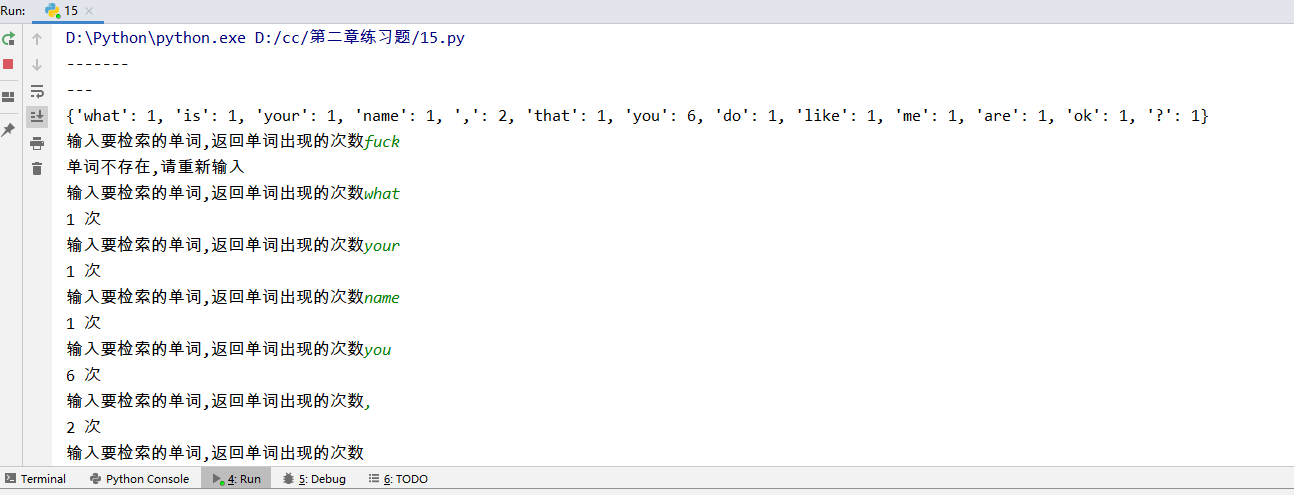
1 li = ["hello", 'seven', ["mon", ["h", "kelly"], 'all'], 123, 446] 2 #根据索引输出“Kelly” 3 print(li[2][1][1]) 4 5 #请使用索引找到’all’元素并将其修改为“ALL”,如:li[0][1][9]… 6 7 # 方法1 8 li[2][2]='ALL' 9 print(li) 10 11 print('-----方法1-----') 12 #方法2 13 li[2][2].upper() 14 print(li) 15 print('-----方法2-----')
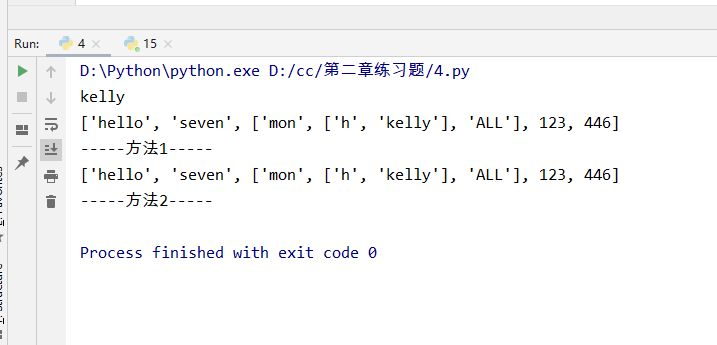
1 tu = ("alex", [11, 22, {"k1": 'v1', "k2": ["age", "name"], "k3": (11,22,33)}, 44]) 2 3 4 #1讲述元组的特性 5 6 #答1: 元组不可被修改 7 8 #2请问tu变量中的第一个元素“alex”是否可被修改? 9 10 #答2: 字符串alex 不可被修改 11 tu[1][0]='1' 12 print(tu) 13 14 #3请问tu变量中的”k2”对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素“Seven” 15 #答3: k2对应的是列表 列表可以被修改 16 tu2=tu[1][2] 17 # tu2 ={"k1": 'v1', "k2": ["age", "name"], "k3": (11,22,33)} 18 tu3 = list(tu2.values()) 19 #dict_values(['v1', ['age', 'name'], (11, 22, 33)]) 20 tu4 =tu3[1] 21 tu4.insert(2,'seven') 22 print(tu) 23 24 #4请问tu变量中的”k3”对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素“Seven” 25 #答:对应的是元组,元组不可以被修改

1 #将字符串s = “alex”转换成列表 2 s= "alex" 3 s1 = list(s) 4 print(type(s1)) 5 6 #将字符串s = “alex”转换成元祖 7 s1=tuple(s) 8 print(type(s1)) 9 10 #将列表li = [“alex”, “seven”]转换成元组 11 li = ["alex","seven"] 12 li2 =tuple(li) 13 print(li2) 14 15 #将元组tu = (‘Alex’, “seven”)转换成列表 16 17 li = ["alex","seven"] 18 li2 =list(li) 19 print(li2) 20 21 #将列表li = [“alex”, “seven”]转换成字典且字典的key按照10开始向后递增 22 23 li = ["alex","seven"] 24 b = [10,11] 25 mydict = dict(zip(b,li)) #zip方法 26 print (mydict)
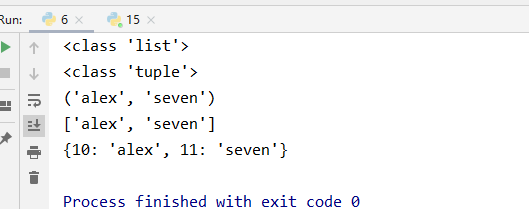
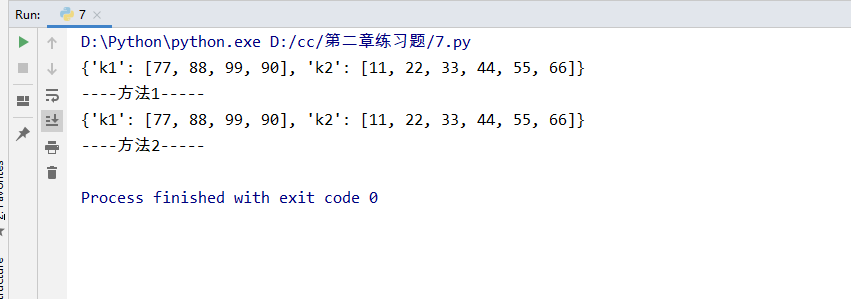
1 '''有如下值集合[11,22,33,44,55,66,77,88,99,90],将所有大于66的值保存至字典的第一个key中, 2 将小于66的值保存至第二个key的值中。 3 即:{‘k1’:大于66的所有值, ‘k2’:小于66的所有值}。(编程题) 4 ''' 5 a =[11,22,33,44,55,66,77,88,99,90] 6 7 #方法1 8 9 a2 =[] 10 a3 =[] 11 12 for i in a: 13 if i >66: 14 a2.append(i) 15 else: 16 a3.append(i) 17 # print(a2) [77, 88, 99, 90] 18 k ={} 19 k['k1'] =a2 # 字典的增加方式 dict[key] = [value1,....] 20 k['k2'] =a3 21 print(k) 22 print('----方法1-----') 23 24 #方法2 25 a =[11,22,33,44,55,66,77,88,99,90] 26 27 k = { 28 'k1': [], 29 'k2': [], 30 } 31 for i in a: 32 if i >66: 33 k['k1'].append(i) 34 else: 35 k['k2'].append(i) 36 print(k) 37 print('----方法2-----')
1 #在不改变列表数据结构的情况下找最大值li = [1,3,2,7,6,23,41,243,33,85,56]。(编程题) 2 3 li = [1,3,2,7,6,23,41,243,33,85,56] 4 # li.sort() #sort 会对原列表结构产生变化 5 print(li) 6 7 l2 = sorted(li) #sorted 不会对原列表结构产生变化 8 print(l2) 9 print(l2[-1])

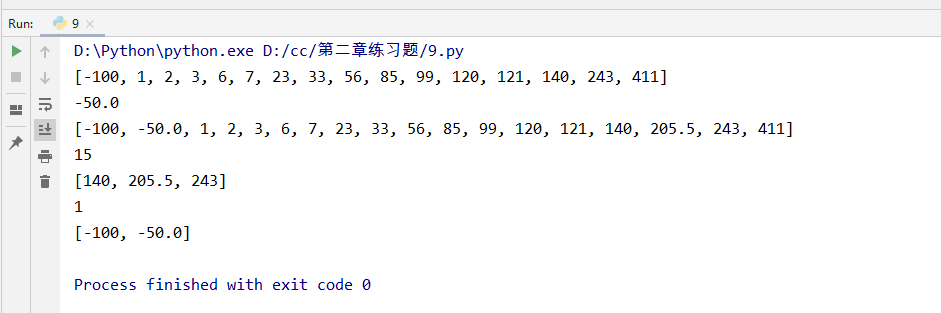
1 '''在不改变列表中数据排列结构的前提下,找出以下列表中最接近最大值和最小值的平均值 的数 2 li = [-100,1,3,2,7,6,120,121,140,23,411,99,243,33,85,56]。(编程题) 3 假设 411是最大值, 411除以2 = 205.5 ,找出205.5旁边的值 ,140 243 4 ''' 5 li = [-100,1,3,2,7,6,120,121,140,23,411,99,243,33,85,56] 6 l2 =sorted(li) #重新排序列表 7 print(l2) #[-100, 1, 2, 3, 6, 7, 23, 33, 56, 85, 99, 120, 121, 140, 243, 411] 8 half_big =l2[-1]/2 #排序后,最后一个是最大值,最大值 除以2 9 half_small=l2[0]/2 ##排序后,第一个是最小值,最小值 除以2 10 print(half_small) 11 l2.append(half_big) 12 l2.append(half_small) #把最大值和最小值 新增到l2列表 13 l2.sort() #继续排序l2 14 print(l2) 15 16 print(l2.index(half_big)) #获取到最大值除以2的结果的下标 17 print(l2[14:17]) #获取下标位置,左边和右边的值 18 print(l2.index(half_small)) #获取到最小值除以2的结果的下标 19 print(l2[0:2]) #获取下标位置,左边和右边的值
1 # 利用for循环和range输出9 * 9乘法表 。(编程题) 2 3 for a in range(1,10): 4 5 # for b in range(a,10): 6 for b in range(1, a+1): 7 8 print("%d*%d=%2d"% (b,a,a*b),end=" | ") 9 print("")

1 #求100以内的素数和。(编程题) 2 3 count=0 4 for i in range(101): 5 if i %2 ==1: 6 count = count+i 7 print(count)

english.txt
what is your name , that you do you like me , are you ok ? you you you
1 #任一个英文的纯文本文件,统计其中的每个单词出现的个数,注意是每个单词。。 2 3 f = open('english.txt','r') 4 data = list(f.read().split(" ")) #转成list,然后用空格分隔每个单词 5 # print(data) 6 f.close() 7 print('-------') 8 9 data2 = [] 10 for i in data: 11 count = data.count(i) 12 # print(i,count,' ',end='') 13 data2.append(i) 14 data2.append(count) 15 # print(data2) 16 k1= data2[::2] #取出所有单词 17 k2= data2[::-2][::-1] #取出所有数字 18 # print(k1) 19 # print(k2) 20 print('---') 21 22 key = dict(zip(k1,k2)) 23 print(key) 24 while 1: 25 26 word1 = input("输入要检索的单词,返回单词出现的次数") 27 if key.get(word1) == None: 28 print('单词不存在,请重新输入') 29 continue 30 31 print(key.get(word1), '次')