先说一个小知识,助于理解代码中各个层之间维度是怎么变换的。
卷积函数:一般只用来改变输入数据的维度,例如3维到16维。
Conv2d()
Conv2d(in_channels:int,out_channels:int,kernel_size:Union[int,tuple],stride=1,padding=o):
"""
:param in_channels: 输入的维度
:param out_channels: 通过卷积核之后,要输出的维度
:param kernel_size: 卷积核大小
:param stride: 移动步长
:param padding: 四周添多少个零
"""
一个小例子:
import torch
import torch.nn
# 定义一个16张照片,每个照片3个通道,大小是28*28
x= torch.randn(16,3,32,32)
# 改变照片的维度,从3维升到16维,卷积核大小是5
conv= torch.nn.Conv2d(3,16,kernel_size=5,stride=1,padding=0)
res=conv(x)
print(res.shape)
# torch.Size([16, 16, 28, 28])
# 维度升到16维,因为卷积核大小是5,步长是1,所以照片的大小缩小了,变成28
卷积神经网络实战之Lenet5:
下面放一个示例图,代码中的过程就是根据示例图进行的
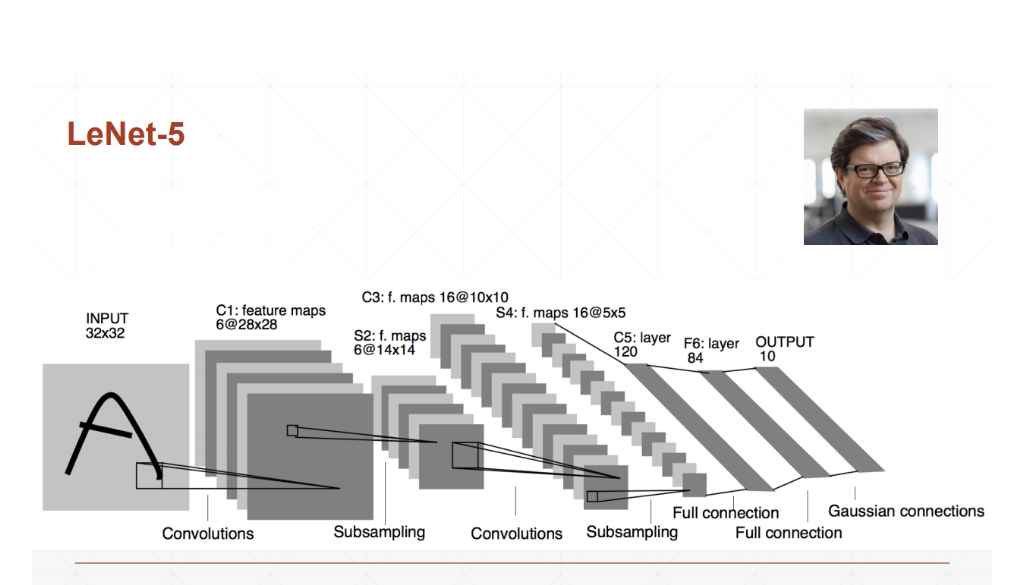
- 1.经过一个卷积层,从刚开始的[b,3,32,32]-->[b,6,28,28]
- 2.经过一个池化层,从[b,6,28,28]-->[b,6,14,14]
- 3.再经过一个卷积层,从[b,6,14,14]-->[b,16,10,10]
- 4.再经过一个池化层,从[b,16,10,10]-->[b,16,5,5]
- 5.经过三个个全连接层,将数据[b,16,5,5]-->[b,120]-->[b,84]-->[b,10]
Lenet5的构造如下:
Lenet5(
(conv_unit): Sequential(
(0): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc_unit): Sequential(
(0): Linear(in_features=400, out_features=120, bias=True)
(1): ReLU()
(2): Linear(in_features=120, out_features=84, bias=True)
(3): ReLU()
(4): Linear(in_features=84, out_features=10, bias=True)
)
)
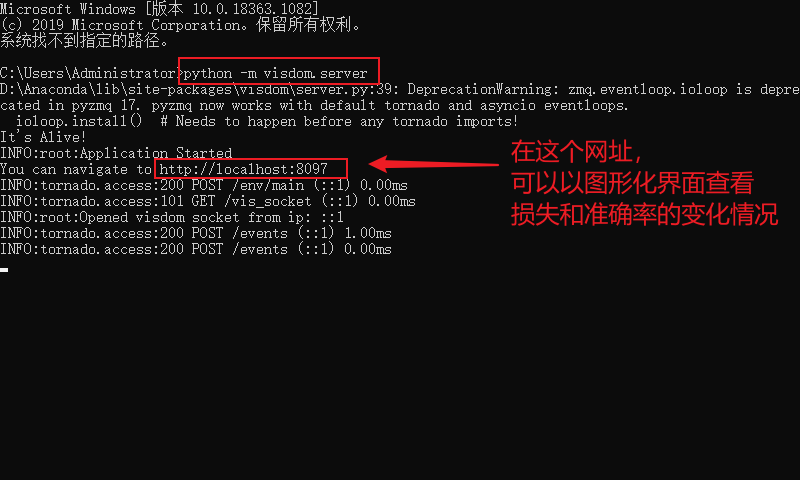
程序运行前,先启动visdom,如果没有配置好visdom环境的,先百度安装好visdom环境
- 1.使用快捷键win+r,在输入框输出cmd,然后在命令行窗口里输入
python -m visdom.server,启动visdom
代码实战
定义一个名为
lenet5.py的文件,代码如下
import torch
from torch import nn
import torch.optim
import torch.nn
from torch.nn import functional as F
class Lenet5(nn.Module):
# for cifar10 dataset.
def __init__(self):
super(Lenet5, self).__init__()
# 卷积层 Convolutional
self.conv_unit = nn.Sequential(
# x:[b,3,32,32]==>[b,6,28,28]
nn.Conv2d(3, 6, kernel_size=5, stride=1, padding=0),
# x:[b,6,28,28]==>[b,6,14,14]
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
#[b,6,14,14]==>[b,16,10,10]
nn.Conv2d(6,16,kernel_size=5,stride=1,padding=0),
# x:[b,16,10,10]==>[b,16,5,5]
nn.MaxPool2d(kernel_size=2,stride=2,padding=0),
)
# 全连接层fully connected
self.fc_unit=nn.Sequential(
nn.Linear(16*5*5,120),
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,10)
)
def forward(self,x):
"""
:param x:[b,3,32,32]
:return:
"""
batchsz=x.size(0)
# 卷积层池化层运算 [b,3,32,32]==>[b,16,5,5]
x=self.conv_unit(x)
# 对数据进行打平,方便后边全连接层进行运算[b,16,5,5]==>[b,16*5*5]
x=x.view(batchsz,16*5*5)
# 全连接层[b,16*5*5]==>[b,10]
logits=self.fc_unit(x)
return logits
# loss=self.criteon(logits,y)
def main():
net=Lenet5()
# [b,3,32,32]
temp = torch.randn(2, 3, 32, 32)
out = net(temp)
# [b,16,5,5]
print("lenet_out:", out.shape)
if __name__ == '__main__':
main()
定义一个名为
main.py的文件,代码如下
import torch
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn,optim
from visdom import Visdom
from lenet5 import Lenet5
def main():
batch_siz=32
cifar_train = datasets.CIFAR10('cifar',True,transform=transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]),download=True)
cifar_train=DataLoader(cifar_train,batch_size=batch_siz,shuffle=True)
cifar_test = datasets.CIFAR10('cifar',False,transform=transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]),download=True)
cifar_test=DataLoader(cifar_test,batch_size=batch_siz,shuffle=True)
x,label = iter(cifar_train).next()
print('x:',x.shape,'label:',label.shape)
# 指定运行到cpu //GPU
device=torch.device('cpu')
model = Lenet5().to(device)
# 调用损失函数use Cross Entropy loss交叉熵
# 分类问题使用CrossEntropyLoss比MSELoss更合适
criteon = nn.CrossEntropyLoss().to(device)
# 定义一个优化器
optimizer=optim.Adam(model.parameters(),lr=1e-3)
print(model)
viz=Visdom()
viz.line([0.],[0.],win="loss",opts=dict(title='Lenet5 Loss'))
viz.line([0.],[0.],win="acc",opts=dict(title='Lenet5 Acc'))
# 训练train
for epoch in range(1000):
# 变成train模式
model.train()
# barchidx:下标,x:[b,3,32,32],label:[b]
for barchidx,(x,label) in enumerate(cifar_train):
# 将x,label放在gpu上
x,label=x.to(device),label.to(device)
# logits:[b,10]
# label:[b]
logits = model(x)
loss = criteon(logits,label)
# viz.line([loss.item()],[barchidx],win='loss',update='append')
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()],[epoch],win='loss',update='append')
print(epoch,'loss:',loss.item())
# 变成测试模式
model.eval()
with torch.no_grad():
# 测试test
# 正确的数目
total_correct=0
total_num=0
for x,label in cifar_test:
# 将x,label放在gpu上
x,label=x.to(device),label.to(device)
# [b,10]
logits=model(x)
# [b]
pred=logits.argmax(dim=1)
# [b] = [b'] 统计相等个数
total_correct+=pred.eq(label).float().sum().item()
total_num+=x.size(0)
acc=total_correct/total_num
print(epoch,'acc:',acc)
viz.line([acc],[epoch],win='acc',update='append')
# viz.images(x.view(-1, 3, 32, 32), win='x')
if __name__ == '__main__':
main()
测试结果


准确率刚开始是有一定的上升的,最高可达64%,后来准确率就慢慢的下降。