1、实验结论
- 同等分区粒度下,使用分区空间索引进行空间查询,比使用全局空间索引进行查询,对数据字典表的访问次数更多。假设分区数为X,则大概多3X次访问。具体说明见6实验结论。
2、实验目的
在之前的测试中,发现这样一个现象:同等分区粒度下,分区空间索引效率不如全局空间索引。可是,深层次的原因是什么呢?
3、实验方法
分别以按县分区、按省分区组织数据,按县分区表共有2531个分区,按省分区表共有43个分区。数据内容为2531个区县,共46982394条要素。分别在两个分区表上创建本地空间索引。
开启10046事件,跟踪SDO_FILTER操作。使用tkpof分析trc文件中耗时最多的SQL,对根据绑定变量的值分析不同SQL(主要是对数据字典的递归查询)查询的数据内容。比较在使用分区索引时所查询的数据字典内容,与在使用全局索引时查询的数据字典内容。
4、实验结果
在使用分区空间索引时,按县分区与按省分区对数据字典的访问次数及返回记录数如下:
- Seg$
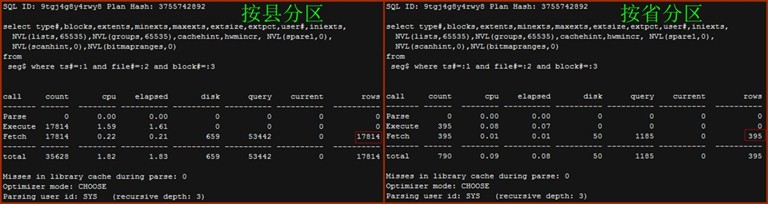
查询内容包括LOB INDEX PARTITION、LOB PARTITION、TABLE PARTITION、少量sys和mdsys用户下的表、其它表。
以按县分区表为例,包括:
INDEX PARTITION : 2531 * 3 = 7593 (此处不包括分区空间索引,仅包括LOB INDEX PARTITION)
LOB PARTITION : 2531 * 3 = 7593
TABLE PARTITION:2531
- Obj$
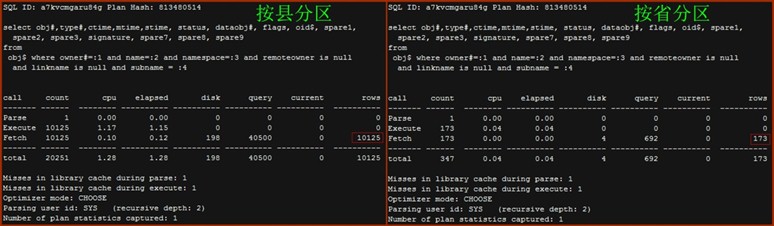
查询内容包括LOB PARTITION、SPATIAL INDEX PARTITION、相关的TABLE PARTITION
以按省分区表分为,包括:
LOB PARTITION : 43 * 3 =129
INDEX PARTITION : 43 (此处包括SPATIAL INDEX PARTITION ,不包括LOB INDEX PARTITION)
TABLE PARTITION : (仅包括与查询范围相关的分区,可忽略不计)
- Lobfrag$
查询内容与全局空间索引下一致。
- Indpart$
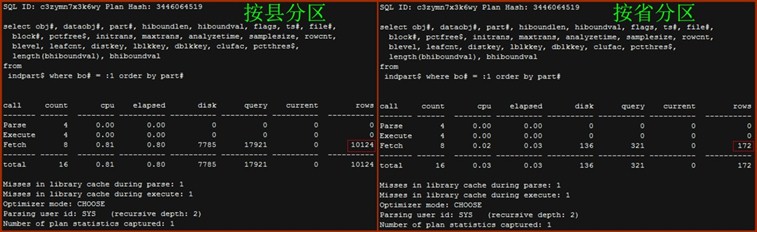
查询内容包括INDEX PARTITION,包括LOB INDEX PARTITON 以及 SPATIAL INDEX PARTITION。
以按省分区表为例,包括:
INDEX PARTITION : 43 * 4 =172
- Obj$(2)

查询内容包括LOB PARTITION、SPATIAL INDEX PARTITION,少量其它表。
以按省分区表为例,包括:
LOB PARTITION : 43 * 3 =129
INDEX PARTITION : 43 (此处包括SPATIAL INDEX PARTITION ,不包括LOB INDEX PARTITION)
其它:82个sys和mdsys用户下的表、以及test用户下的其他一些表,可忽略。
-
Tabpart$
查询内容全局空间索引下一致。
5、实验结论
结合3实验结果中的说明,假设分区数以X表示,lob column个数以Y表示,在使用分区空间索引进行查询时,不同字典表的访问次数见下表:
|
数据字典表 |
访问次数 |
|
Seg$ |
(1+2Y)*X |
|
Lobfrag$ |
XY |
|
Obj$ |
(1+Y)*X |
|
Indpart$ |
(1+Y)*X |
|
Obj$(2) |
(1+Y)*X |
|
Tabpart$ |
X |
若已经获知对各数据字典表的平均访问时间,甚至可以估算查询耗时。在每例中seg$ 、lobfrag$ 、obj$ 、indpart$、obj$(2) 、tabpart$,各数据字典表的平均访问时间约为100us、240us、50us、150us、180us、120us。因此可估算时间为:
Elapsed all= 100*(1+2Y)*X+240XY+50*(1+Y)*X+150*(1+Y)X+180*(1+Y)*X+120X
=X(820Y+600)
与全局索引X(820Y+220)相比,查询数据字典多耗时380X(单位是us)。