Lucene基本概念
- 文档(document):索引与搜索的主要载体,它包含一个或多个字段,存放将要写入索引的或将从索引搜索出来的数据。
- 字段(field):文档的一个片段,它包含字段的名称和字段的内容两个部分。
- 词项(term):搜索时的一个单位,代表了文本中的一个词。
- 词条(token):词项在字段文本中的一次出现,包括词项的文本、开始和结束的偏移以及词条类型。
分析数据
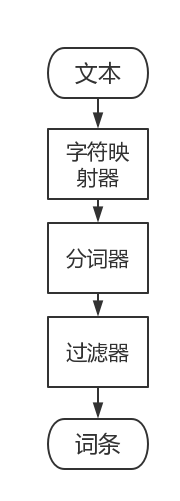
文本分析由分析器来执行,建立在分词器、过滤器和字符映射器之上。
分词器工作的结果称为词条流。
过滤器串联执行,可以一个也可以多个,用于处理分词器的结果。常见的过滤器:小写过滤器、ASCII过滤器(移除词条中所有非ASCII字符)、同义词过滤器(将一个词条转换成另一个词条)、多语言词干还原过滤器。
字符映射器用于分词器之前的文本预处理。比如HTML文本的去标签处理
Lucene查询语言
AND:结果是当且仅当左右两边的词都在文档中出现。例:apache AND lucene 返回同时包含这两个词的文档
OR:包含任意一个词项的文档被返回
NOT:不包含NOT后面的词项的文档被返回。例:Lucene NOT elasticsearch 返回包含Lucene不包含elasticsearch的文档
+:只有包含+后面词项的文档符合。例:+Lucene Apache 包含Lucene Apache无所谓的文档返回
-:不能出现-后面的词项,类似NOT
如果查询中没有出现前面的任意操作符,默认使用OR
词项修饰符
Lucene支持通配符:?和*。出于性能考虑,*不能作为第一个字符。
模糊查询依赖符号。后面紧跟一个数字,数字确定近似词项与原始词项的最大编辑距离。而当~跟在短语后的时候,表示词项之间多大的距离是可以接受的。例如:title:"master elasticsearch"~2 会匹配master book elasticsearch
此外,Lucene也支持范围查询和词项加权重查询。这些在elasticsearch中都有体现。
elasticsearch基本概念(捡几个重要的)
映射:映射所扮演的角色:存储分析链所需的所有信息。
节点:数据节点、主节点、部落节点(连接多个集群,并可以执行全局查询)
elasticsearch是基于对等架构的,这导致我们不用关心主节点是哪个,任意节点都能处理用户的查询请求。
elasticsearch创建索引的过程只能在主分片上进行,即如果索引请求发到了只有副本的节点,请求会被转发到有主分片的节点,然后再分发到其副本分片。
Elasticsearch致力于隐藏分布式系统的复杂性,以下内容由底层自动完成。
- 将你的文档分区到不同的容器或者分片中,他们可以存在于一个或者多个节点中
- 将分片均匀的分配到各个节点,对索引和搜索做负载均衡。
- 冗余每个分片,防止硬件故障造成的数据损失。
- 将集群中任意一个节点上的请求路由到相应数据所在的节点。
- 无论增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移。