20179226 2017-2018-2 《密码与安全新技术》第6周作业
课程:《密码与安全新技术》
班级: 1792
姓名: 任逸飞
学号:20179226
上课教师:谢四江
上课日期:2018年5月24日
必修/选修: 必修
学习内容总结
一、模式识别的概念
用各种数学方法让计算机(软件与硬件)来实现人的模式识别能力,即用计算机实现人对各种事物或现象的分析、描述、判断、识别。
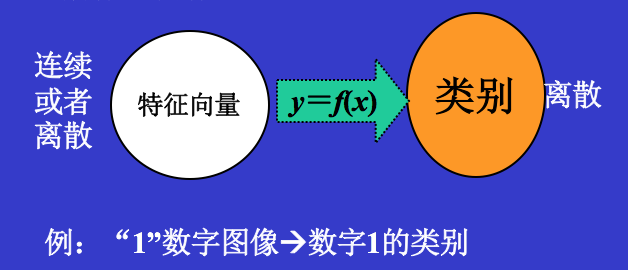
模式识别也可以看成是从特征向量向类别所作的映射。
1.模式或者模式类:可以是研究对象的组成成分或影响因素之间存在的规律性关系,因素之间存在确定性或随机性规律的对象、过程或者事件的集合。
2.识别:对以前见过的对象的再认识。
3.模式识别:对模式的区分与认识,将待识别的对象根据其特征归并到若干类别中的某一类。
4.样本:所研究对象的一个一个个体, 通常有一组特征构成的向量来描述,也称样本向量。。
5.样本集:若干样本的集合。
6.类或者类别:在样本集上定义的模式类子集合,同一类的样本在我们所关心的某种性质上是不可区分的,即具有相同的模式。
7.特征或者属性:描述样本的若干观测值。多个特征或属性构造特征向量或者属性向量,通常与样本向量混用。
模式识别也可以看成是从特征向量向类别所作的映射
二、模式识别的主要方法
1.按问题的描述方式划分
1)基于知识的模式识别方法
以专家系统为代表,根据人们已知的(从专家那里收集整理得到的)知识,整理出若干描述特征与类别间关系的准则,建立一定的计算机推理系统,再对未知样本决策其类别。
2)基于数据的模式识别方法
制定描述研究对象的描述特征,收集一定数量的已知样本作为训练集训练一个模式识别机器,再对未知样本预测其类别(主要研究内容)
2.问题或样本性质
1)监督模式识别(分类):先有一批已知样本作为训练集设计分类器,再判断新的样本类别(分类)
监督模式识别系统的典型框图
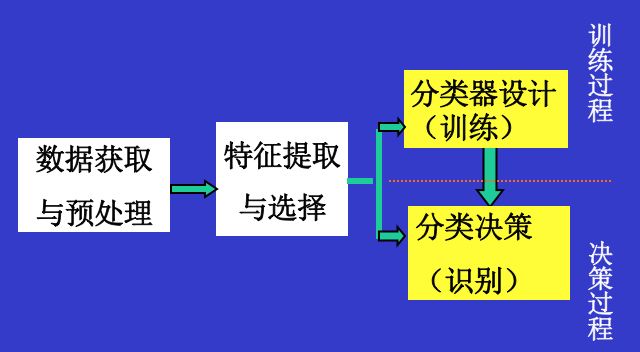
处理监督模式识别问题的一般步骤:
1.分析问题
针对具体的应用,分析是否可以转化成分类问题;
可能有那些类别;
已有的数据或者欲采集的数据中哪些因素或者特征与分类最具关联性。
2.原始数据获取与预处理、特征形成
设计采集数据方式,获取原始数据,并进行预处理
从原始数据获取样本的原始特征
构造出已知样本集
3.特征提取和选择
目的:从原始数据中,得到最能反映分类本质的特征
特征形成:通过各种手段从原始数据中得出反映分类问题的若干特征(有时需进行数据标准化)
特征选择:从特征中选取最有利于分类的若干特征
特征提取:通过某些数学变换,降低特征数目
4.分类器设计
选定某一个分类器,用训练样本集对分类器进行训练,得到分类模型
5.分类决策
利用一定方式对分类器进行性能评价
对未知样本经过观测、预处理、特征形成、特征提取与选择,构造特征向量,用已经设计好的分类器进行决策(预测);
必要时再根据问题的背景知识进行适当的后处理
2)非监督模式识别(聚类):只有一批样本,根据样本之间的相似性直接将样本集划分成若干类别(聚类)
非监督模式识别系统的典型框图
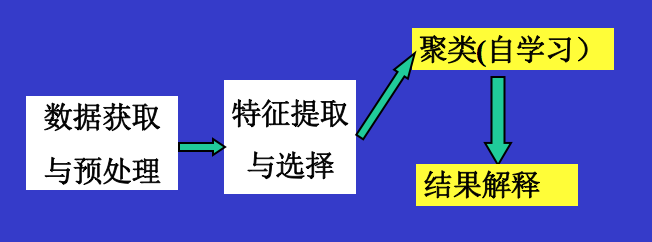
非处理监督模式识别问题的一般步骤:
1.分析问题:
针对具有的应用,分析是否可以转化成聚类问题;
可能或者希望得到的类别数;
已有的数据或者欲采集的数据中那些因素或者特征与聚类相关。
2.原始数据获取与预处理、特征形成
设计采集数据方式,获取原始数据,并进行预处理
从原始数据获取样本的原始特征
构造出无类别标识的样本集(都是未知样本)
3.特征提取和选择
为了更好地进行聚类,经常需要采用一定的算法对原始特征进行提取与选择。一般来说,针对聚类的提取与选择要比分类更困难
4.聚类分析
选定某一个非监督模式识别方法,对样本集进行聚类分析。
5.结果解释
考查聚类结果的性能;
分析聚类结果与研究问题之间的关系;
根据问题背景知识分析聚类结果的可靠性;
解释类的含义;
如果有新样本,可以采用就近原则进行进行分类。
3.理论基础
1)统计模式识别:概率论与数理统计
2)模糊模式识别:模糊逻辑
3)人工神经网络:神经科学、最优化、概率论与数理统计
4)结构模式识别:形式语言
4.应用领域
图像识别、文字识别、数字识别、人脸识别、指纹识别、虹膜识别、掌纹识别、语音识别。
三、模式识别系统举例

四、模式识别系统的典型构成
原始数据获取与预处理
特征提取和选择
分类和聚类
后处理
五、贝叶斯决策理论
1.基于最小错误率的Bayes决策
利用概率论中的Bayes公式进行分类,可以得到错误率最小的分类规则。
2.基于最小风险的Bayes决策
在考虑各种错误能造成不同的损失的情况下的Bayes决策规则。
最小风险的Bayes决策的步骤
1)在已知类先验概率和类概率密度函数的情况下,计算待识x的后验概率
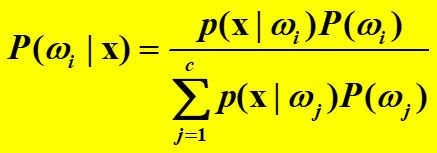
2)根据决策表,计算每一个决策的条件风险
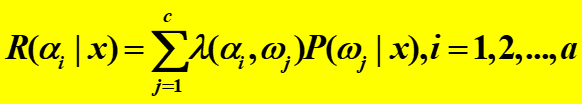
3)找出条件风险最小值所对应的决策,对x采取该决策(归属到该类)

学习中的问题和解决过程
问题1:模式识别和机器学习有什么区别和联系?
问题1解决方案:模式识别是自己建立模型刻画已有的特征,样本是用于估计模型中的参数,落脚点是感知。机器学习根据样本训练模型,如训练好的神经网络是一个针对特定分类问题的模型,重点在于“学习”,训练模型的过程就是学习,落脚点是思考。
其他
通过这一次模式识别的学习,对模式识别的一些基本概念及其系统有了一定了解,对模式识别的一些主要方法也有了一些掌握,最后还了解了贝叶斯公式在模式识别中的运用,收获很大。