一、作业介绍
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | < 数据采集,数据处理,数据分析,git上传> |
| 作业源代码 | https://github.com/ErikaSakii/first-personal-work |
| 学号 | <211806152> |
二、时间分布
| 步骤 | 时间 |
|---|---|
| 需求分析 | 5h |
| 数据采集 | 4h |
| 数据分析与处理 | 6h+ |
| 词云图展示 | 5h |
| 代码上传 | 仍在解决 |
三、作业过程
1、数据采集
1)打开腾讯视频的《在一起》评论页面 按F12
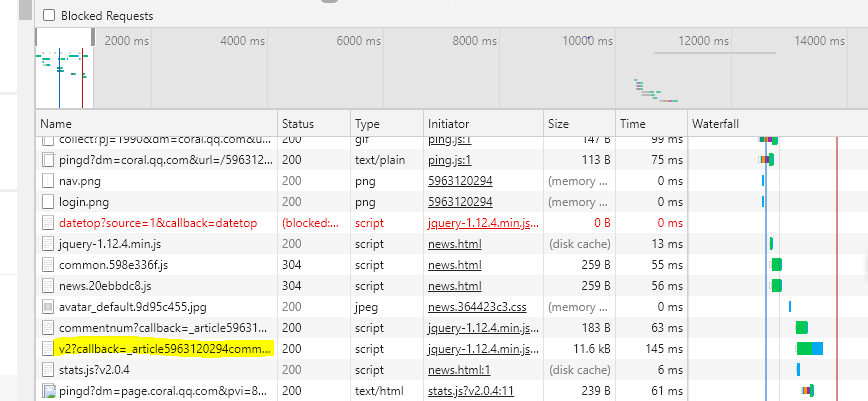
2)打开v2 callback开头的一项观察

观察发现Preview中的last与Request URL中的cursor=后的数据相同以及Request URL中的cursor=1&_=后的数据是随着页数的增加+1
3)按照这个规律,开始爬取数据
思路是:①抓取url地址②遍历所有url③正则提取评论④保存结果为.json
关键代码
url = 'https://coral.qq.com/article/5963120294/comment/v2?callback=_article5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=' + cursor + '&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=1&_=' + str(page)
source = requests.get(url, headers=headers).content.decode()
con='"content":"(.*?)"'
comment = re.compile(con,re.S).findall(source)
comments.append(comment)
id='"last":"(.*?)"'
cursor = re.compile(id,re.S).findall(source)[0]
page = str(int(page) + 1)
2、数据处理(采用jieba分词器)
全自动安装jieba
之前没有用过jieba,不太清楚它的用法,看了好多篇博文,找了半天才找到可以执行的代码段。
分词处理
content = content.replace('
',"").replace("u3000","")
content_late = jieba.lcut(content)
content_late = ' '.join(text_late)
words = open("E:erikawords.txt",encoding="utf8").read().split("
")#words.txt是我自己写的需要过滤的一些词以提高分词效率
3、生成词云图(采用worldcloud)
结合js插件echarts.js和echarts-wordcloud.min.js完成yuncitu.html

4、上传代码到Github
这部分耗费了我最多的时间,按着别的同学提示的步骤来,一直没发现问题出在哪里。。。 将仓库克隆到本地后,创建了分支并comnit,最后push。结果一直push不上去。。。

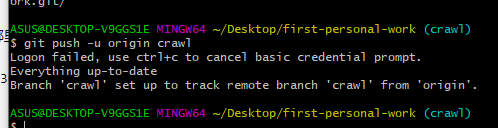
就这样过了好久好久。。。我终于发现问题所在,是我在克隆仓库的时候忘了加.git 导致的错误!然后成功push了源代码以及其他文件!太开心了!
四、总结
这次作业对我真的是很有挑战性,之前没有接触过爬虫(物联网飘过),所以在完成这次作业的过程,被卡了很多次,很多地方不熟悉,然后也请教了很多大数据的同学,他们很热心的帮助的去完成这次作业,非常感谢他们!谢谢!我会认真还带有疑惑的问题的!加油。