1 函数的定义
函数是一段具有特定功能的、可复用的语句组。python中函数用函数名来表示,并通过函数名进行功能调用。它是一种功能抽象,与黑盒类似,所以只要了解函数的输入输出方式即可,不用深究内部实现原理。函数的最突出优点是:
- 实现代码复用:减少重复性工作
- 保证代码一致:只需要修改该函数代码,则所有调用均能受影响
在python中可以把函数分为:系统自带函数、第三方库函数、自定义函数。需要重点掌握的是「自定义函数」。
自定义函数
自定义函数语法:
def 函数名([参数列表]):
函数体
return语句
# 示例
def add1(x):
x = x + 1
return x
函数通过「参数」和「返回值」来传递信息,并通过「参数列表」和「return语句」实现对两者的控制,详见下图:

注意事项:
- 函数定义时无需声明形参类型(由调用时的实参类型确定);也无需指定返回值类型(由return语句确定)
- 自定义函数即使没有任何参数,也必须保留一队空括号()
- 括号后面的冒号(:)必不可少
- 函数体相对于def关键字必须有缩进关系
- python允许嵌套定义函数
- return语句作用是结束函数调用,并将结果返回给调用者
- return语句是可选的,可以出现在函数体任意位置
- 无return语句、有return语句没有执行、有return语句而没有返回值三种情况,函数都返回None
2 函数的调用
在定义好函数之后,有两种方式对其进行调用:
- 从本文件调用:直接使用函数名 + 传入参数,如add1(9)
- 从其他文件调用:这种方法有两种实现手段
- 先指定文件路径 + import 文件名,再用文件名.函数名(参数列表)调用
- 先指定文件路径 + from 文件名 import 函数名,再用文件名.函数名(参数列表)调用
# 从本文件调用
def add1(x):
x = x+2
return x
add1(10)
# 从其他文件调用:从名为addx的文件调用已经定义好的add1函数
import os
os.chdir('D:\data\python_file')
# 从其他文件调用方法1
import addx
addx.add1(4)
# 从其他文件调用方法2
from addx import add1
add1(9)
3 函数的参数
3.1 形参与实参
从上面可知,函数最重要的三部分就是参数、函数体、返回值,而参数分为形参和实参:
- 形参:定义函数时,函数名后面圆括号中的变量
- 实参:调用函数时,函数名后面圆括号中的变量
注意事项:
- 形参只在函数内部有效,一个函数可以没有形参,但必须有括号()
- 通常修改形参不影响实参;但如果传递给函数的是「可变序列」(列表、字典、集合),修改形参会影响实参
def printmax(a,b): # a, b是形参
if a>b:
print(a)
printmax(3,4) # 3, 4是实参
# 形参修改不影响实参
def add2(x):
x = x+2
return x
x = 10
print(add2(x))
print(x)
# 形参修改影响实参
def add2(x):
x.append(2)
return x
y = [1, 1] # 实参y是变序列(列表、字典、集合)
print(add2(y)) # 函数返回值
print(y) # 修改形参影响实参
3.2 参数的传递
在定义函数时无需指定形参类型,在调用函数时,python会根据实参类型来自动推断。而定义函数和调用函数的过程,可以简化为下面图中三步,实质就是通过参数和返回值传递信息,而参数的传递发生在第一和第三步。
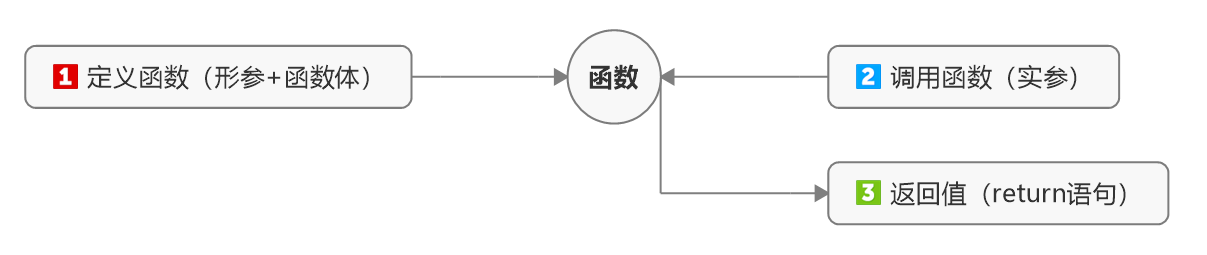
函数参数多种多样,根据参数传递发生的先后顺序,可以从两个角度学习常见的一些参数:
- 定义函数(形参):默认值参数、可变参数
- 调用函数(实参):位置参数、关键字参数、命名关键字参数
同时,这些参数可以组合使用(可变参数无法和关键字参数组合),且参数定义的顺序从左至右分别是:位置参数 >> 默认值参数 >> 可变参数 / 关键字参数 / 命名关键字参数。参数传递还有一种高级用法——参数传递的序列解包。
3.2.1 默认值参数
默认参数就是在调用函数的时候使用一些包含默认值的参数。
# 默认值参数b=5, c=10
def demo(a, b=5, c=10):
print(a, b, c)
demo(1, 2)
注意事项:
- 默认值参数必须出现在参数列表最右端
- 调用带有默认值参数的函数时,可以对默认值参数进行赋值,也可以不赋值
- 默认值参数只能是不可变对象,使用可变序列作为参数默认值时,程序会有逻辑错误
- 可以使用 “函数名.defaults” 查看该函数所有默认参数的当前值
3.2.2 可变参数
可变参数就是允许在调用参数的时候传入多个(≥0个)参数,可变参数分为两种情况:
- 可变位置参数:定义参数时,在前面加一个*,表示这个参数是可变的,可以接受任意多个参数,这些参数构成一个「元组」,只能通过位置参数传递
- 可变关键字参数:定义参数时,在前面加**,表示这个参数可变,可以接受任意多个参数,这些参数构成一个「字典」,只能通过关键字参数传递
# 可变位置参数
def demo(*p):
print(p)
demo(1, 2, 3) # 参数在传入时被自动组装成一个元组
# 可变关键字参数
def demo(**p):
print(p)
demo(b='2', c='5', a='1') # 参数在传入时被自动组装成一个字典
3.2.3 位置参数
位置参数特点是调用函数时,要保证实参和形参的顺序一致、数量相同。
# 位置参数
def demo(a, b, c):
print(a, b, c)
demo(1, 2, 3)
3.2.4 关键字参数
关键字参数允许在调用时以字典形式传入0个或多个参数,且在传递参数时用等号(=)连接键和值。关键字参数最大优点,就是使实参顺序可以和形参顺序不一致,但不影响传递结果。
# 关键参数
def demo(a, b, c):
print(a, b, c)
demo(b=2, c=5, a=1) # 改变参数顺序对结果不影响
3.2.5 命名关键字参数
命名关键字参数是在关键字参数的基础上,限制传入的的关键字的变量名。和普通关键字参数不同,命名关键字参数需要一个用来区分的分隔符*,它后面的参数被认为是命名关键字参数。
# 这里星号分割符后面的city、job是命名关键字参数
def person_info(name, age, *, city, job):
print(name, age, city, job)
person_info("Alex", 17, city="Beijing", job="Engineer")
3.2.6 参数传递的序列解包
参数传递的序列解包,是通过在实参序列前加星号(*)将其解包,然后按顺序传递给多个形参。根据解包序列的不同,可以分为如下5种情况:
| 序列解包 | 示例 |
|---|---|
| 列表的序列解包 | *[3,4,5] |
| 元组的序列解包 | *(3,4,5) |
| 集合的序列解包 | *{3,4,5} |
| 字典的键的序列解包 | 若字典为dic={'a':1,'b':2,'c':3},则解包代码为:*dic |
| 字典的值的序列解包 | 若字典为dic={'a':1,'b':2,'c':3},则解包代码为:*dic.values() |
注意事项:
- 对实参序列进行序列解包后,得到的实参值就变成了位置参数,要和形参一一对应
- 当序列解包和位置参数同时使用时,序列解包相当于位置参数,且会优先处理
- 序列解包不能在关键字参数解包之后,否则报错
"""函数参数的序列解包"""
def demo(a, b, c):
print(a+b+c)
demo(*[3, 4, 5]) # 列表的序列解包
demo(*(3, 4, 5)) # 元组的序列解包
demo(*{3, 4, 5}) # 集合的序列解包
dic = {'a': 1, 'b': 2, 'c': 3}
demo(*dic) # 字典的键的序列解包
demo(*dic.values()) # 字典的值的序列解包
"""位置参数和序列解包同时使用"""
def demo(a, b, c):
print(a, b, c)
demo(*(1, 2, 3)) # 元组的序列解包
demo(1, *(2, 3)) # 位置参数和序列解包同时使用
demo(c=1, *(2, 3)) # 序列解包相当于位置参数,优先处理,正确用法
demo(*(3,), **{'c': 1, 'b': 2}) # 序列解包必须在关键字参数解包之前,正确用法
4 全局变量与局部变量
变量起作用的代码范围称为「变量的作用域」。不同作用域内变量名可以相同,但互不影响。从变量作用的范围分类,可以把变量分类为:
- 全局变量:指函数之外定义的变量,在程序执行全过程有效
- 局部变量:指在函数内部使用的变量,仅在函数内部有效,当函数退出时变量将不存在
需要特别指出的是,局部变量的引用比全局变量速度快,应考虑优先使用。
全局变量声明
有两种方式可以声明全局变量:
- 方式一:在函数外声明
- 方式二:在函数内部用global声明,又分为两种情况:
- 情况1:变量已在函数外定义,使用global声明。若进行了重新赋值,则赋值结果会覆盖原变量值
- 情况2:变量未在函数外定义,使用global在函数内部声明,它将增加为新的全局变量
特殊情况,若局部变量和全局变量同名,那么全局变量会在局部变量的作用域内被隐藏掉。
d = 2 # 全局变量
def func(a, b):
c = a*b
return c
func(2, 3)
def func(a, b):
c = a*b
d = 2 # 局部变量
return c
func(2, 3)
"""声明的全局变量,已在函数外定义"""
n = 1
def func(a, b):
global n
n = b
c = a*b
return c
s = func("knock~", 2)
print(s, n)
"""声明的全局变量,未在函数外定义,则新增"""
def func(a, b):
c = a*b
global d # 声明d为全局变量
d = 2
return c
func(2, 3)
"""局部变量和全局变量同名,则全局变量在函数内会被隐藏"""
d = 10 # 全局变量d
def func(a, b):
d = 3 # 局部变量d
c = a+b+d
return c
func(1, 2)
d
5 lambda函数
lambda函数,又称匿名函数,即没有函数名字临时使用的小函数。其语法如下:
lambda 函数参数:函数表达式
注意:
- 匿名函数只能有一个表达式
- 该表达式的结果,就是函数的返回值
- 不允许包含其他复杂语句,但表达式中可以调用其他函数
lambda函数的使用场景,主要在两方面:
- 尤其适用于需要一个函数作为另一个函数参数的场合,比如排序
- 把匿名函数赋值给一个变量,再利用变量来调用该函数
def f(x, y, z):
return x+y+z # 位置参数
f(1, 2, 3)
def f1(x, y=10, z=10):
return x+y+z # 默认值参数
f(1)
"""把匿名函数赋值给一个变量,再利用变量来调用该函数,作用等价于自定义函数"""
f=lambda x,y,z:x+y+z
f(y=1,x=2,z=3) #关键值参数
L = ['ab', 'abcd', 'dfdfdg', 'a']
L.sort(key=lambda x: len(x)) # 按长度排序
L
L=[('小明',90,80),('小花',70,90),('小张',98,99)]
L.sort(key=lambda x:x[1],reverse=True) # 降序排序
L
6 递归
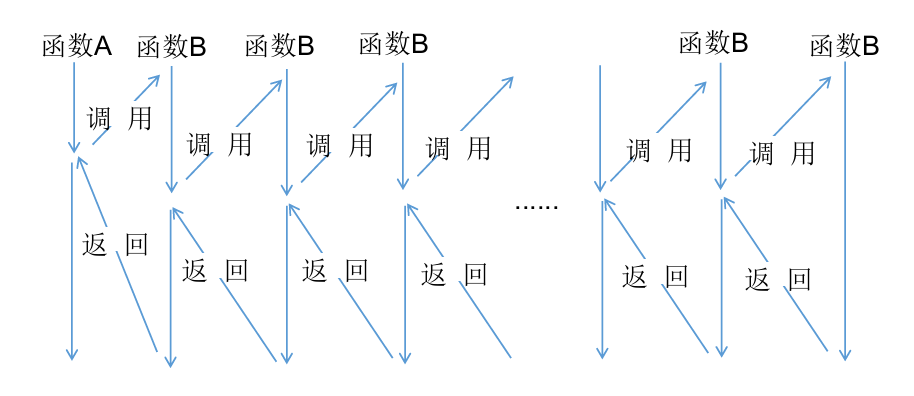
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。但不是的函数调用自己都是递归,递归有其自身的特性:
- 必须有一个明确的递归结束条件,称为递归出口(基例)
- 相邻两次重复之间有紧密的联系,前一次要为后一次做准备(通常前一次的输出就作为后一次的输入)
- 每一次递归,整体问题都要比原来减小,并且递归到一定层次时,要能直接给出结果
从上图可知,递归过程是函数调用自己,自己再调用自己,...,当某个条件得到满足(基例)的时候就不再调用,然后再一层一层地返回,直到该函数的第一次调用。递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出,在Python中,通常情况下,这个深度是1000层,超过将抛出异常。
案例:用递归实现阶乘
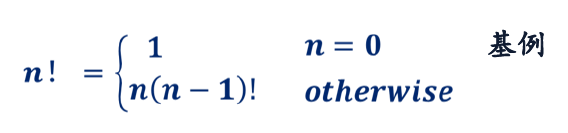
# 案例一:用递归实现阶乘
def fact(n):
if n==0:
return 1
else:
return n*fact(n-1)
fact(5)
# 案例二:实现字符串反转
# 方法1,先转成列表,调用列表的revers方法,再把列表转成字符串
s = 'abcde'
l = list(s)
l.reverse()
''.join(l)
# 方法2,切片的方法
s = 'abcde'
s[::-1]
# 方法3,递归的方法
s = 'abc'
def reverse1(s):
if s == '':
return s
else:
print(s)
return reverse1(s[1:])+s[0]
reverse1(s)