1 文件的读
1.1 R(只读)
Log文件中有“hello,世界你好”
f = open('file/log',mode='r',encoding='utf-8')
Read_new = f.read()
print(Read_new)
f.close()
# 结果:哈喽,世界你好
1.2 Rb(取出来的是bytes类型,在rb模式下,不能使用encoding)
直接读取文件存储的二进制,但在pycharm中将二进制转换成了16进制来显示。
# rb
f = open('file/log',mode='rb')
Read_now_bytes = f.read()
print(Read_now_bytes)
f.close()
# 结果:b'xe5x93x88xe5x96xbd,xe4xb8x96xe7x95x8cxe4xbdxa0xe5xa5xbd'
中文在UTF-8编码中,一个汉字占用三个字符,可以看出哈喽,世界你好,六个字一共占用了18个字符,每一个“x”都是一位
Rb的作用:当处理一些非文本数据值,要用到,比如MP3,视屏,图片等,还有上传,下载,我们看的直播也都是传输的是rb这种格式。
当文件过大时,直接read是不合适的,很容易把电脑内存溢出
1.3 read的功能操作
1.3.1 r读取n个字符
# 读取n个字符
f = open('file/log',mode='r',encoding='utf-8')
Read_new_n = f.read(4) # 读的是汉字个数,从头开始,读取4个
print(Read_new_n)
f.close()
# 白日依山
那么多次执行呢?
f = open('file/log',mode='r',encoding='utf-8')
Read_new_n_1 = f.read(4)
Read_new_n_2 = f.read(4)
Read_new_n_3 = f.read(4)
Read_new_n_4 = f.read(4)
Read_new_n_5 = f.read(4)
print(Read_new_n_1,end="a")
print(Read_new_n_2,end="a")
print(Read_new_n_3,end="a")
print(Read_new_n_4,end="a")
print(Read_new_n_5)
# 结果:
# f.close()
# 白日依山a尽,
# 黄a河入海流a。
# 欲穷a千里目,
# 第一次从开头开始读娶四个字(标点符号,换行符都算),第二次从现在光标的为值继续读取4个字
1.3.2 使用rb读取指定的字符数
# rb读取n个字符
f = open('file/log',mode='rb')
Read_new = f.read(3)
Read_new_1 = f.read(3)
print(Read_new)
print(Read_new_1)
f.close()
# 结果:
# b'xe7x99xbd'
# b'xe6x97xa5'
# 可以看出每次读取了三个字节,
1.3.3 readline 一行一行的读取
# readline 一行一行的读取
f = open('file/log',mode='r',encoding='utf-8')
Read_line = f.readline()
print(Read_line)
f.close()
# 结果:白日依山尽, 读取的是第一行内容
如果早readline中加上参数是怎样。
f = open('file/log',mode='r',encoding='utf-8')
Read_line = f.readline(3)
print(Read_line)
f.close()
# 结果:白日依
# 3代表这一行的前几个字符,加入输入的字符超过了最大的字符数,就只会显示到本行末尾
1.3.4 readlines,将所有的行都读出来
f = open('file/log',mode='r',encoding='utf-8')
Read_lines = f.readlines()
print(Read_lines)
f.close()
# ['白日依山尽,
', '黄。河入海流
', '欲穷千里目,
', '更上一层楼。']
# 将文本中的所有行全部打印出来,不过是放到了列表中,还把换行符都打印出来,要是用的话可以用strip去除换行符
1.3.5, for循环读取
f = open('file/log',mode='r',encoding='utf-8')
for Read_for in f:
print(Read_for,end="")
# 结果:
# 白日依山尽,
# 黄河入海流。
# 欲穷千里目,
# 更上一层楼。
1.3.6 查询文件是否可读
f = open('file/log',mode='r',encoding='utf-8')
Read_YN = f.readable()
print(Read_YN)
f.close()
# 结果:True 当mode为“r”是文件就是可读的,而且是只读
f = open('file/log',mode='w',encoding='utf-8')
Read_YN = f.readable()
print(Read_YN)
f.close()
# 结果:False 当mode为“w”是,去判断这个文件是不是可读,返回False
2.文件的写
2.1 w(只写)
在写的时候,如果目标文件不存在,将会创建,若果存在,将会删除里面的内容,写入新的内容。
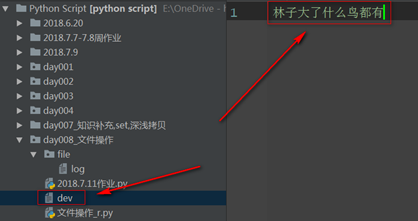
f = open('dev',mode='w',encoding='utf-8')
Write_only = f.write("林子大了什么鸟都有")
f.flush()
f.close()
结果:
2.2 wb(二进制写入)
Wb模式下可以不指定“encoding”的编码格式,但是再写的时候需要编码格式
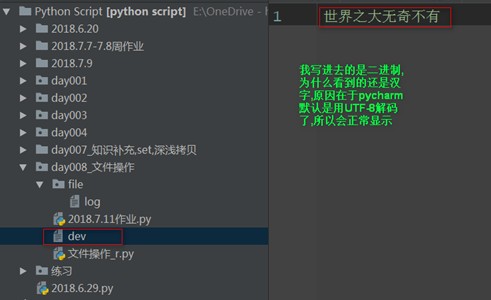
f = open('dev',mode='wb')
Write_bytes = f.write("世界之大无奇不有".encode('utf-8'))
f.flush()
f.close()
3.文件的追加
3.1 a(追加)
追加在文件的末尾
f = open('dev',mode='a',encoding='utf-8')
file_add = f.write('我来了,你还在吗?')
f.flush()
f.close()
之前的内容还是存在,只是在末尾添加了新的内容

3.2 ab(二进制追加)
略........
4 r+,r+b(读写模式)
对于读写模式. 必须是先读. 后写入,因为默认光标是在开头的. 准备读取的. 当读完了了之后再进⾏行行写入. 我们以后使⽤用频率最高的模式就是r+
# r+ 读写
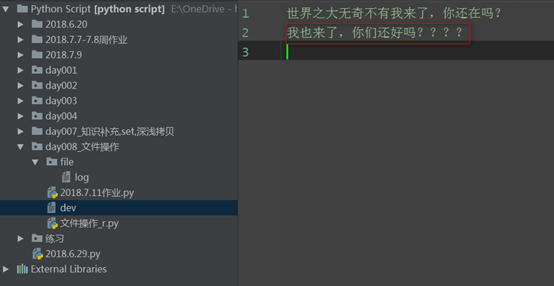
f = open('dev',mode='r+',encoding='utf-8')
read_1 = f.read()
print(read_1)
f.write("
我也来了,你们还好吗????")
f.flush()
f.close()
# 世界之大无奇不有我来了,你还在吗? 先读后写,否则会先从头开始写,覆盖原有的字符,然后读剩下的字符,加入全部覆盖,那么久就没有内容可读了
深坑请注意: 在r+模式下. 如果读取了内容. 不论读取内容多少. 光标显⽰的是多少. 再写入或者操作⽂件的时候都是在结尾进行的操作.
5 w+,w+b(写读模式)
先将所有的内容清空. 然后写入. 最后读取. 但是读取的内容是空的, 不常用
# w+,w+b 写读模式
f = open('dev',mode='w+',encoding='utf-8')
f.write("哈喽哈喽,大家好,才是真的好")
read_1 = f.read()
print(read_1)
f.flush()
f.close()
6 a+,a+b(追加读)
a+模式下, 不论先读还是后读. 都是读取不到数据的.
# a+ a+b 追加读
f = open('dev',mode='a+',encoding='utf-8')
f.write("594504110")
read_1 = f.read()
print(read_1)
f.flush()
f.close()
7其他操作
7.1 seek(移动光标)
1. seek(n) 光标移动到n位置, 注意, 移动的单位是byte. 所以如果是UTF-8的中文部分要是3的倍数.通常我们使用seek都是移动到开头或者结尾.
移动到开头: seek(0)
移动到结尾: seek(0,2) seek的第⼆个参数表⽰的是从哪个位置进⾏偏移, 默认是0, 表
⽰开头, 1表⽰当前位置, 2表⽰结尾
7.2 tell (查看当前光标的位置)
tell()使用可以帮我们获取到当前光标在什么位置
7.3 truncate(截断文件)
所以如果想做截断操作. 记住了. 要先挪动光标. 挪动到你想要截断的位置. 然后再进行截断关于truncate(n), 如果给出了n. 则从开头进行截断, 如果不给n, 则从当前位置截断. 后面的内容将会被删除
7.4 文件操作的另一种方式
import os
with open('dev',mode='r',encoding='utf-8') as f:
for read_1 in f:
print(read_1)
# 哈喽哈喽,大家好,才是真的好594504110
os.remove('dev') #删除这个文件
os.renames("old","new") #文件重命名