今天学的东西很杂,以后对某些知识有了新的理解会单独写一篇细谈。
独热编码与交叉熵损失函数
独热编码:数值化的场合,例:beijing->[1,0,0],shanghai->[0,1,0]…,优点在于能够处理非连续性数值特征,在一定程度上也扩充了特征,如性别作为特征经过one hot编码后变成了男或女两个特征。
代码测试如下,使用数据集为fashion MNIST:
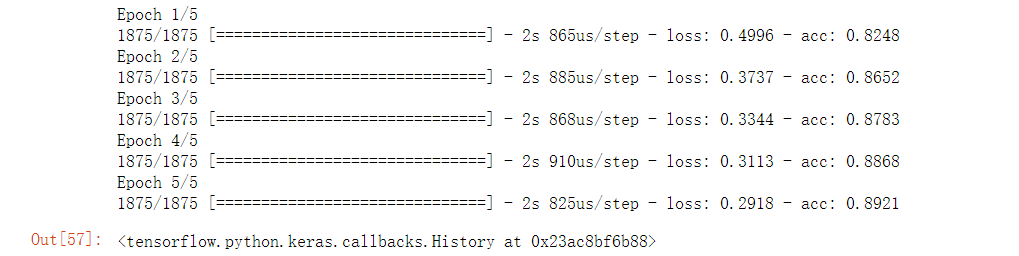
#独热编码 import tensorflow as tf import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline (train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data() #原训练方式 train_image = train_image/255 test_image = test_image/255 model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc']) model.fit(train_image, train_label, epochs=5)
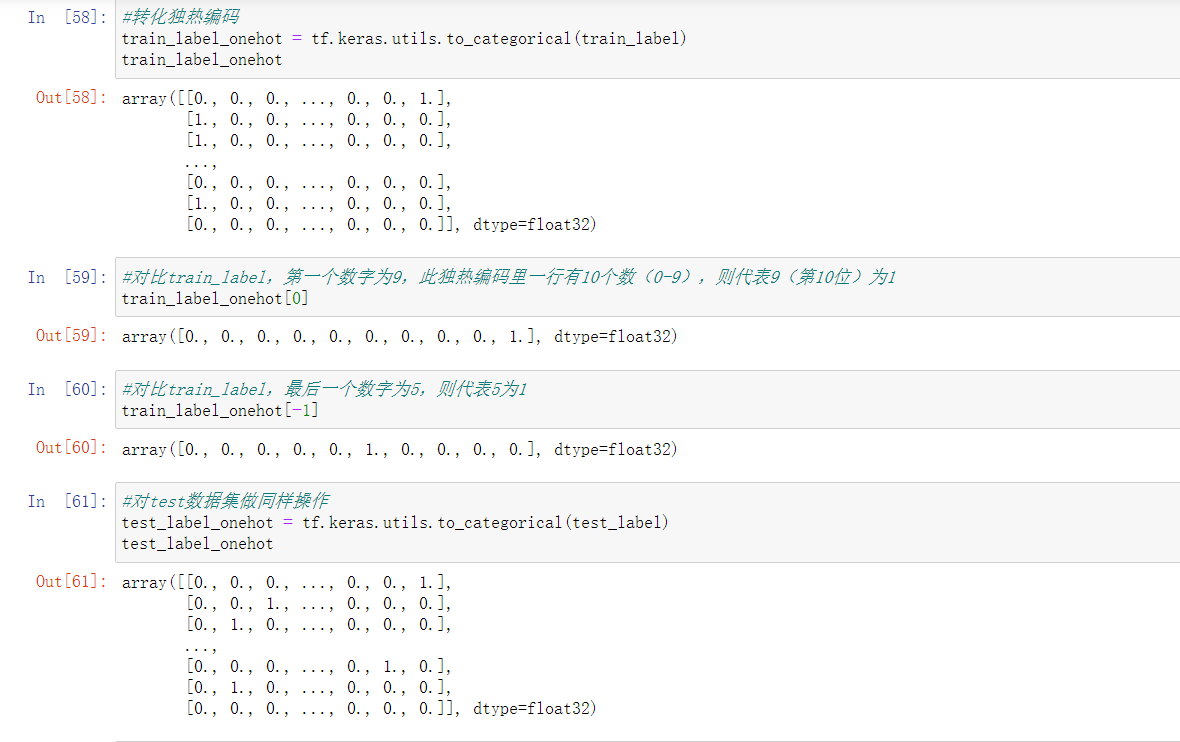
下面写几行代码理解一下独热编码到底是怎么表示的。。。。
回到编译环节:
#编译,独热编码的loss使用categorical_crossentropy model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc']) model.fit(train_image, train_label_onehot, epochs=5)

可以看到正确率变化非常小。我们再拿着这个模型预测一下吧:
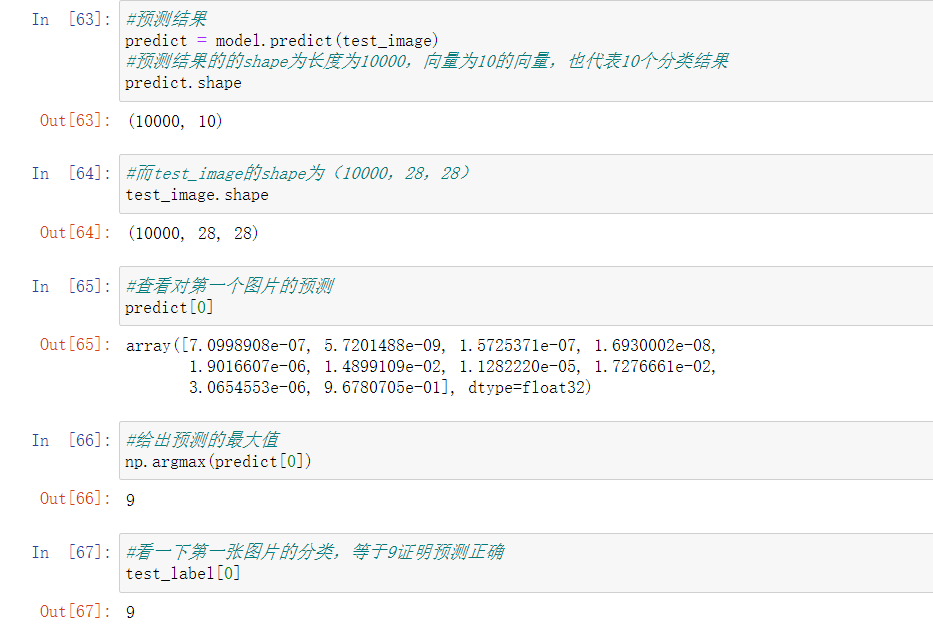
学习速率
学习速率:梯度表明损失函数相对参数的变化率,对梯度进行缩放的参数被称为学习速率。
学习速率是一种超参数(人为设置)。这个值不能乱设置,太小会导致在找损失函数极小值点时需要进行许多轮迭代,浪费时间;太大可能会跳过极小值点并因周期性跳跃而永远找不到极小值点。
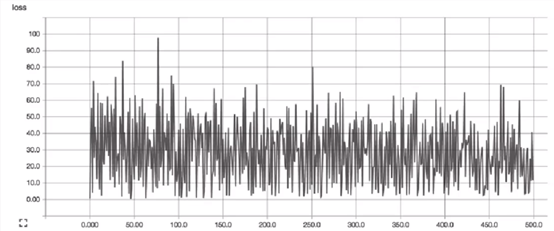
具体实践中可以通过查看损失函数值随时间变化的曲线来判断学习速率的选取是否合适。合适的学习速率,损失函数随时间下降,直到一个底部;不合适的学习速率,损失函数可能会发生震荡。
不合适样例:
代码测试如下,还是使用刚刚独热编码的例子,因为只需要在一处进行修改:
#这次更改一下学习速率,默认为0.001,更改成0.01 model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax')) model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss='categorical_crossentropy', metrics=['acc']) model.fit(train_image, train_label_onehot, epochs=5)

正确率下降了3%。
其他算法知识
反向传播算法:
原理:每一层的导数都是后一层的导数与前一层输出之积。(链式法则)
使用:前馈时,从输入开始,逐一计算每个隐含层的输出,直到输出层。之后开始计算导数,从输出层经各隐含层逐一反向传播。为减少计算量,需对所有已完成计算的元素进行复用。
常见的优化函数:
优化器(optimizer),放在model.compile()中通过名称调用优化器,之前的实验一直使用ADAM算法,即optimizer=’adam’,这样会使用优化器的默认参数(如学习速率)
SGD:随机梯度下降优化器。与min-batch是一个意思,抽取m个小批量(独立同分布)样本,计算它们的平均梯度值。
SGD参数:
learning_rate:float类型,>=0。学习率。
momentum:float类型,>=0。用于加速SGD在相关方向上前进,并抑制震荡。
decay:float类型,>=0。每次参数更新后学习率的衰减值。
nesterov:boolean类型,判断是否使用Nesterov动量。
RMSprop:经常用于处理序列问题上,如文档分类,一维卷积,序列预测等,此优化器通常是训练循环神经网络RNN的不错选择。
RMSprop参数:
learning_rate:float类型,>=0。学习率
rho:float类型,>=0。RMSprop梯度平方的移动均值衰减率
epsilon:float类型,>=0。模糊因子,若为None,默认为K.epsilon()
decay:float类型,>=0。每次参数更新后学习率的衰减值。
Adam(经常使用):
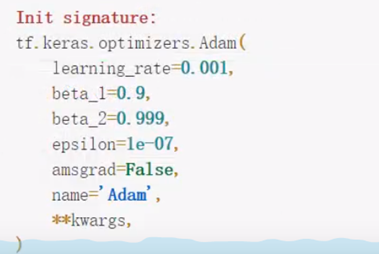
老熟人了(大雾),Adam算法可以看作是修正后的Momentum+RMSprop算法,它通常被认为对超参数的选择相当鲁棒(不敏感),这带来的好处就是对超参数的选择可以适当宽松一些,Adam的学习率建议为0.001
Adam参数:
learning_rate:float类型,>=0。学习率
beta_1:float类型,0<beta<1,通常接近于1。
beta_2:float类型,0<beta<1,通常接近于1。
decay:float类型,>=0,每次参数更新后学习率的衰减值
在jupyter notebook中查看adam默认参数如下:
网络优化
首先是概念引入:
网络容量:网络中的神经单元数越多,层数越多,神经网络的拟合能力越强,但随之训练速度,难度越大,越容易产生过拟合。
网络优化的一大思路就是提高网络的拟合能力,一种显而易见的方法就是增大网络容量,即增加层或隐藏神经元个数,而这两种情况中,增加层对提高网络拟合能力的效果是非常显著的。但要注意单层的神经元个数不能太小,否则会造成信息瓶颈,使得模型欠拟合。
代码测试如下,使用数据集为fashion MNIST:
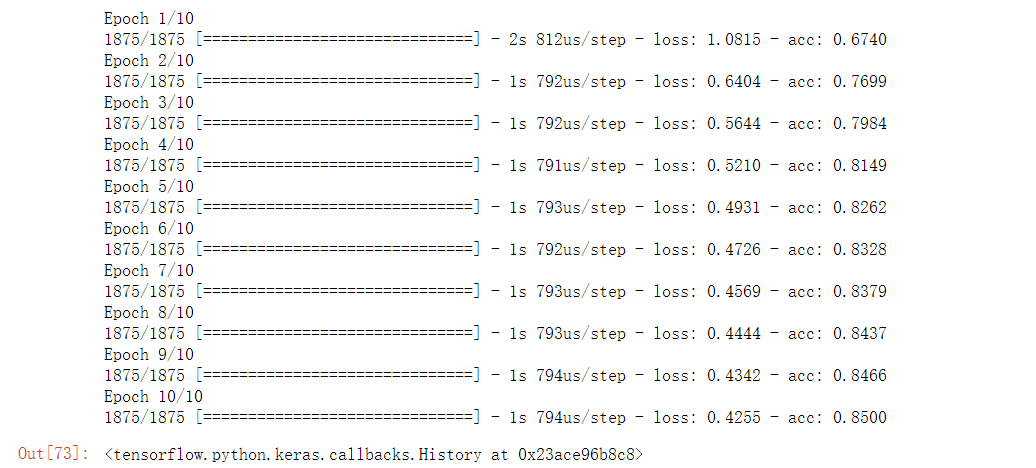
#网络优化测试,增加网络的拟合能力,方法:增加层 import tensorflow as tf import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline (train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data() #先看看之前测试的结果 train_image = train_image/255 test_image = test_image/255 model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc']) model.fit(train_image, train_label, epochs=10)
#优化 model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc']) model.fit(train_image, train_label, epochs=10)
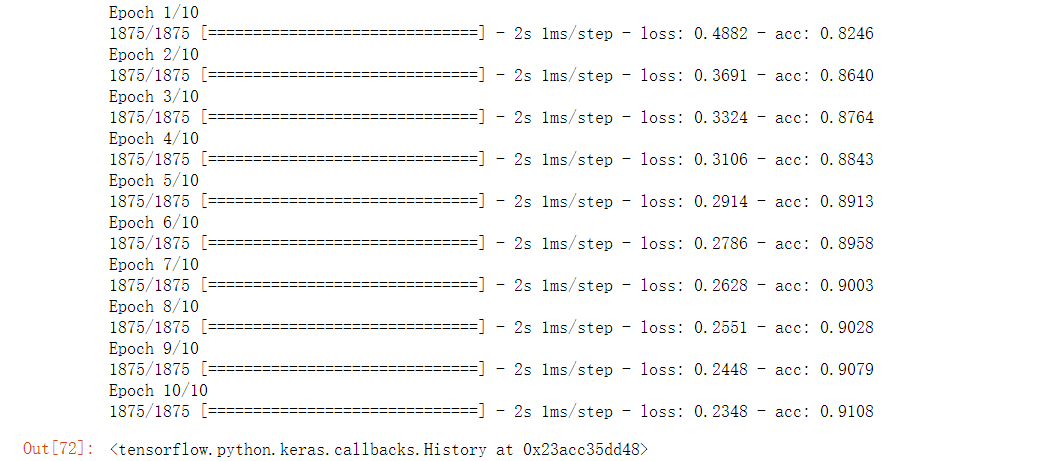
可以看到正确率变化很明显,同样是训练了10次,未加层的正确率为85%,而加层后正确率达到了91.08%。我们看一下二者的可训练参数差别:
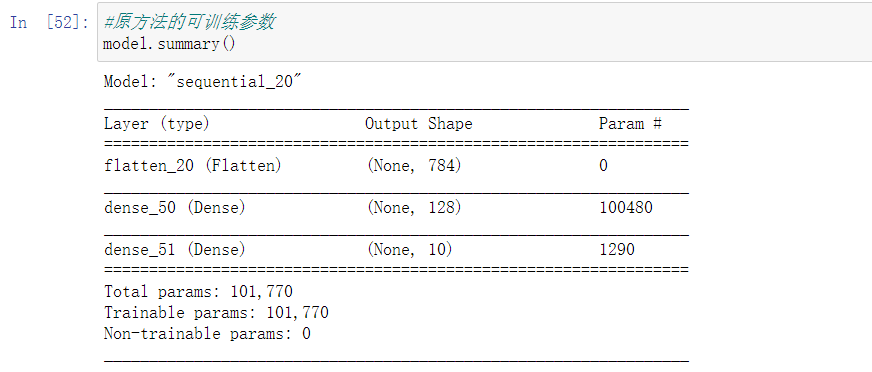

加了两层之后,可训练参数由101770变成了134794,这个变化数目并不小,但正如之前所提到过的,网络容量提升过大容易发生过拟合的问题,有关过拟合和欠拟合的知识明天再看吧。。。今天学习到的东西牵扯到数学的知识有不少,还需要好好梳理梳理。