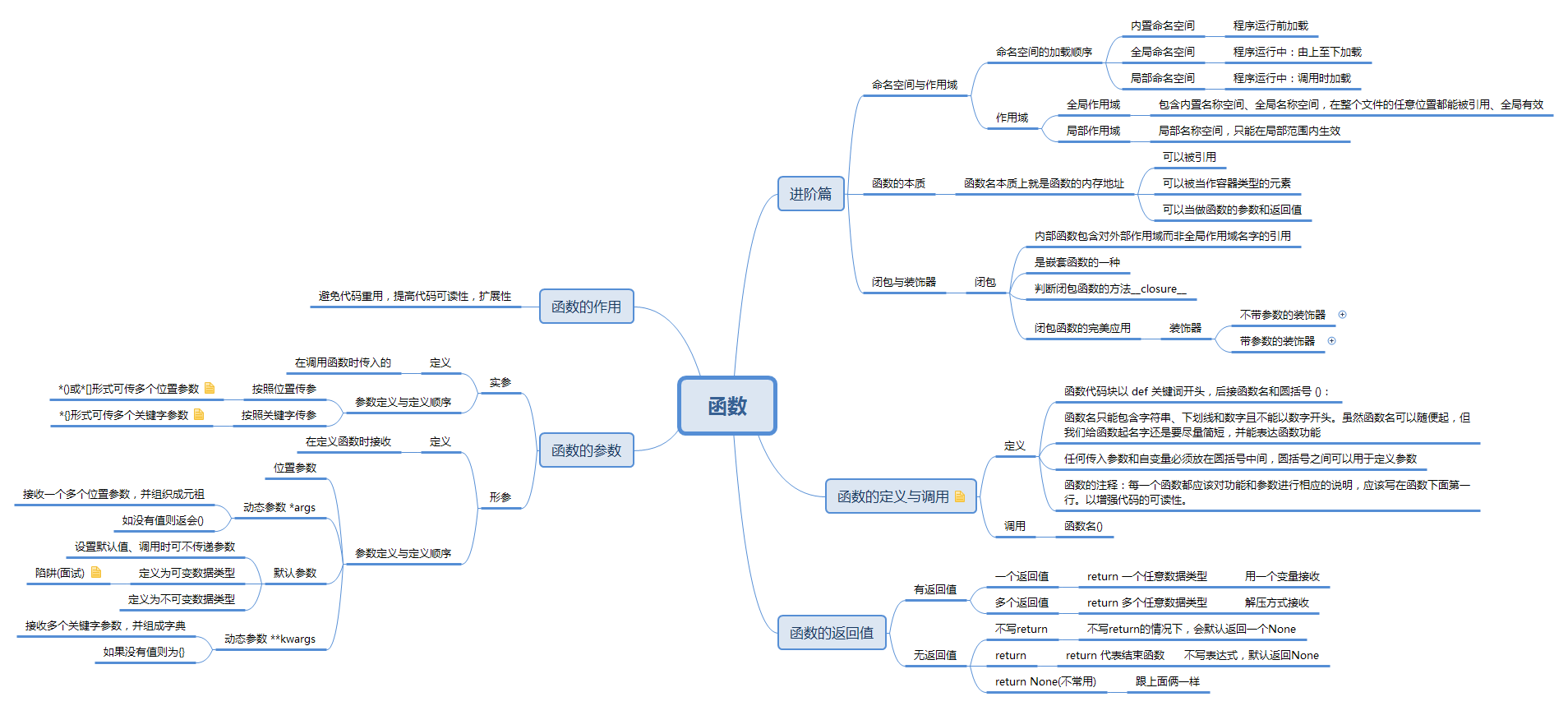
函数
函数的作用
面向过程编程的问题:代码冗余、可读性差、可扩展性差(不易修改)
函数:避免代码重用,提高代码可读性,扩展性
函数的定义与调用


#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) #函数调用 mylen()
总结:
函数定义的规则:
- 函数代码块以 def 关键词开头,后接函数名和圆括号 ():
- 函数名只能包含字符串、下划线和数字且不能以数字开头。虽然函数名可以随便起,但我们给函数起名字还是要尽量简短,并能表达函数功能
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的注释:每一个函数都应该对功能和参数进行相应的说明,应该写在函数下面第一行。以增强代码的可读性。
调用:
函数名() 举个栗子:func()
函数的返回值
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) #函数调用 str_len = mylen() print('str_len : %s'%str_len)
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 return length #函数调用 str_len = mylen() print('str_len : %s'%str_len)
通过对面以上两段代码的运行结果你就会发现一个为None ,一个有值
没有返回值
不写return的情况下,会默认返回一个None。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) #函数调用 str_len = mylen() #因为没有返回值,此时的str_len为None print('str_len : %s'%str_len)
只写return,后面不写其他内容,也会返回None
def ret_demo(): print(111) return print(222) ret = ret_demo() print(ret)
return None:和上面的两种情况一样,一般不这样写。
def ret_demo(): print(111) return None print(222) ret = ret_demo() print(ret) return None
有返回值
返回一个值
return 任意数据类型
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 return length #函数调用 str_len = mylen() print('str_len : %s'%str_len) 返回一个值
PS:return与任意数据类型中间需要空格隔开
返回多个值
可以返回多个值,多个数据类型
def ret_demo1(): '''返回多个值''' return 1,2,3,4 def ret_demo2(): '''返回多个任意类型的值''' return 1,['a','b'],3,4 ret1 = ret_demo1() print(ret1) ret2 = ret_demo2() print(ret2) 返回多个值
PS:返回的多个值会被组织成元组被返回,也可以用多个值来接收
def ret_demo2(): return 1,['a','b'],3,4 #返回多个值,用一个变量接收 ret2 = ret_demo2() print(ret2) #返回多个值,用多个变量接收 a,b,c,d = ret_demo2() print(a,b,c,d) #用多个值接收返回值:返回几个值,就用几个变量接收 a,b,c,d = ret_demo2() print(a,b,c,d) 多个返回值的接收
原因:
>>> 1,2 #python中把用逗号分割的多个值就认为是一个元组。 (1, 2) >>> 1,2,3,4 (1, 2, 3, 4) >>> (1,2,3,4) (1, 2, 3, 4)
#序列解压一 >>> a,b,c,d = (1,2,3,4) >>> a >>> b >>> c >>> d #序列解压二 >>> a,_,_,d=(1,2,3,4) >>> a >>> d >>> a,*_=(1,2,3,4) >>> *_,d=(1,2,3,4) >>> a >>> d #也适用于字符串、列表、字典、集合 >>> a,b = {'name':'eva','age':18} >>> a 'name' >>> b 'age' 序列解压扩展
函数的参数
位置参数
站在实参角度
1.按照位置传值
def mymax(x,y): #此时x=10,y=20 the_max = x if x > y else y return the_max ma = mymax(10,20) print(ma)
2.按照关键字传值
def mymax(x,y): #此时x = 20,y = 10 print(x,y) the_max = x if x > y else y return the_max ma = mymax(y = 10,x = 20) print(ma)
3.位置、关键字形式混着用
def mymax(x,y): #此时x = 10,y = 20 print(x,y) the_max = x if x > y else y return the_max ma = mymax(10,y = 20) print(ma)
正确用法
问题一:位置参数必须在关键字参数的前面
问题二:对于一个形参只能赋值一次
站在形参角度
位置参数必须传值
def mymax(x,y): #此时x = 10,y = 20 print(x,y) the_max = x if x > y else y return the_max #调用mymax不传递参数 ma = mymax() print(ma) #结果 TypeError: mymax() missing 2 required positional arguments: 'x' and 'y'
默认参数
1.正常使用
使用方法
为什么要有默认参数:将变化比较小的值设置成默认参数
2.默认参数的定义
def stu_info(name,sex = "male"): """打印学生信息函数,由于班中大部分学生都是男生, 所以设置默认参数sex的默认值为'male' """ print(name,sex) stu_info('alex') stu_info('eva','female')
3.参数陷阱:默认参数是一个可变数据类型
def defult_param(a,l = []): l.append(a) print(l) defult_param('alex') defult_param('egon')
动态参数
按位置传值多余的参数都由args统一接收,保存成一个元组的形式
def mysum(*args): the_sum = 0 for i in args: the_sum+=i return the_sum the_sum = mysum(1,2,3,4) print(the_sum)
def stu_info(**kwargs): print(kwargs) print(kwargs['name'],kwargs['sex']) stu_info(name = 'alex',sex = 'male')
命名空间与作用域
命名空间一共分为三种:
全局命名空间
局部命名空间
内置命名空间
加载顺序:内置命名空间(程序运行前加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载)
取值:
在局部调用:局部命名空间->全局命名空间->内置命名空间
x = 1 def f(x): print(x) print(10)
在全局调用:全局命名空间->内置命名空间
x = 1 def f(x): print(x) f(10) print(x)
print(max)
作用域
作用域就是作用范围,按照生效范围可以分为全局作用域和局部作用域。
全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效
局部作用域:局部名称空间,只能在局部范围内生效
globals和locals方法
print(globals()) print(locals())
def func(): a = 12 b = 20 print(locals()) print(globals()) func()
global关键字
a = 10 def func(): global a a = 20 print(a) func() print(a)
函数的本质
1.可以被引用
def func(): print('in func') f = func print(f)
2.可以被当作容器类型的元素
def f1(): print('f1') def f2(): print('f2') def f3(): print('f3') l = [f1,f2,f3] d = {'f1':f1,'f2':f2,'f3':f3} #调用 l[0]() d['f2']()
3.可以当作函数的参数和返回值
def wrapper(func): def inner(): ret=func() return ret return inner #函数被当作返回值
闭包
def func():
name = 'eva'
def inner():
print(name)
闭包函数:
内部函数包含对外部作用域而非全局作用域名字的引用,该内部函数称为闭包函数
#函数内部定义的函数称为内部函数
闭包的常用方法
def func(): name = 'eva' def inner(): print(name) return inner f = func() f()
判断闭包函数的方法__closure__
#输出的__closure__有cell元素 :是闭包函数 def func(): name = 'eva' def inner(): print(name) print(inner.__closure__) return inner f = func() f() #输出的__closure__为None :不是闭包函数 name = 'egon' def func2(): def inner(): print(name) print(inner.__closure__) return inner f2 = func2() f2()
def wrapper(): money = 1000 def func(): name = 'eva' def inner(): print(name,money) return inner return func f = wrapper() i = f() i()
from urllib.request import urlopen def index(): url = "http://www.cnblogs.com/Eva-J/articles/7156261.html" def get(): return urlopen(url).read() return get xiaohua = index() content = xiaohua() print(content) 闭包函数获取网络应用
装饰器
def wrapper(func): def inner(*args,**wargs): '''函数执行之前代码块''' ret=func() return ret '''函数执行之后代码块''' return inner
F = False def outer(flag): def wrapper(func): def inner(*args,**kwargs): if flag: print('before') ret = func(*args,**kwargs) print('after') else: ret = func(*args, **kwargs) return ret return inner return wrapper
本张小结