本文来自公众号“AI大道理”
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%,说话人自适应模型词错误率为28.41%,quick模型词错误率为27.94%。
可见quick模型识别率继续有了一定的提高。
能否继续优化模型?又要从哪些方面入手进行优化呢?
火热的深度学习进入了我们的视野。
第一个被取代的就是对发射概率建模的GMM,即DNN-HMM模型。
Kaldi 中实现的 dnn 共 4 种:
a) nnet1 - 基于 Karel's 的实现,特点:简单,仅支持单 GPU, 由 Karel 维护。
b) nnet2 - 基于 Daniel Povey p-norm 的实现,特点:灵活,支持多 GPU、CPU,由 Daniel 维护。
c) nnet3 - nnet2 的改进,由 Daniel 维护。
d.)(nnet3 + chain) - Daniel Povey 改进的 nnet3, 特点:可以实现实时解码,解码速率为 nnet3 的 3~5 倍。

![]()
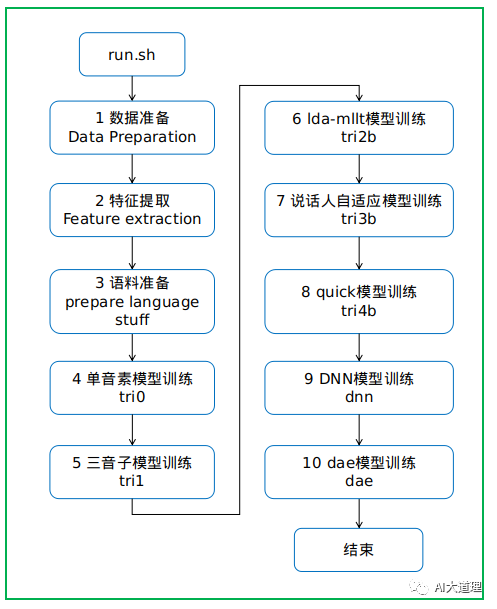
以kaldi的thchs30为例。

![]() 总过程
总过程
![]()
![]() 9 DNN模型训练
9 DNN模型训练
run_dnn.sh
源码解析:

![]()
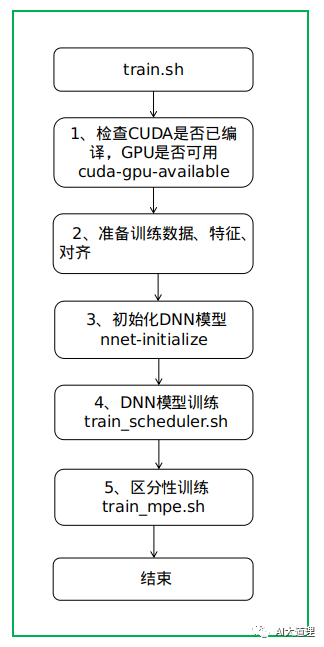
DNN模型训练要用到cuda。

![]()
训练过程:
![]()
thchs-30里面的DNN不是完整的nnet1,使用的特征不一样,也没有进行rbm预训练。
特征提取:
nnet1一般使用 40 维的 fmllr 特征,但在thchs-30中使用的是fbank特征。
为了提高神经网络模型的建模能力,通过拼帧的方法提供上下文。
拼帧后需要进行归一化、去相关操作。若是使用fmllr特征,则在此之前要使用CMVN规整各个维度的均值和方差进行去相关。
而直接使用fbank特征则不用再进行去相关操作,fbank特征本就是不相关的特征。
在fbank特征基础上得到的MFCC特征是相关的。
GMM-HMM模型的假设是输入特征具有独立性,不相关性,上下两帧数据没有关系,因此使用MFCC特征。这个假设本身存在一定问题,不是很合理。
DNN-HMM模型不需要这个假设,相反提供相关性反而有助于模型的提高,因此使用fbank特征。
DNN模型初始化:
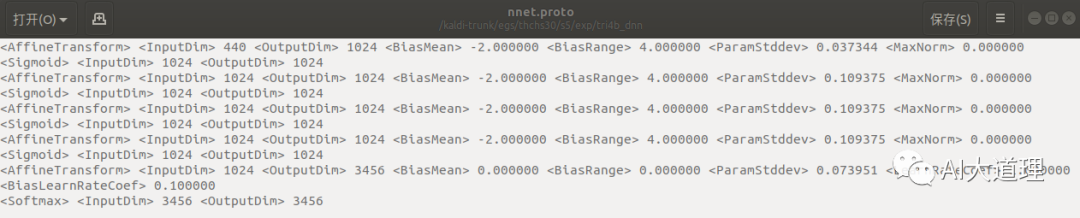
在thchs30中,初始化模型在读取一个nnet.proto的文件,这个文件里面每一行都是一个组件component。
所谓组件就是神经网络中的节点和激活函数。
多个组件组成网络,组件之间以矩阵传递输入和输出。
![]()
dnn的输出个数对应tree的叶子节点数3456。

![]()
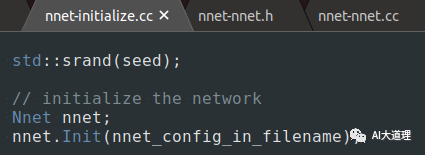
train.sh

![]()
nnet-initialize
![]()
Nnet类函数的实现

![]()
训练:
训练数据需要进行随机化,否则如果数据具有某种稳定变化的分布,最终输出的网络就会倾向于拟合后面若干批次的训练样本。
随机化就是打乱训练样本顺序,对于非序列递归的神经网络来说是按帧打乱的,对于序列递归的网络来说以数据块为单位进行随机化,保留数据块内部的时序性。
nnet1使用单GPU进行训练,读取feats.scp作为训练数据,强制对齐文件作为标签。

![]()
训练完毕。
训练好的DNN模型:
DNN模型部分解码识别(词级别):
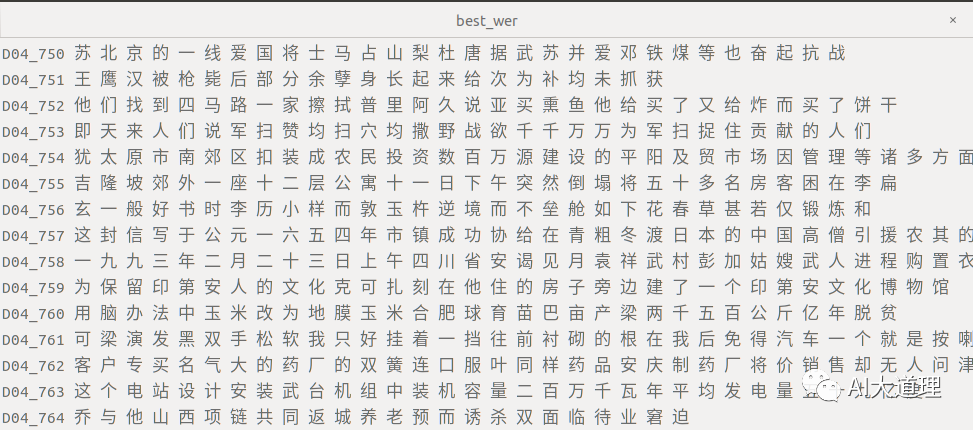
![]()
真正结果(标签词):

![]()
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%,说话人自适应模型词错误率为28.41%,quick模型词错误率为27.94%。
DNN模型词错误率为23.33%。
可见DNN模型识别率继续提高。

![]()
DNN模型部分解码识别(音素级别):

![]()
真正结果(标签音素):

![]()
单音素模型音素错误率为32.43%,三音素模型音素错误率为20.44%,lda-mllt模型音素错误率为17.06%,说话人自适应模型音素错误率为14.98%,quick模型音素错误率为13.53%。
DNN模型音素错误率为10.15%。

![]()
![]() 总结
总结
单音素模型词错误率为50.58%,三音子模型词错误率为36.03%,lda-mllt模型词错误率为32.12%,说话人自适应模型词错误率为28.41%,quick模型词错误率为27.94%。
DNN模型词错误率为23.33%。
可见DNN模型识别率继续提高。

![]()
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————