到目前为止,已经叙述了神经网络的监督学习,即学习的样本都是有标签的。现在假设我们有一个没有标签的训练集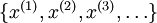 ,其中
,其中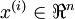 . 自动编码器就是一个运用了反向传播进行无监督学习的神经网络,学习的目的就是为了让输出值和输入值相等,即
. 自动编码器就是一个运用了反向传播进行无监督学习的神经网络,学习的目的就是为了让输出值和输入值相等,即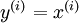 .下面就是一个自动编码器:
.下面就是一个自动编码器:
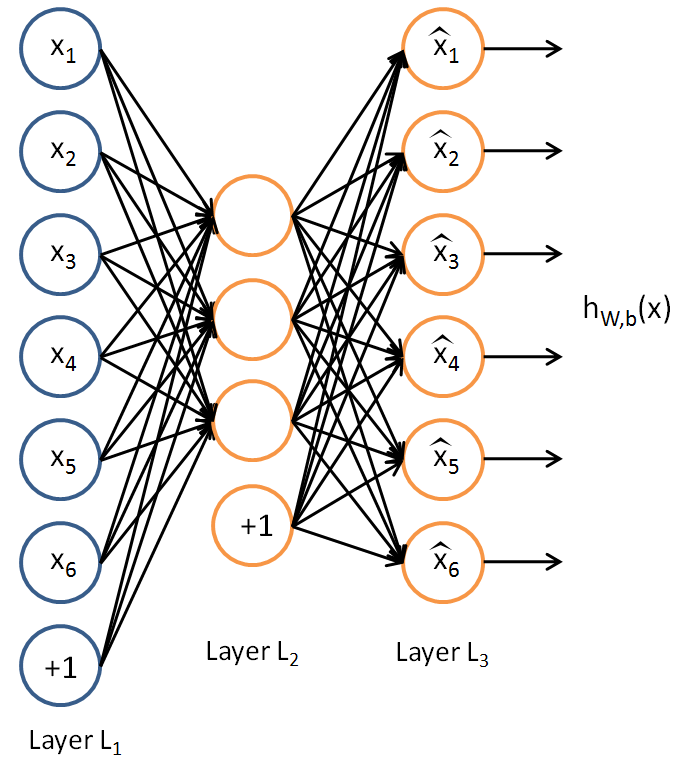
自动编码器试图学习一个函数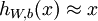 . 换句话说,它试图逼近一个等式函数,使得该函数的输出
. 换句话说,它试图逼近一个等式函数,使得该函数的输出 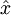 和输入
和输入  很近似。举一个具体的例子,假设输入 是来自一个
很近似。举一个具体的例子,假设输入 是来自一个 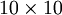 图像(共100个像素点)像素点的灰度值,在
图像(共100个像素点)像素点的灰度值,在 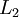 层有
层有 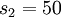 个隐层节点. 注意输出
个隐层节点. 注意输出 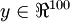 . 由于隐层节点只有50个,所以网络必须学习出输入的压缩表示,即给出以隐层节点激活值作为元素的向量
. 由于隐层节点只有50个,所以网络必须学习出输入的压缩表示,即给出以隐层节点激活值作为元素的向量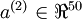 ,它需要重构出100个像素点灰度值的输入 . 如果输入是完全随机的,那么这种压缩学习的任务将会很难,但是数据具有一定的结构,例如一些输入特征彼此关联,那么这个算法就可以发现这些关联关系。事实上,自动编码器往往最终就是学习出一个较低维度的表示。
,它需要重构出100个像素点灰度值的输入 . 如果输入是完全随机的,那么这种压缩学习的任务将会很难,但是数据具有一定的结构,例如一些输入特征彼此关联,那么这个算法就可以发现这些关联关系。事实上,自动编码器往往最终就是学习出一个较低维度的表示。
我们认为,上面讨论是依赖于隐层节点数很少。但是,即使隐层节点数很多(也许比输入的像素点个数还多),通过对网络加上某些约束,我们仍然能够发现感兴趣的结构。特别是,对隐层节点加上稀疏约束。
简答来说,如果一个神经元的输出为1,我们认为这个神经元是被激活的,如果某个神经元的输出是0,就认为这个神经元是抑制的。我们想约束神经元,使得神经元在大多数时候是处于抑制状态。假设激活函数是sigmoid函数。
在上面的网络中,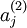 表示隐层(第二层)节点
表示隐层(第二层)节点  的激活值。但是这种表示并没有显示给出哪一个输入 导致了这个激活值。因此,用
的激活值。但是这种表示并没有显示给出哪一个输入 导致了这个激活值。因此,用 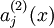 去表示当输入为 时这个隐层节点的激活值。进一步,令
去表示当输入为 时这个隐层节点的激活值。进一步,令
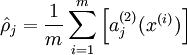
表示隐层单元节点 的平均激活值(对于每一个输入样本,该节点都会输出一个激活值,所以将该节点对应的所有样本的激活值求均值)。然后加以约束:
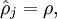
这里,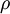 是稀疏参数,通常被设为一个很小的接近于0的值(比如
是稀疏参数,通常被设为一个很小的接近于0的值(比如 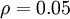 )。换句话说,我们想要隐层神经元 的平均激活值接近 0.05. 为了满足这个约束,隐层节点的激活值必须大多数都接近0.
)。换句话说,我们想要隐层神经元 的平均激活值接近 0.05. 为了满足这个约束,隐层节点的激活值必须大多数都接近0.
为了达到这个目的,我们将在优化目标函数的时候,对那些与 稀疏参数 偏差很大的 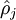 加以惩罚,我们使用下面的惩罚项:
加以惩罚,我们使用下面的惩罚项:
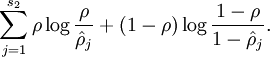
其中 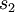 是隐层神经元的数目。这个约束想也可写为:
是隐层神经元的数目。这个约束想也可写为:
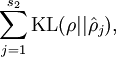
其中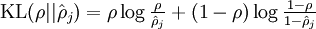 ,容易验证,如果
,容易验证,如果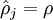 ,
,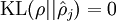 ,如果 和 差值很大,那么该项也会变大。符合我们想要的惩罚方式。例如我们令
,如果 和 差值很大,那么该项也会变大。符合我们想要的惩罚方式。例如我们令 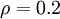 ,画出
,画出
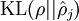 随 变化而变化的情况:
随 变化而变化的情况:
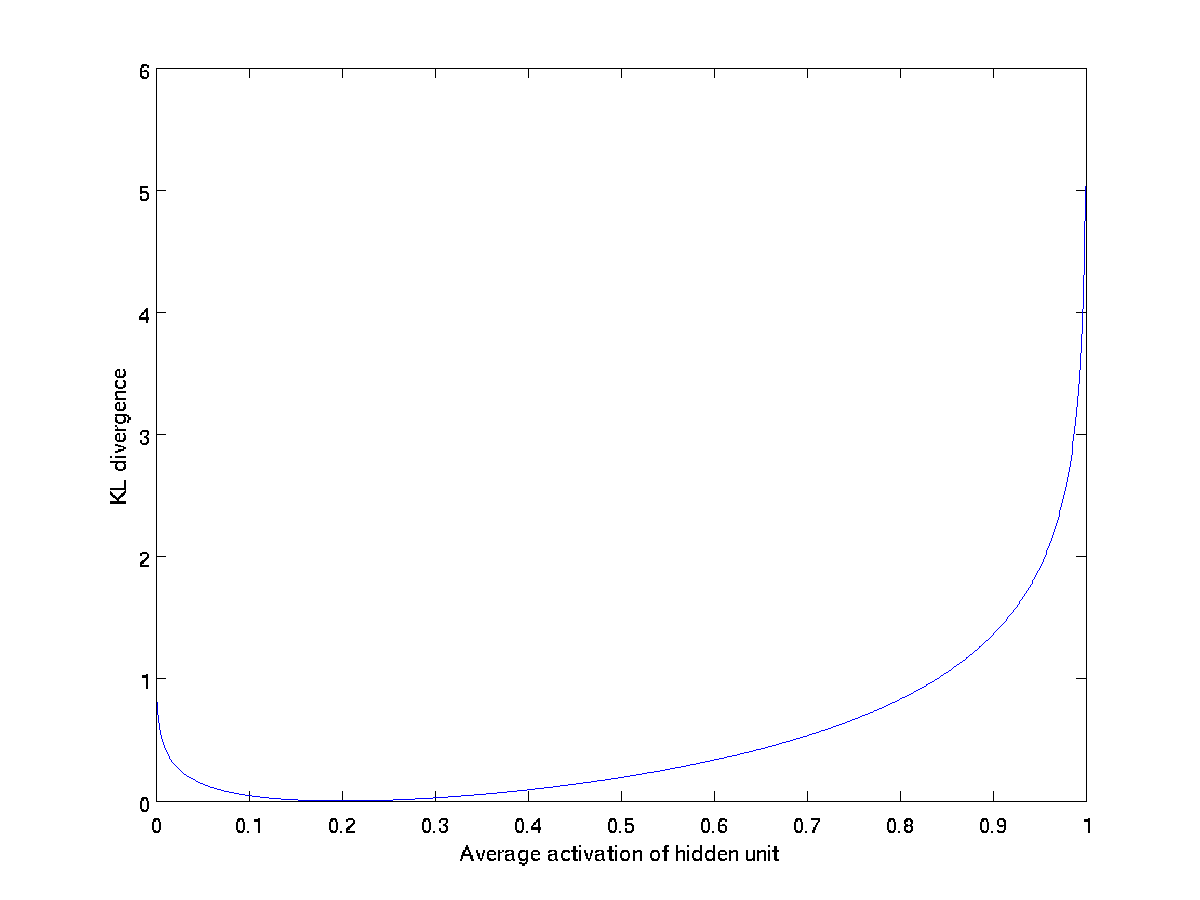
由上图可以看出,在时,函数到达最小值0.但是当无论从左边还是右边远离(0.2)时,函数值显著增大。
于是,我们总体的代价函数(损失函数)就变为:
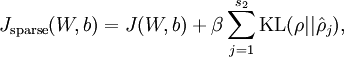
这里的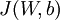 是在前面的博文
是在前面的博文
稀疏自动编码之反向传播算法(BP)
中定义的,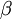 是用来控制稀疏惩罚项的权重。 其实也依赖于
是用来控制稀疏惩罚项的权重。 其实也依赖于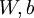 ,因为 是隐层节点的平均激活值,而计算平均激活值,首先需要计算该节点所有激活值,激活值是多少是取决于的(训练集一定)。
,因为 是隐层节点的平均激活值,而计算平均激活值,首先需要计算该节点所有激活值,激活值是多少是取决于的(训练集一定)。
下面把惩罚项加入代价函数,再计算导数。只需在原来的代码中作很小的改动,例如在反向传播的第2层,前面博文中已经计算出:
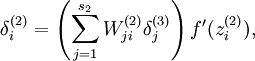
现在用下面的式子代替:
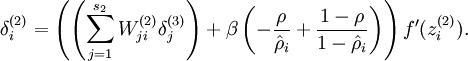
稍微需要注意的是,为了计算这一项,需要知道,因此,在前馈传播过程中首先把隐层所有神经元的平均激活值计算出来。当训练集很小的时候,在前馈传播的时候,把所有神经元的激活值和平均值都存储在内存里,然后在反向传播过程中可以利用这些提取计算好的激活值。如果训练集太大,没有那么多内存存储中间结果,可以在前馈传播过程中先计算每个节点针对所有的样本的激活值,从而计算出该节点的平均激活值,在计算下一个节点的平均激活值的时候就可以丢掉前一个节点的针对所有样本的激活值,值存储它的平均激活值,这样之后,在反向传播之前,就需要再一次前馈传播得到神经元的激活值,这样会让计算效率有些降低,但是保证内存的够用。
整个用梯度下降求解过程的伪代码在
稀疏自动编码之反向传播算法(BP)
中已经给出,只不过目标函数改为这里给出的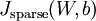 . 然后用
. 然后用
稀疏自动编码之梯度检验
中介绍的导数检验的方法,可以验证代码的正确与否。
学习来源:http://deeplearning.stanford.edu/wiki/index.php/Autoencoders_and_Sparsity