其实这一篇呢与解决我项目中遇到的问题也是必不可少的。上一篇讲到了各种锁之间的兼容性,里面有一项就是共享锁会引起死锁,如何避免呢,将我们的查询都设置中read uncommitted是否可行呢?其结果显示,当我们当所有的查询都设置成read uncommitted后,后面共享锁死锁基本消除了,看来还是管用的。好了下面接着翻译:
Last time we discussed a few major lock types that SQL Server uses. Shared(S), Exclusive(X) and Update(U). Today I’d like to talk about transaction isolation levels and how they affect locking behavior. But first, let’s start with the question: “What is transaction?”
上一次我们讨论了一些主要的SQL SERVER锁类型:共享锁(S),排它锁(X),以及更新锁(U)。今天我们来讲事务级别是如何影响锁的行为的。但在这之前,我们需要从一个问题开始:“什么是事务”?
Transaction is complete unit of work. Assuming you transfer money from checking account to saving, system should deduct money from the checking and add it to the saving accounts at once. Even if those are 2 independent operations, you don’t want it to “stop at the middle”, well at least in the case if bank deducts it from the checking first ![]() If you don’t want to take that risk, you want them to work as one single action.
If you don’t want to take that risk, you want them to work as one single action.
事务是一个完整的单元工作模式。假如你从支票帐户中将钱转移到储蓄卡中,银行系统首先会从你的支票帐户中扣钱,然后再往你的储蓄卡中存钱。即使这是两个相互独立的操作,你也不想让其在中间的某一步停止,至少不能停止在银行将你的钱从支票帐户中扣除之后![]() 。如果你不冒这个风险,那么你希望这两步操作最好是一步操作来完成。
。如果你不冒这个风险,那么你希望这两步操作最好是一步操作来完成。
There is useful acronym – ACID – that describes requirements to transaction:
这里有一个非常有用的编写-ACID,它将描述事务的需求:
- (A) – Atomicity or “all or nothing”. Either all changes are saved or nothing changed.
(A)-它代表所有或者是无,要么全部保存要么不保存任何数据
- (C) – Consistency. Data remains in consistent stage all the time
(C)-数据每时每刻要保持一致性
- (I) – Isolation. Other sessions don’t see the changes until transaction is completed. Well, this is not always true and depend on the implementation. We will talk about it in a few minutes
(I)-数据隔离,其它的会话看不到事务未提交的数据。这句并不总是正确的,有时依赖于系统的实现,我们后续会讲到。
- (D) – Durability. Transaction should survive and recover from the system failures
(D)-数据可以回滚,当事务执行出现异常的情况下
There are a few common myths about transactions in SQL Server. Such as:
下面是一些公共的关于事务的错误观点,例如:
- There are no transactions if you call insert/update/delete statements without begin tran/commit statements. Not true. In such case SQL Server starts implicit transaction for every statement. It’s not only violate consistency rules in a lot of cases, it’s also extremely expensive. Try to run 1,000,000 insert statements within explicit transaction and without it and notice the difference in execution time and log file size.
当我们直接写insert/update/delete这句语句时,如果没有显示的写begin tran/commit 这类语句就不存在事务。这是不正确的,实际上SQL SERVER 会隐式的为每次SQL操作都加了事务。这不光违反了数据一致性规则且往往造成的后果是非常昂贵的。可以去尝试往一个表中插入1000000条数据,第一种显示的加上事务语句,第二种不加事务语句,执行之后对比下执行的时间以及日志大小的不同。
- There is no transactions for select statements. Not true. SQL Server uses (lighter) transactions with select statements.
当执行select语句时没有事务。这是不正确的,SQL SERVER会使用轻量级的事务。
- There is no transactions when you have (NOLOCK) hint. Not true. (NOLOCK) hint downgrades the reader to read uncommitted isolation level but transactions are still in play.
当们们在select语句后面加了nolock后,就没有事务了。这也是不正确的。nolock只是降低了事务必有隔离级别为read uncommitted而已并不是没有事务。
Each transaction starts in specific transaction isolation level. There are 4 “pessimistic” isolation levels: Read uncommitted, read committed, repeatable read and serializable and 2 “optimisitic” isolation levels: Snapshot and read committed snapshot. With pessimistic isolation levels writers always block writers and typically block readers (with exception of read uncommitted isolation level). With optimistic isolation level writers don’t block readers and in snapshot isolation level does not block writers (there will be the conflict if 2 sessions are updating the same row). We will talk about optimistic isolation levels later.
每个事务都在指定的事务级别中,这里有四种悲观事务必有隔离级别:Read uncommitted (允许脏读),read committed(不允许脏读),repeatable(可重复读),serialzable以及两种经过优化后的事务级别:Snapshot 以及read committed snapshot。
注:这里事务隔离级别比较多,我理解不也太多,就省略掉了。我们比较常见的就是前面的两种,允许脏读以及不允许脏读的情况。至于后面的有关镜像相关的内容这里我不做多的翻译。
Regardless of isolation level, exclusive lock (data modification) always held till end of transaction. The difference in behavior is how SQL Server handles shared locks. See the table below:
排它锁不管事务级别,它总是占用锁到整个事务结束:

So, as you can see, in read uncommitted mode, shared locks are not acquired – as result, readers (select) statement can read data modified by other uncommitted transactions even when those rows held (X) locks. As result any side effects possible. Obviously it affects (S) lock behavior only. Writers still block each other.
所以,就像你看到的,如果在允许脏读的模式下,是不需要申请共享锁的,可以读取到其实事务还未完全提交的数据,即使这些数据已经被加上了排它锁。但这只影响共享锁,对于写的会话仍然会存在相互阻塞甚至死锁的情况。
In any other isolation level (S) locks are acquired and session is blocked when it tries to read uncommitted row with (X) lock. In read committed mode (S) locks are acquired and released immediately. In Repeatable read mode, (S) locks are acquired and held till end of transaction. So it prevents other session to modify data once read. Serializable isolation level works similarly to repeatable read with exception that locks are acquired on the range of the rows. It prevents other session to insert other data in-between once data is read.
共享锁可以任意事务隔离级别中发生,当它尝试去读取其它事务未提交的数据(行上加了排它锁)时就是会阻塞。在Read committed 模式下,共享锁的申请以及释放都是非常迅速的。在Repeatable read模式下,共享锁被申请后一直占用到事务结束,它保证其它会话不编辑其已经读取到的数据。Serializable 模式的工作方式和Repeatable非常相似,但它会锁定一定范围的数据,访问其它会话插入数据。
注:这块还没理解到位,后续有时间再补充下。
You can control that locking behavior with “set transaction isolation level” statement – if you want to do it in transaction/statement scope or on the table level with table hints. So it’s possible to have the statement like that:
在你的事务中或者是表级间的查询你可以通过设置事务隔离级别来控制锁行为,就像下面的查询语句: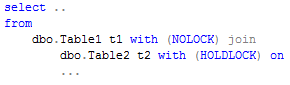
So you access Table1 in read uncommitted isolation level and Table2 in serializable isolation level.
这条语句的作用就是你可以对Table1读取其它事务未提交的数据,以serializable隔离级别读取Table2的数据。
It’s extremely easy to understand the difference between transaction isolation levels behavior and side effects when you keep locking in mind. Just remember (S) locks behavior and you’re all set.
这将非常容易理解事务隔离级别行为之间的差别以及它们的副作用,你只需要记住共享锁以及你所有的设置。
Next time we will talk why do we have blocking in the system and what should we do to reduce it.
下一次我们将会讲到为什么我们的系统中会存在阻塞以及我们如何做才能减少阻塞的发生