1 print 'Hello, world'
数据类型
整数
浮点数:
对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x10^9就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。
字符串:
字符串是以''或""括起来的任意文本,比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。
布尔值:
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来。
布尔值可以用and、or和not运算。
空值:
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
print语句
print会依次打印每个字符串,遇到逗号“,”会输出一个空格,因此,输出的字符串是这样拼起来的:
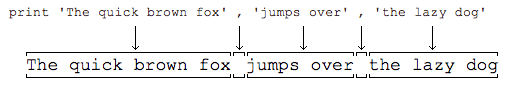
注释#
变量
同一个变量可以反复赋值,而且可以是不同类型的变量,例如:
a = 123 # a是整数 print a a = 'imooc' # a变为字符串 print a
这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。
静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言。
raw字符串与多行字符串
如果一个字符串包含很多需要转义的字符,对每一个字符都进行转义会很麻烦。为了避免这种情况,我们可以在字符串前面加个前缀 r,表示这是一个 raw 字符串,里面的字符就不需要转义了。例如:
r'(~_~)/ (~_~)/'
但是r'...'表示法不能表示多行字符串,也不能表示包含'和 "的字符串(为什么?)
如果要表示多行字符串,可以用'''...'''表示:
'''Line 1 Line 2 Line 3'''
上面这个字符串的表示方法和下面的是完全一样的:
'Line 1 Line 2 Line 3'
还可以在多行字符串前面添加 r ,把这个多行字符串也变成一个raw字符串:
r'''Python is created by "Guido". It is free and easy to learn. Let's start learn Python in imooc!'''
Unicode字符串
字符串还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母 A 的编码是65,小写字母 z 的编码是122。
如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的。
Python在后来添加了对Unicode的支持,以Unicode表示的字符串用u'...'表示,比如:
print u'中文' 中文
注意: 不加 u ,中文就不能正常显示。
Unicode字符串除了多了一个 u 之外,与普通字符串没啥区别,转义字符和多行表示法仍然有效:
转义:
u'中文 日文 韩文'
多行:
u'''第一行 第二行'''
raw+多行:
ur'''Python的Unicode字符串支持"中文", "日文", "韩文"等多种语言'''
如果中文字符串在Python环境下遇到 UnicodeDecodeError,这是因为.py文件保存的格式有问题。可以在第一行添加注释
# -*- coding: utf-8 -*-
目的是告诉Python解释器,用UTF-8编码读取源代码。然后用Notepad++ 另存为... 并选择UTF-8格式保存。
# -*- coding: utf-8 -*- print r'''静夜思 床前明月光, 疑是地上霜。 举头望明月, 低头思故乡。'''