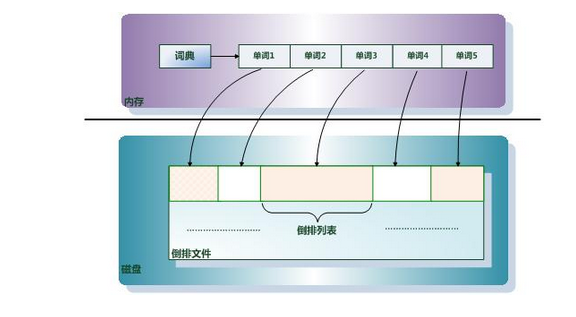
倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
关于这些概念之间的关系,通过图2可以比较清晰的看出来。
问题:ES 倒排索引,内部的链表以什么排序
回答: 根据打分模型的打分进行排序。每条记录有一个score 参数,带有很多小数的double类型,可以看到具体的打分,影响这个打分的有单词在这个文档中出现的位置,出现的频率次数等众多参数。