分布分析用来解释数据的分布特征和分布类型,显示其分布情况。分布分析主要分为两种:对定量数据的分布分析和对定性数据的分布分析。 对定量数据的分布分析按照以下步骤执行: 1:求极差 2:决定组距与组数。 3:决定分点。 4:得到频率分布表。 5:绘制频率分布直方图 遵循的原则有: 1:所有分组必须将所有数据包含在内。 2:各组的组宽最好相等。 3:各组相斥。 对定性数据的分布分析: 对定性数据的分布分析根据变量的分类类型来确定分组,然后使用图形对信息进行显示。
''' 【课程1.2】 分布分析 分布分析 → 研究数据的分布特征和分布类型,分定量数据、定性数据区分基本统计量 极差 / 频率分布情况 / 分组组距及组数 '''
import numpy as np import pandas as pd import matplotlib.pyplot as plt % matplotlib inline
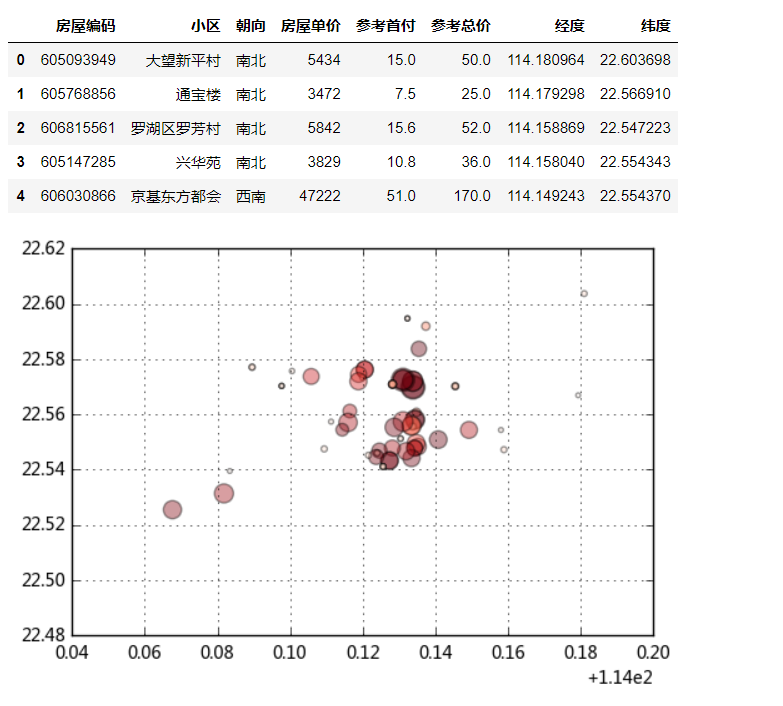
# 数据读取 data = pd.read_csv('C:/Users/Hjx/Desktop/深圳罗湖二手房信息.csv',engine = 'python') plt.scatter(data['经度'],data['纬度'], # 按照经纬度显示 s = data['房屋单价']/500, # 按照单价显示大小 c = data['参考总价'], # 按照总价显示颜色 alpha = 0.4, cmap = 'Reds') plt.grid() print(data.dtypes) print('------- 数据长度为%i条' % len(data)) data.head() # 通过数据可见,一共8个字段 # 定量字段:房屋单价,参考首付,参考总价,*经度,*纬度,*房屋编码 # 定性字段:小区,朝向
输出:
房屋编码 int64 小区 object 朝向 object 房屋单价 int64 参考首付 float64 参考总价 float64 经度 float64 纬度 float64 dtype: object ------- 数据长度为75条
# 极差:max-min # 只针对定量字段 def d_range(df,*cols): krange = [] for col in cols: crange = df[col].max() - df[col].min() krange.append(crange) return(krange) # 创建函数求极差 key1 = '参考首付' key2 = '参考总价' dr = d_range(data,key1,key2) print('%s极差为 %f %s极差为 %f' % (key1, dr[0], key2, dr[1])) # 求出数据对应列的极差
输出:
参考首付极差为 52.500000 参考总价极差为 175.000000
# 频率分布情况 - 定量字段 # ① 通过直方图直接判断分组组数 data[key2].hist(bins=10) # 简单查看数据分布,确定分布组数 → 一般8-16即可 # 这里以10组为参考
输出:
# 频率分布情况 - 定量字段 # ② 求出分组区间 gcut = pd.cut(data[key2],10,right=False) gcut_count = gcut.value_counts(sort=False) # 不排序 data['%s分组区间' % key2] = gcut.values print(gcut.head(),' ------') print(gcut_count) data.head() # pd.cut(x, bins, right):按照组数对x分组,且返回一个和x同样长度的分组dataframe,right → 是否右边包含,默认True # 通过groupby查看不同组的数据频率分布 # 给源数据data添加“分组区间”列
输出:
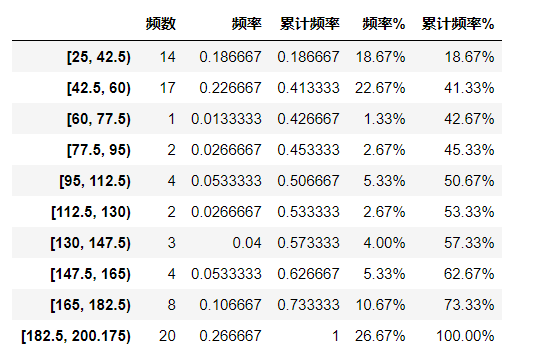
0 [42.5, 60) 1 [25, 42.5) 2 [42.5, 60) 3 [25, 42.5) 4 [165, 182.5) Name: 参考总价, dtype: category Categories (10, object): [[25, 42.5) < [42.5, 60) < [60, 77.5) < [77.5, 95) ... [130, 147.5) < [147.5, 165) < [165, 182.5) < [182.5, 200.175)] ------ [25, 42.5) 14 [42.5, 60) 17 [60, 77.5) 1 [77.5, 95) 2 [95, 112.5) 4 [112.5, 130) 2 [130, 147.5) 3 [147.5, 165) 4 [165, 182.5) 8 [182.5, 200.175) 20 Name: 参考总价, dtype: int64
房屋编码 小区 朝向 房屋单价 参考首付 参考总价 经度 纬度 参考总价分组区间 0 605093949 大望新平村 南北 5434 15.0 50.0 114.180964 22.603698 [42.5, 60) 1 605768856 通宝楼 南北 3472 7.5 25.0 114.179298 22.566910 [25, 42.5) 2 606815561 罗湖区罗芳村 南北 5842 15.6 52.0 114.158869 22.547223 [42.5, 60) 3 605147285 兴华苑 南北 3829 10.8 36.0 114.158040 22.554343 [25, 42.5) 4 606030866 京基东方都会 西南 47222 51.0 170.0 114.149243 22.554370 [165, 182.5)
# 频率分布情况 - 定量字段 # ③ 求出目标字段下频率分布的其他统计量 → 频数,频率,累计频率 r_zj = pd.DataFrame(gcut_count) r_zj.rename(columns ={gcut_count.name:'频数'}, inplace = True) # 修改频数字段名 r_zj['频率'] = r_zj / r_zj['频数'].sum() # 计算频率 r_zj['累计频率'] = r_zj['频率'].cumsum() # 计算累计频率 r_zj['频率%'] = r_zj['频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示频率 r_zj['累计频率%'] = r_zj['累计频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示累计频率 r_zj.style.bar(subset=['频率','累计频率'], color='green',width=100) # 可视化显示
输出:
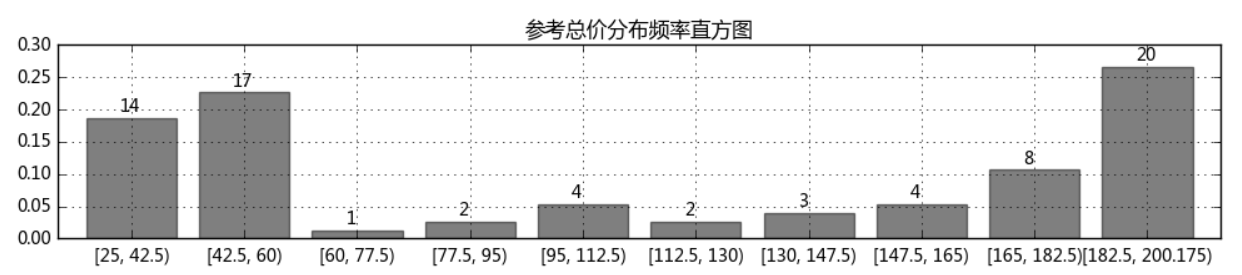
# 频率分布情况 - 定量字段 # ④ 绘制频率直方图 r_zj['频率'].plot(kind = 'bar', width = 0.8, figsize = (12,2), rot = 0, color = 'k', grid = True, alpha = 0.5) plt.title('参考总价分布频率直方图') # 绘制直方图 x = len(r_zj) y = r_zj['频率'] m = r_zj['频数'] for i,j,k in zip(range(x),y,m): plt.text(i-0.1,j+0.01,'%i' % k, color = 'k') # 添加频数标签
输出:
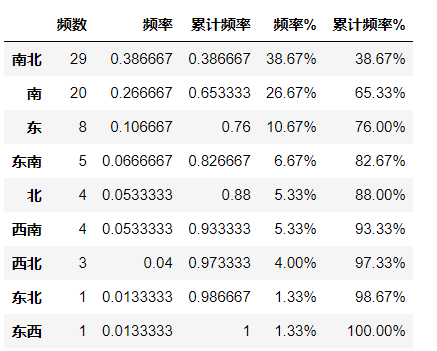
# 频率分布情况 - 定性字段 # ① 通过计数统计判断不同类别的频率 cx_g = data['朝向'].value_counts(sort=True) print(cx_g) # 统计频率 r_cx = pd.DataFrame(cx_g) r_cx.rename(columns ={cx_g.name:'频数'}, inplace = True) # 修改频数字段名 r_cx['频率'] = r_cx / r_cx['频数'].sum() # 计算频率 r_cx['累计频率'] = r_cx['频率'].cumsum() # 计算累计频率 r_cx['频率%'] = r_cx['频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示频率 r_cx['累计频率%'] = r_cx['累计频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示累计频率 r_cx.style.bar(subset=['频率','累计频率'], color='#d65f5f',width=100) # 可视化显示
输出:
南北 29 南 20 东 8 东南 5 北 4 西南 4 西北 3 东北 1 东西 1 Name: 朝向, dtype: int64
# 频率分布情况 - 定量字段 # ② 绘制频率直方图、饼图 plt.figure(num = 1,figsize = (12,2)) r_cx['频率'].plot(kind = 'bar', width = 0.8, rot = 0, color = 'k', grid = True, alpha = 0.5) plt.title('参考总价分布频率直方图') # 绘制直方图 plt.figure(num = 2) plt.pie(r_cx['频数'], labels = r_cx.index, autopct='%.2f%%', shadow = True) plt.axis('equal') # 绘制饼图
输出:

总结:
用到的方法:
pd.cut()
s.value_counts()
思路:
s = df['']
s_cut = pd.cut(s,bins=20)
s_count = s_cut.value_counts() --> intervals 为 索引,intervals段内的数字,为value值。
df1 = pd.DataFrame(s_count) --> 将上面的 Series 转变成 DataFrame。之后的添加 ‘频率’,‘累计频率’,‘频率%’,‘累计频率%’。