| 博客班级 | <2018软件工程2班> |
|---|---|
| 作业要求 | <第二次个人编程作业:代码互改> |
| 作业目标 | <与同学彼此之间,互相提出issue并改进代码,并学习、借鉴别人的好的想法> |
| 作业源代码 | <我的码云仓库> |
| 学号 | <211806327> |
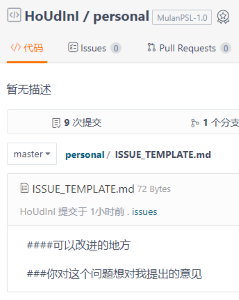
我的Issues模板:
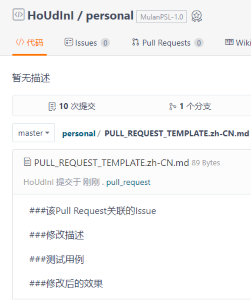
我的PR模板:
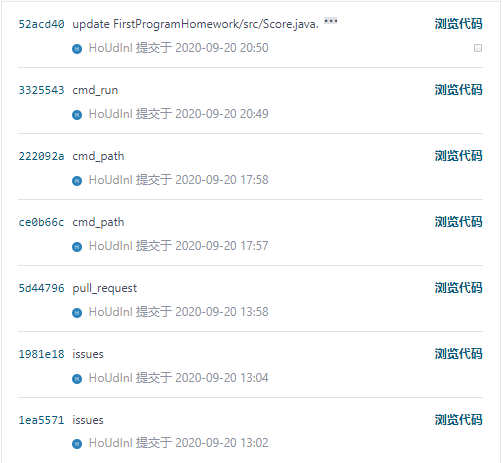
我的commit提交信息:

我成功的PR:

我的自提自改:
- 1、命令行输出问题
- 2、分类优化问题

让我看看你的代码:
1、黄志辉同学(带下划线的同学名字,点击进入该同学的码云仓库):
- 1、创建该函数时,此题中Jsoup.parse()方法没有必要放入第三个函数,会显得很冗长、臃肿。
Document smalldoc = Jsoup.parse(small, "UTF-8"," https://www.mosoteach.cn/web/index.php?c=interaction&m=index&clazz_course_id=CD7AE281-4AF8-11EA-9C7F-98039B1848C6"); - 除去后就显得更美观
Document file = Jsoup.parse(new File("small.html"),"UTF-8");
- 2、仓库中缺少了要求中的“.gitignore”文件;

- 添加后,再写入“*.class”就可以在上传时过滤掉,运行时所产生的,不需要的".class"文件。
- 3、仓库未开源

- 未开源就无法让别人进行fork、pull request操作,失去了进步的机会。
2、廖鸿志同学:
- 和我一样,未对自身正则表达式进行优化

- 可以对分类好后的div块用“(\d+) 经验”这一正则表达式使用match方法,再对group进行while循环,最后再类型转换,获得经验
3、王浪浪同学:
- 获取经验时使用的正则表达式
“\w* 经验”可以替换成"\d* 经验",
且可以换成用Double.parseDouble(matcher.group(1))来替代将获取内容的“经验”转换为null,再转化为int类型获取经验。

- 修改后能使代码更加简洁、高效。
4、林天淞同学:
- 1、仓库未开源,且缺少了要求中的“.gitignore”文件;
- 在“.gitignore”文件中写入“*.class”就可以在上传时过滤掉,运行时所产生的,不需要的".class"文件,开源后也可以让更多人来帮忙修改,进行fork,pull request。
- 2、变量名命名没有很规范,虽然是驼峰命名法,但有的却在开头就大写了。


- 养成好的编程习惯会对我们有很大帮助。
5、谢道彤同学:
- 对“课前自测”通过"data-type=QUIZ"来获取时,其实也会将“课堂提问”的经验值计算入其中。
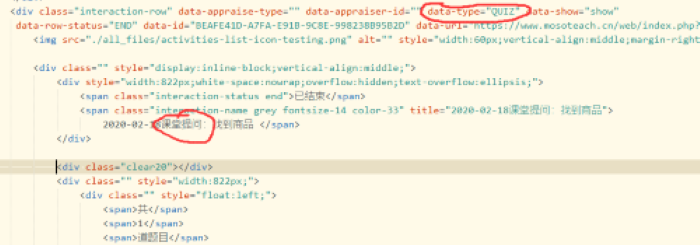

- 可以通过contains()方法再进行一次筛选来获得“课前自测”准确的经验值。
容我再改一改:
1、林俊威同学对我提出了将两句正则表达式合并的优化意见,这也正是我之前所遗忘的优化点。
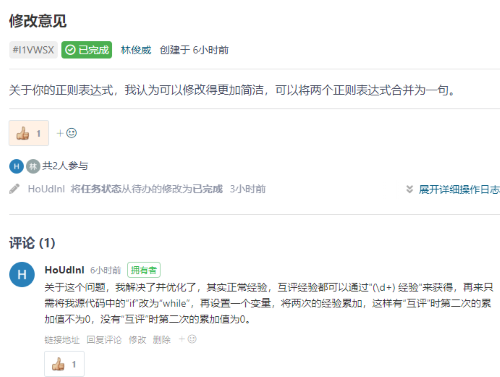
- 修改前:以下为我的原代码,思路为,分别获取“正常经验”和“互评经验”,要运行两次,且赋值了多个变量,较为繁琐
private static double getSc(Element row) {
Elements eleText = row.getElementsMatchingText("^\d+ 经验$");
Elements eleText1 = row.getElementsMatchingText("^互评 \d+ 经验$");
double each=0;
String score = eleText1.text();
Pattern number = Pattern.compile("(\d+)");
Matcher matcher = number.matcher(score);
if (matcher.find()) {
each=Double.parseDouble(matcher.group(1));
}
score = eleText.text();
number = Pattern.compile("(\d+)");
matcher = number.matcher(score);
if (matcher.find()) {
return Double.parseDouble(matcher.group(1))+each;
}
return 0;
}
- 修改后:本来我是想着手该同学的意见进行修改的,于是我再次对着html文件源码,却有了更好的想法,
在看到正常经验为“(数字) 经验”,互评则为“互评 (数字) 经验”,我恍然大悟,其实不需要去在意“互评”这两个字,
去掉后,那么两种经验在html的存储方式都为“(数字) 经验”,即“(\d+) 经验”,而我只要使用的是while,而不是if,
那么有“互评”时,经验值就会累加入sc,没有“互评”时,sc的累加值为0,大幅度地美化、优化了我的代码。
private static double getSc(Element row) {
double sc = 0;
String score = row.text();
Pattern number = Pattern.compile("(\d+) 经验");
Matcher matcher = number.matcher(score);
while (matcher.find()) {
sc += Double.parseDouble(matcher.group(1));
}
2、助教在替我解决上次作业中存在的疑惑时,还不忘顺带提醒了我未实现cmd运行的作业目标。
在助教的热情、耐心帮助下,我成功完成了修改。
String pathSm =Score.class.getResource(args[0]).getPath();
String pathAl =Score.class.getResource(args[1]).getPath();
String pathTo =Score.class.getResource("total.properties").getPath();
Document file = Jsoup.parse(new File(pathSm),"UTF-8");
Document file1 = Jsoup.parse(new File(pathAl),"UTF-8");
Elements exps = file.getElementsByClass("interaction-row");
exps.addAll(file1.getElementsByClass("interaction-row"));

3、分类问题的优化。
- 修改前:以下为我的源代码,在助教解决了我上次作业中的疑惑后,我才发现因为自己的错误,让自己的
分类方法绕了很大的远路,相当于吃剥好的橘子,我之前吃,是把橘子上的白色脉络剥掉才吃——多此一举,
而实际情况是可以直接吃的。
//通过data-appraise-type="TEACHER"(只有老师评)
//来筛选出"编程题"、"附加题"
//再通过是否包含"编程"、"附加",来分辨两者
Elements proPlus = exps.select("[data-appraise-type=TEACHER]");
for(Element p:proPlus) {
String type = p.text();
if(type.contains("编程")) {
proSc += getSc(p);
}
else if(type.contains("附加")) {
plusSc += getSc(p);
}
}
//通过data-type="QUIZ"(问答题)
//来筛选出"自测"和"课堂提问"
//再通过是否包含"自测"来分辨两者
Elements seExam = exps.select("[data-type=QUIZ]");
for(Element s:seExam) {
String type = s.text();
if(type.contains("自测")) {
seExSc += getSc(s);
}
}
//通过data-appraise-type="APPRAISER"(助教、老师评)、data-appraise-type="EACH_OTHER"(互评)
//来筛选出"课堂完成部分"、"小测"
//再通过是否包含"完成"、"小测",来分辨两者
Elements baExam1 = exps.select("[data-appraise-type=APPRAISER]");
for(Element b1:baExam1) {
String type = b1.text();
if(type.contains("完成")) {
baseSc += getSc(b1);
}
else if(type.contains("小测")) {
examSc += getSc(b1);
}
}
Elements baExam2 = exps.select("[data-appraise-type=EACH_OTHER]");
for(Element b2:baExam2) {
String type = b2.text();
if(type.contains("完成")) {
baseSc += getSc(b2);
}
else if(type.contains("小测")) {
examSc += getSc(b2);
}
}
- 修改后:
for(Element p:exps) {
String type = p.text();
if(type.contains("编程题")) {
proSc += getSc(p);
}
else if(type.contains("附加题")) {
plusSc += getSc(p);
}
else if(type.contains("课前自测")) {
seExSc += getSc(p);
}
else if(type.contains("课堂完成")) {
baseSc += getSc(p);
}
else if(type.contains("课堂小测")) {
examSc += getSc(p);
}
}
让我再看一看:
- 黄志辉同学采纳了我的意见并确实对我指出问题的地方进行了改进。
- 林天淞同学采纳了我的意见并确实对我指出问题的地方进行了改进。
- 谢道彤同学采纳了我的意见并确实对我指出问题的地方进行了改进。

- 王浪浪同学采纳了我的意见并确实对我指出问题的地方进行了改进。

- 廖鸿志同学采纳了我的意见并采用了我尝试进行修改提交的PR:

作业小结:
当我访问他人仓库,学习别人代码的时候,总能看见那些让人眼前一亮、神乎奇迹、叹为观止的处理方式,让我在惊叹之中,又能学习、收获到了很多
一千个读者眼中就会有一千个哈姆雷特,同一个问题,不同人就会有不同方法,如果我不断去了解别人的想法的话,那么自己的想法就能越来越靠近自
己心中的完美,我想这就是这次作业老师想要告诉我们的吧——在借鉴中不断学习,不断接收自己没有的新思想来强化自己。