《C++ Primer 4th》读书笔记
相对于小的程序员团队所能开发的系统需求而言,大规模编程对程序设计语言的要求更高。大规模应用程序往往具有下列特殊要求:
1. 更严格的正常运转时间以及更健壮的错误检测和错误处理。错误处理经常必须跨越独立开发的多个子系统进行。
2. 能够用各种库(可能包含独立开发的库)构造程序。
3. 能够处理更复杂的应用概念。
C++ 中有下列三个特征分别针对这些要求:异常处理、命名空间和多重继承。
异常处理
通过异常我们能够将问题的检测和问题的解决分离,这样程序的问题检测部分可以不必了解如何处理问题。
异常是通过抛出对象而引发的。该对象的类型决定应该激活哪个处理代码。被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那个。
执行 throw 的时候,不会执行跟在 throw 后面的语句,而是将控制从 throw转移到匹配的 catch,该 catch 可以是同一函数中局部的 catch,也可以在直接或间接调用发生异常的函数的另一个函数中。
因为在处理异常的时候会释放局部存储,所以被抛出的对象就不能再局部存储,而是用 throw 表达式初始化一个称为异常对象的特殊对象。异常对象由编译器管理,而且保证驻留在可能被激活的任意 catch 都可以访问的空间。这个对象由 throw 创建,并被初始化为被抛出的表达式的副本。异常对象将传给对应的 catch,并且在完全处理了异常之后撤销。
异常对象通过复制被抛出表达式的结果创建,该结果必须是可以复制的类型。
在实践中,许多应用程序所抛出的表达式,基类型都来自某个继承层次。当抛出一个表达式的时候,被抛出对象的静态编译时类型将决定异常对象的类型。
抛出指针通常是个坏主意:抛出指针要求在对应处理代码存在的任意地方存在指针所指向的对象。
栈展开(stack unwinding),沿嵌套函数调用链继续向上,直到为异常找到一个 catch 子句。
因异常而退出函数时,编译器保证适当地撤销局部对象。每个函数退出的时候,它的局部存储都被释放,在释放内存之前,撤销在异常发生之前创建的所有对象。如果局部对象是类类型的,就自动调用该对象的析构函数。
析构函数应该从不抛出异常
栈展开期间会经常执行析构函数。在执行析构函数的时候,已经引发了异常但还没有处理它。如果在这个过程中析构函数本身抛出新的异常,又会发生什么呢?新的异常应该取代仍未处理的早先的异常吗?应该忽略析构函数中的异常吗?
答案是:在为某个异常进行栈展开的时候,析构函数如果又抛出自己的未经处理的另一个异常,将会导致调用标准库 terminate 函数。一般而言,terminate函数将调用 abort 函数,强制从整个程序非正常退出。
因为 terminate 函数结束程序,所以析构函数做任何可能导致异常的事情通常都是非常糟糕的主意。在实践中,因为析构函数释放资源,所以它不太可能抛出异常。标准库类型都保证它们的析构函数不会引发异常。
未捕获的异常终止程序
不能不处理异常。异常是足够重要的、使程序不能继续正常执行的事件。如果找不到匹配的 catch,程序就调用库函数 terminate。
捕获异常
catch 子句中的异常说明符看起来像只包含一个形参的形参表,异常说明符是在其后跟一个(可选)形参名的类型名。
当 catch 为了处理异常只需要了解异常的类型的时候,异常说明符可以省略形参名;如果处理代码需要已发生异常的类型之外的信息,则异常说明符就包含形参名,catch 使用这个名字访问异常对象。
在查找匹配的 catch 期间,找到的 catch 不必是与异常最匹配的那个catch,相反,将选中第一个找到的可以处理该异常的 catch。因此,在 catch 子句列表中,最特殊的 catch 必须最先出现。
除下面几种可能的区别之外,异常的类型与 catch 说明符的类型必须完全匹配:
• 允许从非 const 到 const 的转换。也就是说,非 const 对象的 throw可以与指定接受 const 引用的 catch 匹配。
• 允许从派生类型型到基类类型的转换。
• 将数组转换为指向数组类型的指针,将函数转换为指向函数类型的适当指针
进入 catch 的时候,用异常对象初始化 catch 的形参。异常对象本身是被抛出对象的副本。是否再次将异
常对象复制到 catch 位置取决于异常说明符类型。
如果说明符不是引用,就将异常对象复制到 catch 形参中,catch 操作异常对象的不可一世,对形参所做的任何改变都只作用于副本,不会作用于异常对象本身。如果说明符是引用,则像引用形参一样,不存在单独的 catch 对象,catch 形参只是异常对象的另一名字。对 catch 形参所做的改变作用于异常对象。
基类的异常说明符可以用于捕获派生类型的异常对象,而且,异常说明符的静态类型决定 catch 子句可以执行的动作。如果被抛出的异常对象是派生类类型的,但由接受基类类型的 catch 处理,那么,catch 不能
使用派生类特有的任何成员。通常,如果 catch 子句处理因继承而相关的类型的异常,它就应该将自己的形参定义为引用。
带有因继承而相关的类型的多个 catch 子句,必须从最低派生类类到最高派生类型排序。
重新抛出
重新抛出是后面不跟类型或表达式的一个 throw:
throw;
空 throw 语句将重新抛出异常对象,它只能出现在 catch 或者从 catch调用的函数中。如果在处理代码不活动时碰到空 throw,就调用 terminate 函数。
虽然重新抛出不指定自己的异常,但仍然将一个异常对象沿链向上传递,被抛出的异常是原来的异常对象,而不是 catch 形参。
一般而言,catch 可以改变它的形参。在改变它的形参之后,如果 catch 重新抛出异常,那么,只有当异常说明符是引用的时候,才会传播那些改变。
catch (my_error &eObj) { // specifier is a reference type eObj.status = severeErr; // modifies the exception object throw; // the status member of the exception object is severeErr } catch (other_error eObj) { // specifier is a nonreference type eObj.status = badErr; // modifies local copy only throw; // the status member of the exception rethrown is unchanged }
捕获所有异常的处理代码
因为不可能知道可能被抛出的所有异常,所以可以使用捕获所有异常 catch 子句的。捕获所有异常的 catch 子句形式为 (...)。例如:
void manip() { try { // actions that cause an exception to be thrown } catch (...) { // work to partially handle the exception throw; } }
如果 catch(...) 与其他 catch 子句结合使用,它必须是最后一个,否则,任何跟在它后面的 catch 子句都将不能被匹配。
构造函数要处理来自构造函数初始化式的异常,唯一的方法是将构造函数编写为函数测试块。
template <class T> Handle<T>::Handle(T *p) try : ptr(p), use(new size_t(1)) { // empty function body } catch(const std::bad_alloc &e) { handle_out_of_memory(e); }
标准exception 类层次
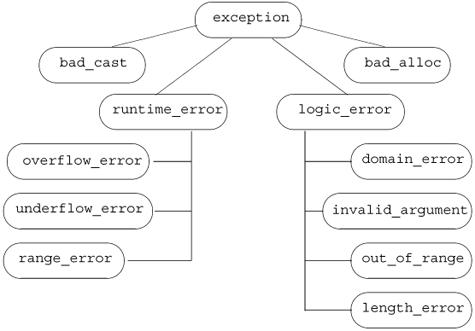
exception 类型所定义的唯一操作是一个名为 what 的虚成员,该函数返回const char* 对象,它一般返回用来在抛出位置构造异常对象的信息。因为 what是虚函数,如果捕获了基类类型引用,对 what 函数的调用将执行适合异常对象的动态类型的版本。
用类管理资源分配
异常安全的意味着,即使发生异常,程序也能正确操作。在这种情况下,“安全”来自于保证“如果发生异常,被分配的任何资源都适当地释放”。
通过定义一个类来封闭资源的分配和释放,可以保证正确释放资源。这一技术常称为“资源分配即初始化”,简称 RAII。
应该设计资源管理类,以便 构造函数分配资源而析构函数释放资源。想要分配资源的时候,就定义该类类型的对象。如果不发生异常,就在获得资源的对象超出作用域的进修释放资源。更为重要的是,如果在创建了对象之后但在它超出作用域之前发生异常,那么,编译器保证撤销该对象,作为展开定义对象的作用域的一部分。
class Resource { public: Resource(parms p): r(allocate(p)) { } ~Resource() { release(r); } // also need to define copy and assignment private: resource_type *r; // resource managed by this type resource_type *allocate(parms p); // allocate this resource void release(resource_type*); // free this resource }; void fcn() { Resource res(args); // allocates resource_type // code that might throw an exception // if exception occurs, destructor for res is run automatically // ... } // res goes out of scope and is destroyed automatically
auto_ptr 类
标准库的 auto_ptr 类是“资源分配即初始化”技术的例子。auto_ptr 类是接受一个类型形参的模板,它为动态分配的对象提供异常安全。auto_ptr 类在头文件 memory 中定义。
每个 auto_ptr 对象绑定到一个对象或者指向一个对象。当 auto_ptr 对象指向一个对象的时候,可以说它“拥有”该对象。当 auto_ptr 对象超出作用域或者另外撤销的时候,就自动回收 auto_ptr 所指向的动态分配对象。
|
auto_ptr<T> ap; |
创建名为 ap 的未绑定的 auto_ptr 对象 |
|
auto_ptr<T> ap(p); |
创建名为 ap 的 auto_ptr 对象,ap 拥有指针 p 指向的对象。该构造函数为 explicit |
|
auto_ptr<T> ap1(ap2); |
创建名为 ap1 的 auto_ptr 对象,ap1 保存原来存储在ap2 中的指针。将所有权转给 ap1,ap2 成为未绑定的auto_ptr 对象 |
|
ap1 = ap2 |
将所有权 ap2 转给 ap1。删除 ap1 指向的对象并且使 ap1指向 ap2 指向的对象,使 ap2 成为未绑定的 |
|
~ap |
析构函数。删除 ap 指向的对象 |
|
*ap |
返回对 ap 所绑定的对象的引用 |
|
ap-> |
返回 ap 保存的指针 |
|
ap.reset(p) |
如果 p 与 ap 的值不同,则删除 ap 指向的对象并且将 ap绑定到 p |
|
ap.release() |
返回 ap 所保存的指针并且使 ap 成为未绑定的 |
|
ap.get() |
返回 ap 保存的指针 |
auto_ptr 只能用于管理从 new 返回的一个对象,它不能管理动态分配的数组。当 auto_ptr 被复制或赋值的时候,有不寻常的行为,因此,不能将 auto_ptrs 存储在标准库容器类型中。
auto_ptr 是可以保存任何类型指针的模板.接受指针的构造函数为 explicit构造函数,所以必须使用初始化的直接形式来创建 auto_ptr 对象:
// error: constructor that takes a pointer is explicit and can't be used implicitly auto_ptr<int> pi = new int(1024); auto_ptr<int> pi(new int(1024)); // ok: uses direct initialization auto_ptr<string> ap1(new string("Brontosaurus")); // normal pointer operations for dereference and arrow *ap1 = "TRex"; // assigns a new value to the object to which ap1 points string s = *ap1; // initializes s as a copy of the object to which ap1 points if (ap1->empty()) // runs empty on the string to which ap1 points
auto_ptr 对象的复制和赋值是破坏性操作
auto_ptr 和内置指针对待复制和赋值有非常关键的重要区别。当复制 auto_ptr 对象或者将它的值赋给其他 auto_ptr 对象的时候,将基础对象的所有权从原来的 auto_ptr 对象转给副本,原来的 auto_ptr 对象重置为未绑定状态。
auto_ptr<string> ap1(new string("Stegosaurus")); // after the copy ap1 is unbound auto_ptr<string> ap2(ap1); // ownership transferred from ap1 to ap2
赋值删除左操作数指向的对象
除了将所有权从右操作数转给左操作数之外,赋值还删除左操作数原来指向的对象——假如两个对象不同。通常自身赋值没有效果。
auto_ptr<string> ap3(new string("Pterodactyl")); // object pointed to by ap3 is deleted and ownership transferred from ap2 to ap3; ap3 = ap2; // after the assignment, ap2 is unbound
将 ap2 赋给 ap3 之后:
• 删除了 ap3 指向的对象。
• 将 ap3 置为指向 ap2 所指的对象。
• ap2 是未绑定的 auto_ptr 对象。
auto_ptr 的默认构造函数
如果不给定初始式,auto_ptr 对象是未绑定的,它不指向对象:
auto_ptr<int> p_auto; // p_autodoesn't refer to any object
测试 auto_ptr 对象
auto_ptr 类型没有定义到可用作条件的类型的转换,相反,要测试auto_ptr 对象,必须使用它的 get 成员,该成员返回包含在 auto_ptr 对象中的基础指针:
// revised test to guarantee p_auto refers to an object if (p_auto.get()) *p_auto = 1024; // error: cannot use an auto_ptr as a condition if (p_auto) *p_auto = 1024;
应该只用 get 询问 auto_ptr 对象或者使用返回的指针值,不能用 get 作为创建其他 auto_ptr 对象的实参。
使用 get 成员初始化其他 auto_ptr 对象违反 auto_ptr 类设计原则:在任意时刻只有一个 auto_ptrs 对象保存给定指针,如果两个 auto_ptrs 对象保存相同的指针,该指针就会被 delete 两次。
reset 操作
auto_ptr 对象与内置指针的另一个区别是,不能直接将一个地址(或者其他指针)赋给 auto_ptr 对象:
p_auto = new int(1024); // error: cannot assign a pointer to an auto_ptr
相反,必须调用 reset 函数来改变指针:
// revised test to guarantee p_auto refers to an object if (p_auto.get()) *p_auto = 1024; else // reset p_auto to a new object p_auto.reset(new int(1024));
警告:auto_ptr 缺陷
auto_ptr 类模板为处理动态分配的内存提供了安全性和便利性的尺度。要正确地使用 auto_ptr 类,必须坚持该类强加的下列限制:
1. 不要使用 auto_ptr 对象保存指向静态分配对象的指针,否则,当 auto_ptr 对象本身被撤销的时候,它将试图删除指向非动态分配对象的指针,导致未定义的行为。
2. 永远不要使用两个 auto_ptrs 对象指向同一对象,导致这个错误的一种明显方式是,使用同一指针来初始化或者 reset 两个不同的 auto_ptr 对象。另一种导致这个错误的微妙方式可能是,使用一个 auto_ptr 对象的 get 函数的结果来初始化或者 reset另一个 auto_ptr 对象。
3. 不要使用 auto_ptr 对象保存指向动态分配数组的指针。当auto_ptr 对象被删除的时候,它只释放一个对象——它使用普通delete 操作符,而不用数组的 delete [] 操作符。
4. 不要将 auto_ptr 对象存储在容器中。容器要求所保存的类型定义复制和赋值操作符,使它们表现得类似于内置类型的操作符:在复制(或者赋值)之后,两个对象必须具有相同值,auto_ptr 类不满足这个要求。
异常说明
为了编写适当的 catch 子句,了解函数是否抛出异常以及会抛出哪种异常是很有用的。
异常说明指定,如果函数抛出异常,被抛出的异常将是包含在该说明中的一种,或者是从列出的异常中派生的类型。
定义异常说明异常说明跟在函数形参表之后。一个异常说明在关键字 throw 之后跟着一个(可能为空的)由圆括号括住的异常类型列表:
void recoup(int) throw(runtime_error);
空说明列表指出函数不抛出任何异常:
void no_problem() throw();
异常说明是函数接口的一部分,函数定义以及该函数的任意声明必须具有相同的异常说明。
如果一个函数声明没有指定异常说明,则该函数可以抛出任意类型的异常。
违反异常说明
不可能在编译时知道程序是否抛出异常以及会抛出哪些异常,只有在运行时才能检测是否违反函数异常说明。
如果函数抛出了没有在其异常说明中列出的异常,就调用标准库函数unexpected。默认情况下,unexpected 函数调用 terminate 函数,terminate 函数一般会终止程序。
异常说明与虚函数
基类中虚函数的异常说明,可以与派生类中对应虚函数的异常说明不同。但是,派生类虚函数的异常说明必须与对应基类虚函数的异常说明同样严格,或者比后者更受限。
这个限制保证,当使用指向基类类型的指针调用派生类虚函数的时候,派生类的异常说明不会增加新的可抛出异常。
class Base { public: virtual double f1(double) throw (); virtual int f2(int) throw (std::logic_error); virtual std::string f3() throw (std::logic_error, std::runtime_error); }; class Derived : public Base { public: // error: exception specification is less restrictive than Base::f1's double f1(double) throw (std::underflow_error); // ok: same exception specification as Base::f2 int f2(int) throw (std::logic_error); // ok: Derived f3 is more restrictive std::string f3() throw (); };
函数指针的异常说明
异常说明是函数类型的一部分。这样,也可以在函数指针的定义中提供异常说明:
void (*pf)(int) throw(runtime_error);
这个声明是说,pf 指向接受 int 值的函数,该函数返回 void 对象,该函数只能抛出 runtime_error 类型的异常。如果不提供异常说明,该指针就可以指向能够抛出任意类型异常的具有匹配类型的函数。
在用另一指针初始化带异常说明的函数的指针,或者将后者赋值给函数地址的时候,两个指针的异常说明不必相同,但是,源指针的异常说明必须至少与目标指针的一样严格。
void recoup(int) throw(runtime_error); // ok: recoup is as restrictive as pf1 void (*pf1)(int) throw(runtime_error) = recoup; // ok: recoup is more restrictive than pf2 void (*pf2)(int) throw(runtime_error, logic_error) = recoup; // error: recoup is less restrictive than pf3 void (*pf3)(int) throw() = recoup; // ok: recoup is more restrictive than pf4 void (*pf4)(int) = recoup;
命名空间
命名空间为防止名字冲突提供了更加可控的机制,命名空间能够划分全局命名空间,这样使用独立开发的库就更加容易了。一个命名空间是一个作用域,通过在命名空间内部定义库中的名字,库的作者(以及用户)可以避免全局名字固有的限制
全局命名空间
定义在全局作用域的名字(在任意类、函数或命名空间外部声明的名字)是定义在全局命名空间中的。全局命名空间是隐式声明的,存在于每个程序中。在全局作用域定义实体的每个文件将那些名字加到全局命名空间。可以用作用域操作符引用全局命名空间的成员。因为全局命名空间是隐含的,它没有名字,所以记号
::member_name
引用全局命名空间的成员。
嵌套命名空间
一个嵌套命名空间即是一个嵌套作用域——其作用域嵌套在包含它的命名空间内部。嵌套命名空间中的名字遵循常规规则:外围命名空间中声明的名字被嵌套命名空间中同一名字的声明所屏蔽。嵌套命名空间内部定义的名字局部于该命名空间。外围命名空间之外的代码只能通过限定名引用嵌套命名空间中的名字。
未命名的命名空间
命名空间可以是未命名的,未命名的命名空间在定义时没有给定名字。未命名的命名空间以关键字 namespace 开头,接在关键字 namespace 后面的是由花括号定界的声明块。未命名的命名空间的定义局部于特定文件,从不跨越多个文本文件。
未命名的命名空间可以在给定文件中不连续,但不能跨越文件,每个文件有自己的未命名的命名空间。
未命名的命名空间中定义的名字可直接使用,毕竟,没有命名空间名字来限定它们。
像任意其他命名空间一样,未命名的命名空间也可以嵌套在另一命名空间内部。
如果头文件定义了未命名的命名空间,那么,在每个包含该头文件的文件中,该命名空间中的名字将定义不同的局部实体。
在 C语言中,声明为 static 的局部实体在声明它的文件之外不可见。C++ 不赞成文件静态声明。不造成的特征是在未来版本中可能不支持的特征。应该避免文件静态而使用未命名空间代替。
using 声明的命名空间的作用域
using 声明中引入的名字遵循常规作用域规则。从 using 声明点开始,直到包含 using 声明的作用域的末尾,名字都是可见的。外部作用域中定义的同名实体被屏蔽。
可用命名空间别名将较短的同义词与命名空间名字相关联。例如,像
namespace cplusplus_primer { /* ... */ };
这样的长命名空间名字,可以像下面这样与较短的同义词相关联:
namespace primer = cplusplus_primer;
using 指示
像 using 声明一样,using 指示使我们能够使用命名空间名字的简写形式。与 using 声明不同,using 指示无法控制使得哪些名字可见——它们都是可见的。
用 using 指示引入的名字的作用域比 using 声明的更复杂。using 声明将名字直接放入出现 using 声明的作用域,好像 using 声明是命名空间成员的局部别名一样。因为这种声明是局部化的,冲突的机会最小。
using 指示不声明命名空间成员名字的别名,相反,它具有将命名空间成员提升到包含命名空间本身和 using 指示的最近作用域的效果。
// namespace A and function f are defined at global scope namespace A { int i, j; } void f() { using namespace A; // injects names from A into the global scope cout << i * j << endl; // uses i and j from namespace A //... }
警告:避免 Using 指示
对命名空间内部使用的名字的查找遵循常规 C++ 查找规则:当查找名字的时候,通过外围作用域外查找。对命名空间内部使用的名字而言,外围作用域可能是一个或多个嵌套的命名空间,最终以全包围的全局命名空间结束.
类内部所定义的成员可以使用出现在定义文本之后的名字。例如,即使数据成员的定义出现在构造函数定义之后,类定义体内部定义的构造函数也可以初始化那些数据成员。当在类作用域中使用名字的时候,首先在成员本身中查找,然后在类中查找,包括任意基类,只有在查找完类之后,才检查外围作用域。当类包在命名空间中的时候,发生相同的查找:首先在成员中找,然后在类(包括基类)中找,再在外围作用域中找,外围作用域中的一个或多个可以是命名空间:
namespace A { int i; int k; class C1 { public: C1(): i(0), j(0) { } // ok: initializes C1::i and C1::j int f1() { return k; // returns A::k } int f2() { return h; // error: h is not defined } int f3(); private: int i; // hides A::i within C1 int j; }; int h = i; // initialized from A::i } // member f3 is defined outside class C1 and outside namespace A int A::C1::f3() { return h; // ok: returns A::h }
接受类类型形参(或类类型指针及引用形参)的函数(包括重载操作符),以及与类本身定义在同一命名空间中的函数(包括重载操作符),在用类类型对象(或类类型的引用及指针)作为实参的时候是可见的。
如果函数具有类类型形参就使得函数可见,其原因在于,允许无须单独的using 声明就可以使用概念上作为类接口组成部分的非成员函数。能够使用非成员操作对操作符函数特别有用。
std::string s; // ok: calls std::getline(std::istream&, const std::string&) getline(std::cin, s);
当一个类声明友元函数的时候,函数的声明不必是可见的。如果不存在可见的声明,那么,友元声明具有将该函数或类的声明放入外围作用域的效果。
namespace A { class C { friend void f(const C&); // makes f a member of namespace A }; } // f2 defined at global scope void f2() { A::C cobj; f(cobj); // calls A::f }
重载与命名空间
候选函数与命名空间
命名空间对函数匹配有两个影响。一个影响是明显的:using 声明或 using指示可以将函数加到候选集合。另一个.有一个或多个类类型形参的函数的名字查找包括定义每个形参类型的命名空间。
namespace NS { class Item_base { /* ... */ }; void display(const Item_base&) { } } // Bulk_item's base class is declared in namespace NS class Bulk_item : public NS::Item_base { }; int main() { Bulk_item book1; display(book1); return 0; }
display 函数的实参 book1 具有类类型 Bulk_item。display 调用的候选函数不仅是在调用 display 函数的地方其声明可见的函数,还包括声明Bulk_item 类及其基类 Item_base 的命名空间中的函数。
重载与 using 声明
using 声明声明一个名字。
using NS::print(int); // error: cannot specify parameter list using NS::print; // ok: using declarations specify names only
如果命名空间内部的函数是重载的,那么,该函数名字的 using 声明声明了所有具有该名字的函数。由 using 声明引入的函数,重载出现 using 声明的作用域中的任意其他同名函数的声明。
多重继承
派生类构造函数初始化所有基类,构造派生类型的对象包括构造和初始化宾所有基类子对象。像继承单个基类的情况一样,派生类的构造函数可以在构造函数初始化式中给零个或多个基类传递值:
// explicitly initialize both base classes Panda::Panda(std::string name, bool onExhibit) : Bear(name, onExhibit, "Panda"), Endangered(Endangered::critical) { } // implicitly use Bear default constructor to initialize the Bear subobject Panda::Panda() : Endangered(Endangered::critical) { }
构造的次序
构造函数初始化式只能控制用于初始化基类的值,不能控制基类的构造次序。基类构造函数按照基类构造函数在类派生列表中的出现次序调用。
析构的次序
总是按构造函数运行的逆序调用析构函数。
多个基类可能导致二义性
假定 Bear 类和 Endangered 类都定义了名为 print 的成员,如果 Panda 类没有定义该成员,则
ying_yang.print(cout);
这样的语句将导致编译时错误。Panda 类的派生(它导致有两个名为 print 的成员)是完全合法的。派生只是
导致潜在的二义性,如果没有 Panda 对象调用 print,就可以避免这个二义性。如果每个 print 调用明确指出想要哪个版本——Bear::print 还是Endangered::print,也可以避免错误。只有在存在使用该成员的二义性尝试的
时候,才会出错。
虚继承
虚继承是一种机制,类通过虚继承指出它希望共享其虚基类的状态。在虚继承下,对给定虚基类,无论该类在派生层次中作为虚基类出现多少次,只继承一个共享的基类子对象。共享的基类子对象称为虚基类。
通过在派生列表中包含关键字virtual 设置虚基类:
class istream : public virtual ios { ... }; class ostream : virtual public ios { ... }; // iostream inherits only one copy of its ios base class class iostream: public istream, public ostream { ... };
特殊的初始化语义
通常,每个类只初始化自己的直接基类。在应用于虚基类的进修,这个初始化策略会失败。如果使用常规规则,就可能会多次初始化虚基类。类将沿着包含该虚基类的每个继承路径初始化。
为了解决这个重复初始化问题,从具有虚基类的类继承的类对初始化进行特殊处理。在虚派生中,由最低层派生类的构造函数初始化虚基类。
虽然由最低层派生类初始化虚基类,但是任何直接或间接继承虚基类的类一般也必须为该基类提供自己的初始化式。只要可以创建虚基类派生类类型的独立对象,该类就必须初始化自己的虚基类,这些初始化式只有创建中间类型的对象时使用。
构造函数与析构函数次序
无论虚基类出现在继承层次中任何地方,总是在构造非虚基类之前构造虚基类。在合成复制构造函数中使用同样的构造次序,在合成赋值操作符中也是按这个次序给基类赋值。保证调用基类析构函数的次序与构造函数的调用次序相反。