SVM
SVM的原理是什么?
SVM是一种二类分类模型。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。(间隔最大使它有别于感知机)
(1)当训练集线性可分时,通过硬间隔最大化,学习一个线性分类器(线性可分支持向量机);
(2)当训练集近似线性可分时(比如有噪声),引入松弛变量,通过软间隔最大化,学习一个线性分类器(即线性支持向量机);
(3)当训练集线性不可分时,通过使用核技巧及软间隔最大化,学习(非线性支持向量机)。
注:以上各SVM的数学推导应该熟悉:硬间隔最大化(几何间隔)---对偶问题---软间隔最大化(引入松弛变量)---非线性支持向量机(核技巧)。
SVM为什么采用间隔最大化?
当训练集线性可分时,存在无穷个分离超平面可以将两类数据正确分开。
感知机利用误分类最小策略,求得分离超平面,不过此时的解有多个。
线性可分支持向量机利用间隔最大化求得最优分离超平面,这时解是唯一的。另一方面,此时的最优分离超平面对未知点的泛化能力最强。
然后应该借此阐述,几何间隔,函数间隔,及从函数间隔—>求解最小化1/2 ||w||^2 时的w和b。即线性可分支持向量机学习算法—最大间隔法的由来。
为什么要把原问题转换为对偶问题?(两点)
因为原问题是凸二次规划问题,转换为对偶问题更加高效。 对偶问题往往更易求解(当我们寻找约束存在时的最优点的时候,约束的存在虽然减小了需要搜寻的范围,但是却使问题变得更加复杂。为了使问题变得易于处理,我们的方法是把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点。)
并且可以引入核函数,进而推广到非线性分类问题
为什么SVM要引入核函数?
当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
引入映射后的对偶问题:

在学习预测中,只定义核函数K(x,y),而不是显式的定义映射函数ϕ。因为特征空间维数可能很高,甚至可能是无穷维,因此直接计算ϕ(x)·ϕ(y)是比较困难的。相反,直接计算K(x,y)比较容易(即直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果)。
核函数的定义:K(x,y)=<ϕ(x),ϕ(y)>,即在特征空间的内积等于它们在原始样本空间中通过核函数K计算的结果。
除了 SVM 之外,任何将计算表示为数据点的内积的方法,都可以使用核方法进行非线性扩展。
svm RBF核函数的具体公式?
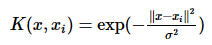
Gauss径向基函数则是局部性强的核函数,其外推能力随着参数σ的增大而减弱。这个核会将原始空间映射为无穷维空间。
如果σ选得很大的话,高次特征上的权重实际上衰减得非常快,使用泰勒展开就可以发现,当很大的时候,泰勒展开的高次项的系数会变小得很快,所以实际上相当于一个低维的子空间;
如果σ选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题,因为此时泰勒展开式中有效的项将变得非常多,甚至无穷多,那么就相当于映射到了一个无穷维的空间,任意数据都将变得线性可分,总的来说,通过调控参数σ ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
为什么求解对偶问题更加高效?
因为只用求解alpha系数,而alpha系数只有支持向量才非0,其他全部为0.
alpha系数有多少个?
样本点的个数
SVM适合处理什么样的数据?
高维稀疏,样本少。
为什么SVM训练的时候耗内存,而预测的时候占内存少?
因为SVM训练过程中需要存储核矩阵。而预测的时候只需要存储支持向量和相关参数。
在SMO中,什么叫违反KKT条件最严重的?
每一个α对应一个样本,而KKT条件是样本和对应的α应该满足的关系。所谓违反最严重是指α对应的样本错得最离谱
SVM多分类
SVM本身是一个二分类器,但是可以拓展到多分类,构造SVM多分类器的方法有两种
直接法:直接在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类。这种方法计算复杂度比较高,实现起来比较困难;
间接法:主要是通过组合多个二分类器来实现多分类器的构造
具体见链接SVM多分类的两种方式
SVM的推导
见《统计学习方法》或 笔记:函数间隔—>几何间隔—>几何间隔最大化—>函数间隔最大化—>令r^=1—> max 变 min—->拉格朗日函数—->求解对偶问题的3个步骤
(1)线性可分 (2)线性近似可分 (3)线性不可分
SVM与LR的区别与联系
联系:(1)分类(二分类) (2)可加入正则化项
区别:(1)LR–参数模型;SVM–非参数模型?(2)目标函数:LR—logistical loss;SVM–hinge loss
(3)SVM–support vectors;LR–减少较远点的权重
(4)LR–模型简单,好理解,精度低,可能局部最优;SVM–理解、优化复杂,精度高,全局最优,转化为对偶问题—>简化模型和计算
(5)LR可以做的SVM可以做(线性可分),SVM能做的LR不一定能做(线性不可分)
如何防止SVM过拟合(提高泛化能力)
松弛变量的平方和?
介绍你所知道的几种核函数
多项式~,高斯~,拉普拉斯~,sigmoid~;线性~
SVM的应用
模式识别领域中的文本识别、中文分类、人脸识别等;工程技术、信息过滤等。
SVM的优缺点
优点:(7)学习问题可表示为凸优化问题—->全局最小值 (8)可自动通过最大化边界控制模型,但需要用户指定核函数类型和引入松弛变量 (9)适合于小样本,优秀泛化能力(因为结构风险最小) (10)泛化错误率低,分类速度快,结果易解释
缺点:(1)大规模训练样本(m阶矩阵计算) (2)传统的SVM不适合多分类 (3)对缺失数据、参数、核函数敏感
LR和SVM的联系与区别:
联系:
1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型,SVM是非参数模型。
2、目标函数不同,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss.这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
神经网络
逻辑回归(LR)
Logistic回归算法,名字虽带有回归,但其实是一个分类模型。