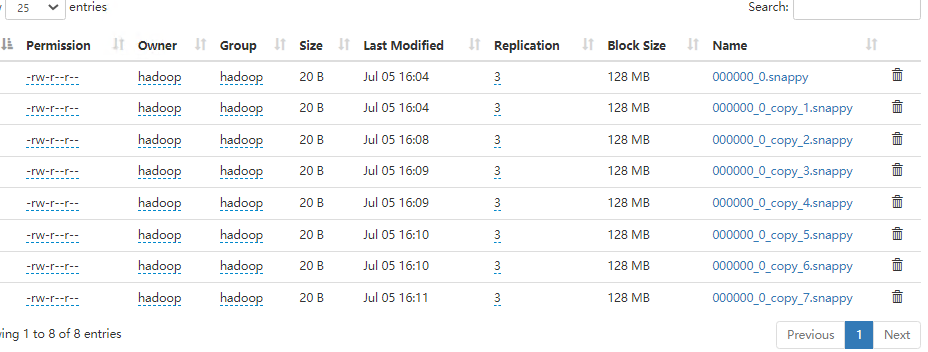
使用hive时插入的数据,由于在hive配置中设置输出的是snappy格式文件,文件如下。
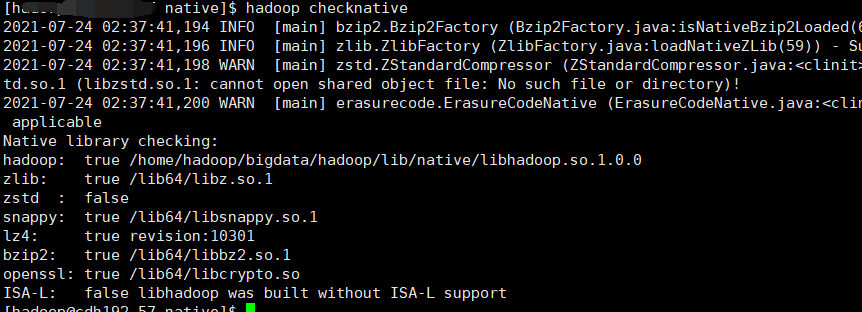
在hadoop中检测支持的库:
在使用spark-sql读取hive的这个表时,出现以下错误:
Caused by: java.lang.RuntimeException: native snappy library not available: this version of libhadoop was built without snappy support. at org.apache.hadoop.io.compress.SnappyCodec.checkNativeCodeLoaded(SnappyCodec.java:65) at org.apache.hadoop.io.compress.SnappyCodec.getDecompressorType(SnappyCodec.java:193) at org.apache.hadoop.io.compress.CodecPool.getDecompressor(CodecPool.java:178) at org.apache.hadoop.mapred.LineRecordReader.<init>(LineRecordReader.java:111) at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67) at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:267) at org.apache.spark.rdd.HadoopRDD$$anon$1.<init>(HadoopRDD.scala:266) at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:224) at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:95) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:123) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:411) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:417) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
说明spark未引用到这个类库。
解决方案:
在环境变量 /etc/profile中增加library的路径,记得加完后source /etc/profile使其生效。
export LD_LIBRARY_PATH=/home/hadoop/bigdata/hadoop/lib/native:$LD_LIBRARY_PATH
再次启动spark-sql查询,问题解决:
