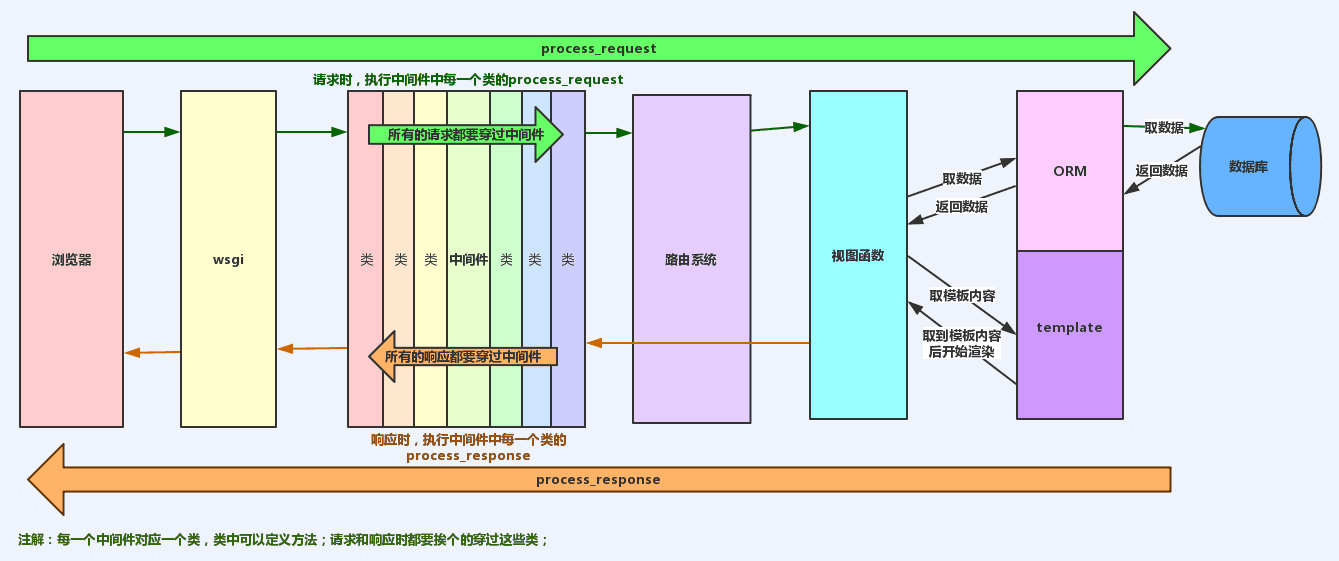
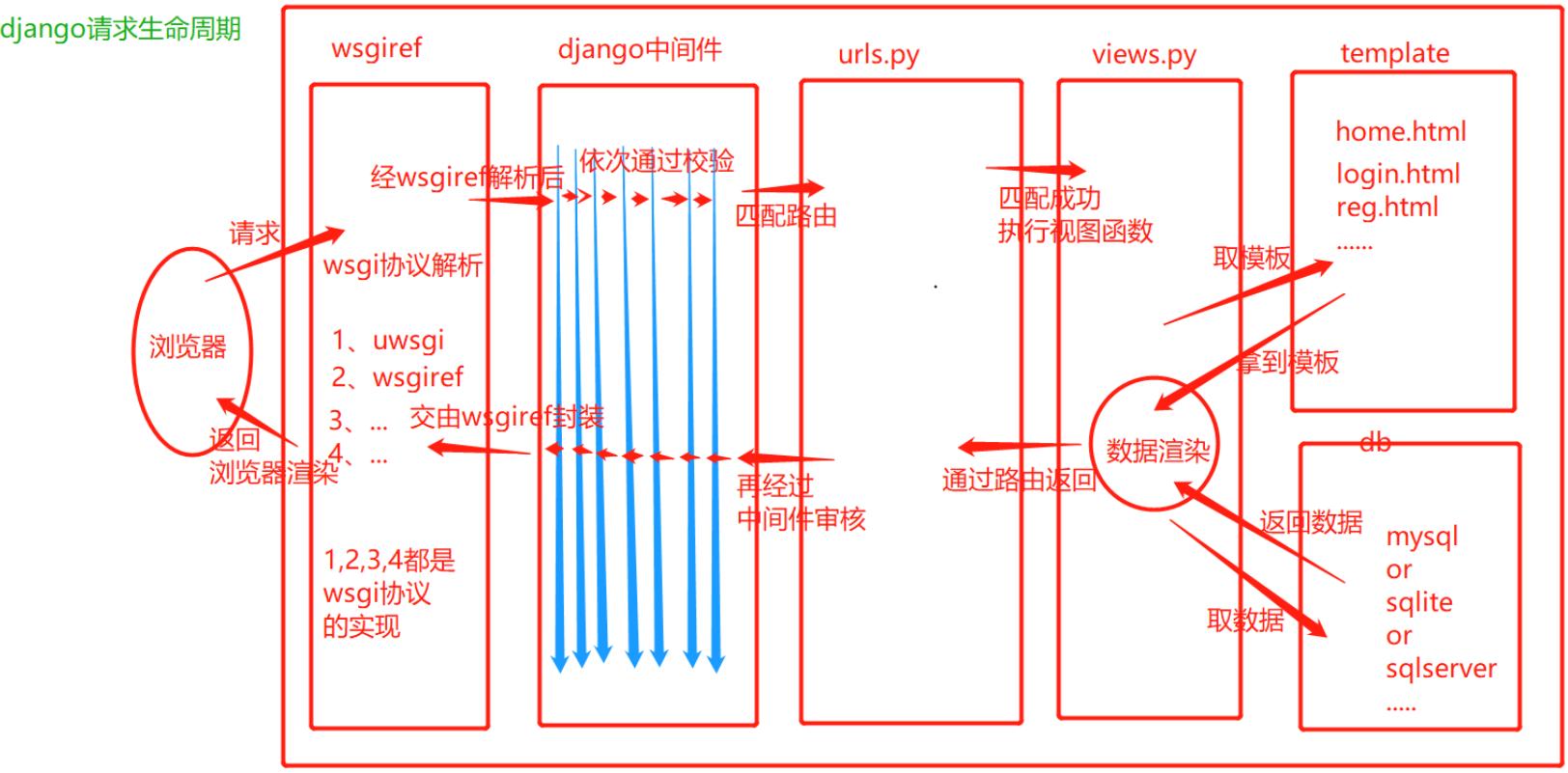
Django请求生命周期
-
- wsgi, 他就是socket服务端,用于接收用户请求并将请求进行初次封装,然后将请求交给web框架(Flask、Django)
-
- 中间件,帮助我们对请求进行校验或在请求对象中添加其他相关数据,例如:csrf、request.session
-
- 路由匹配
-
- 视图函数,在视图函数中进行业务逻辑的处理,可能涉及到:orm、templates => 渲染
-
- 中间件,对响应的数据进行处理。
-
- wsgi,将响应的内容发送给浏览器。
表与表之间建立关系
就以图书管理系统为例
书籍表:
书籍和出版社是一对多,外键字段建在书籍表中(建在多的一方里)
书籍和作者是多对多,需要第三张表记录多对多的关系
Django ORM中表与表之间建立关系 一对多 —— ForeignKey(to='Publish')(建在多的那张表里)
一对一 —— OneToOneField(to='AuthorDetail')(建在查询频率高的那张表)
多对多 —— ManyToManyField(to='Author')
注意:
前面两个关键字会自动再字段后面加_id
最后一个关键字 并不会产生实际字段 只是告诉django orm自动创建第三张表
models.py文件
from django.db import models
# Create your models here.
class Book(models.Model):
# id自动创建 可以不写
title = models.CharField(max_length=64)
# 共8位 小数部分占两位
price = models.DecimalField(max_digits=8,decimal_places=2)
# 书籍和出版社是一对多的外键关系
publish = models.ForeignKey(to='Publish') # to表示的就是跟哪张表是一对多的关系 默认都是跟表的主键字段建立关系
"""
只要是ForeignKey的字段 django orm在创建表的时候 会自动在一对多的字段名之后加_id
如果你自己加了 不管 还会继续往后加
"""
# publish = models.ForeignKey(to=Publish) # to后面也可以直接写表名 但是必须保证表名在上面
# 书籍和作者是多对多的关系
authors = models.ManyToManyField(to='Author') # 不会在表中生成authors字段 该字段是一个虚拟字段 仅仅是用来告诉django orm自动帮你创建书籍和作者的第三张关系表
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 作者与作者详情 是一对一的外键关系
author_detail = models.OneToOneField(to='AuthorDetail',null=True)
"""
也会自动再字段名后面加_id
"""
class AuthorDetail(models.Model):
phone = models.BigIntegerField()
addr = models.CharField(max_length=32)
路由层
url()方法 第一个参数 其实是一个正则表达式
一旦前面的正则匹配到了内容 就不会再往下继续匹配 而是直接执行对应的视图函数
正是由于上面的特性 当你的项目特别庞大的时候 url的前后顺序也是你需要你考虑
极有可能会出现url错乱的情况
urls.py文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^login/', views.login),
url(r'^reg/', views.reg),
url(r'^userlist/', views.user_list),
url(r'^del_user/', views.del_user),
url(r'^update_user/', views.update_user),
url(r'^add/', views.add),
]
django在路由的匹配的时候 当你在浏览器中没有敲最后的斜杠
django会先拿着你没有敲斜杠的结果取匹配 如果都没有匹配上 会让浏览器在末尾加斜杠再发一次请求 再匹配一次 如果还匹配不上才会报错
如果你想取消该机制 不想做二次匹配可以在settings配置文件中 指定
APPEND_SLASH = False # 该参数默认是True
无名分组
#路由匹配的时候 会将括号内正则表达式匹配到的内容 当做位置参数传递给视图函数
url(r'^test/([0-9]{4})/', views.test)
test(request,2019)
有名分组
#路由匹配的时候 会将括号内正则表达式匹配到的内容 当做关键字参数传递给视图函数
url(r'^test/(?P<year>d+)/', views.test)
test(request,year=2019)
# 无名有名不能混合使用 !!!
# 无名有名不能混合使用 !!!
url(r'^test/(d+)/(?P<year>d+)/', views.test),
#但是用一种分组下 可以使用多个
# 无名分组支持多个
url(r'^test/(d+)/(d+)/', views.test),
# 有名分组支持多个
url(r'^test/(?P<year>d+)/(?P<xx>d+)/', views.test)
反向解析
本质:其实就是给你返回一个能够返回对应url的地址
1.先给url和视图函数对应关系起别名
url(r'^index/$',views.index,name='kkk')
2.反向解析
#后端反向解析
#后端可以在任意位置通过reverse反向解析出对应的url
from django.shortcuts import render,HttpResponse,redirect,reverse
reverse('kkk')
#前端反向解析
{% url 'kkk' %}
无名分组反向解析
url(r'^index/(d+)/$',views.index,name='kkk')
#后端反向解析
reverse('kkk',args=(1,)) # 后面的数字通常都是数据的id值
#前端反向解析
{% url 'kkk' 1%} # 后面的数字通常都是数据的id值
有名分组反向解析
#同无名分组反向解析意义的用法
url(r'^index/(?P<year>d+)/$',views.index,name='kkk')
#后端方向解析
print(reverse('kkk',args=(1,))) # 推荐你使用上面这种 减少你的脑容量消耗
print(reverse('kkk',kwargs={'year':1}))
#前端反向解析
<a href="{% url 'kkk' 1 %}">1</a> # 推荐你使用上面这种 减少你的脑容量消耗
<a href="{% url 'kkk' year=1 %}">1</a>
#注意:在同一个应用下 别名千万不能重复!!!
路由分发
当你的django项目特别庞大的时候 路由与视图函数对应关系特别特别多
那么你的总路由urls.py代码太过冗长 不易维护
每一个应用都可以有自己的urls.py,static文件夹,templates文件夹(******)
正是基于上述条件 可以实现多人分组开发 等多人开发完成之后 我们只需要创建一个空的django项目
然后将多人开发的app全部注册进来 在总路由实现一个路由分发 而不再做路由匹配(来了之后 我只给你分发到对应的app中)
当你的应用下的视图函数特别特别多的时候 你可以建一个views文件夹 里面根据功能的细分再建不同的py文件(******)
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^app01/',include('app01.urls')),
url(r'^app02/',include('app02.urls')),
]
名称空间(了解)
多个app起了相同的别名 这个时候用反向解析 并不会自动识别应用前缀
如果想避免这种问题的发生
方式1:
#总路由
url(r'^app01/',include('app01.urls',namespace='app01'))
url(r'^app02/',include('app02.urls',namespace='app02'))
#后端解析的时候
reverse('app01:index')
reverse('app02:index')
#前端解析的时候
{% url 'app01:index' %}
{% url 'app02:index' %}
方式2:
#起别名的时候不要冲突即可 一般情况下在起别名的时候通常建议以应用名作为前缀
name = 'app01_index'
name = 'app02_index'
伪静态
静态网页:数据是写死的 万年不变
伪静态网页的设计是为了增加百度等搜索引擎seo查询力度
所有的搜索引擎其实都是一个巨大的爬虫程序
网站优化相关 通过伪静态确实可以提高你的网站被查询出来的概率
但是再怎么优化也抵不过RMB玩家
虚拟环境
一般情况下 我们会给每一个项目 配备该项目所需要的模块 不需要的一概不装
虚拟环境 就类似于为每个项目量身定做的解释器环境
每创建一个虚拟环境 就类似于你又下载了一个全新的python解释器
Django版本的区别
django1.X跟django2.X版本区别
路由层1.X用的是url
而2.X用的是path
2.X中的path第一个参数不再是正则表达式,而是写什么就匹配什么 是精准匹配
当你使用2.X不习惯的时候 2.X还有一个叫re_path
2.x中的re_path就是你1.X的url
虽然2.X中path不支持正则表达式 但是它提供了五种默认的转换器
1.0版本的url和2.0版本的re_path分组出来的数据都是字符串类型
默认有五个转换器,感兴趣的自己可以课下去试一下
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
path('index/<int:id>/',index) # 会将id匹配到的内容自动转换成整型
还支持自定义转换器
class FourDigitYearConverter: regex = '[0-9]{4}' def to_python(self, value): return int(value) def to_url(self, value): return '%04d' % value 占四位,不够用0填满,超了则就按超了的位数来! register_converter(FourDigitYearConverter, 'yyyy') urlpatterns = [ path('articles/2003/', views.special_case_2003), path('articles/<yyyy:year>/', views.year_archive), ... ]
视图层
1.小白必会三板斧
1.HttpResponse
2.render
3.redirect
django视图函数必须要给返回一个HttpResponse对象
前后端分离
前端一个人干(前端转成自定义对象)
JSON.stringify() json.dumps()
JSON.parse() json.loads()
后端另一个干(python后端用字典)
只要涉及到数据交互,一般情况下都是用的json格式
后端只负责产生接口,前端调用该接口能拿到一个大字典
后端只需要写一个接口文档 里面描述字典的详细信息以及参数的传递
2.JsonReponse
from django.http import JsonResponse
def index(request):
data = {'name':'jason好帅哦 我好喜欢','password':123}
l = [1,2,3,4,5,6,7,8]
# res = json.dumps(data,ensure_ascii=False)
# return HttpResponse(res)
# return JsonResponse(data,json_dumps_params={'ensure_ascii':False})
return JsonResponse(l,safe=False) # 如果返回的不是字典 只需要修改safe参数为false即可
3.上传文件
form表单上传文件需要注意的事项
1.enctype需要由默认的urlencoded变成formdata
2.method需要由默认的get变成post
(目前还需要考虑的是 提交post请求需要将配置文件中的csrf中间件注释)
如果form表单上传文件 后端需要在request.FILES获取文件数据 而不再是POST里面
request的方法
request.method
request.GET
request.POST
request.FILES
request.path # 只回去url后缀 不获取?后面的参数
request.get_full_path() # 后缀和参数全部获取