一、time模块(时间模块):
表示时间的三种方法:
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2)格式化的时间字符串(Format String): ‘1995-10-04’


%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
(3)元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等
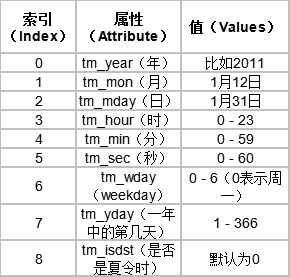
1 import time 2 3 4 print(time.asctime()) # 返回时间的格式:Sun May 20 21:31:15 2018 5 print(time.time()) # 返回时间戳:1526823135.9531205 6 print(time.gmtime()) # 同time.localtime()效果一样;返回本地时间的struct time对象格式:time.struct_time(tm_year=2018, tm_mon=5, tm_mday=20, tm_hour=13, tm_min=33, tm_sec=33, tm_wday=6, tm_yday=140, tm_isdst=0) 7 print(time.localtime()) 8 print(time.strftime("%Y-%m-%d")) #返回自定义格式的当前时间 :2018-05-20 9 print(time.strptime("2018-05-20","%Y-%m-%d")) # 将指定的时间转为struct time对象格式:time.struct_time(tm_year=2018, tm_mon=5, tm_mday=20, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=140, tm_isdst=-1)
1 import datetime 2 3 print(datetime.datetime.now()) # 返回当前时间:2018-05-20 21:42:57.486770 4 print(datetime.date.fromtimestamp(time.time())) #将时间戳转换为时间格式:2018-05-20 5 print(datetime.datetime.now() + datetime.timedelta(3)) # 返回时间在当前日期上 +3 天 6 print(datetime.datetime.now() + datetime.timedelta(-3)) # 返回时间在当前日期上 -3 天 7 print(datetime.datetime.now() + datetime.timedelta(hours= 3)) # 返回时间在当前时间上 +3 小时 8 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) # 返回时间在当前时间上 +30 分钟
二、random模块(随机数模块):
1 import random 2 3 print(random.random()) #返回0到1之间的一个小数:0.9228097480430517 4 print(random.uniform(1,3)) # 返回指定区域的任意一个浮点数 5 print(random.randint(1,5)) #返回1到5之间的整数 6 print(random.randrange(10)) #返回一个整数 7 print(random.choice("hello")) #返回字符串中任意一个元素 8 print(random.sample("hello",3)) # 以列表的形式返回指定个数的任意元素 9 10 # 生成随机数 11 12 RandomNum="" 13 for i in range(5): 14 15 AddNum=random.choice([random.randint(1.,10),chr(random.randint(65,90))]) 16 RandomNum+=str(AddNum) 17 18 print(RandomNum)
三、OS模块(python调用系统动作的接口)
1 import os 2 3 print(os.getcwd()) #获取当前工作目录 4 os.chdir('D:\Py_dir') # 切换目录 5 print(os.curdir) #返回当前目录 6 print(os.pardir) #返回父级目录 7 os.makedirs('aaa\bbbccc') #递归创建目录 8 os.removedirs('aaa\bbbccc') # 递归删除空目录,若非空,则停止删除 9 os.mkdir('aaa') # 创建单目录 10 os.rmdir('aaa') #删除单个非空目录 11 print(os.listdir()) # 查看目录内容 12 os.remove() # 删除一个文件 13 os.rename("oldname","newname") # 重命名文件与目录 14 os.stat('aaa\1.txt') # 获取文件的信息 15 print(os.sep) # 输出当前系统的分隔符 win下是‘’,linux下是‘/’ 16 os.linesep # 输出当前系统的行终止符 17 os.pathsep #输出当前系统的路径分隔符 18 os.system() # 执行系统命令 19 os.name() # 返回系统类型 20 os.environ # 返回环境变量 21 os.path.abspath() # 返回绝对路径 22 os.path.split('/aaa/bbb/1.txt') # 把路径跟文件名分开 23 os.path.dirname('/aaa/bbb/1.txt') # 返回文件的所在的路径 24 os.path.basename('/aaa/bbb/1.txt') # 返回文件名 25 os.path.exists('/aaa/bbb/1.txt') #判断目录是否存在 26 os.path.isabs('/aaa/bbb/') # 判断是不是绝对路径 27 os.path.isdir('/aaa/bbb/') # 判断目录是否存在 28 os.path.join(['aaa','bbb']) # 合并目录
四、sys模块(对python解释器的操作)
1 import sys 2 3 print(sys.argv) # 以列表的形式返回文件的绝对路径和所传的参数 4 print(sys.argv[0]) # 返回当前文件的绝对路径 5 print(sys.argv[1]) # 返回传入当前文件的第一个参数 6 sys.exit() # 退出程序 7 sys.path # 返回模块路径的环境变量 8 print(sys.platform) # 返回操作系统的名称
五、logging(日志模块)
logging基本使用:
1 import logging 2 3 logging.debug("this is debug") 4 logging.info("this is info") 5 logging.warning("this is warning") 6 logging.error("this is error") 7 logging.critical("this is critical") 8 9 >>> 10 WARNING:root:this is warning 11 ERROR:root:this is error 12 CRITICAL:root:this is critical
logging模块中的日志级别从小到大分为:
debug(调试)、info(信息)、warning(警告)、error(错误)以及critical(严重)
logging模块默认输出warning级别的日志,也可以对日志级别和输出格式进行个性化设置:
import logging logging.basicConfig( level=logging.DEBUG, # 设置日志输出的界别 format='%(asctime)s - %(filename)s - %(levelname)s - %(message)s', # 输出日志的格式 filename="test.log", # 将日志输出到文件中,如果不加这参数默认是输出到屏幕上 filemode="a" # 将日志写入文件的方式,默认为“a”追加,还可以改成“w”写入 ) logging.debug("this is debug") logging.info("this is info") logging.warning("this is warning") logging.error("this is error") logging.critical("this is critical")
%(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s 用户输出的消息
logging高级用法:
将日志同时输出到屏幕与文件
1 logger = logging.getLogger("Adair") # 创建一个logger对象,默认用户为root 2 logger.setLevel(logging.DEBUG) # 设置输出日志的级别 3 4 fileoutput = logging.FileHandler("logs.log") # 创建一个用于文件输入的处理器 5 screenoutput = logging.StreamHandler() #创建一个用于屏幕输出的处理器 6 7 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 指定日志格式 8 9 fileoutput.setFormatter(formatter) # 文件输出获取日志格式 10 screenoutput.setFormatter(formatter) # 屏幕输出获取日志格式 11 12 logger.addHandler(fileoutput) # 将文件输入处理器添加到logger对象中 13 logger.addHandler(screenoutput) # 将屏幕输出处理器添加到logger对象中 14 15 logger.debug("this is debug") 16 logger.info("this is info") 17 logger.warning("this is warning") 18 logger.error("this is error") 19 logger.critical("this is critical")
1 http://python.jobbole.com/87300/ 2 http://www.cnblogs.com/yuanchenqi/articles/5732581.html
六、configparser(解析配置文件模块)
先生成一个配置文件:
1 import configparser 2 3 config = configparser.ConfigParser() # 创建一个config对象 4 5 config["DEFAULT"] = { 6 'ServerType':'weblogic', 7 'ServerPort':'7001' 8 } 9 config["BACKUP"] = { 10 "BackupType":"Full", 11 "BackupTime":"23:00", 12 "BackupUser":"weblogic" 13 } 14 config["DEPLOY"] = { 15 "DeployType":"incremental", 16 "DeployUser":"webloic" 17 } 18 config["DEFAULT"]['ServerUrl'] = "http://127.0.0.1:7922/console" 19 20 with open('config.ini','w') as configfile: 21 config.write(configfile)
配置文件的格式跟windows下的ini配置文件相似,可以包含一个或多个节(section), 每个节可以有多个参数(键=值):
1 [DEFAULT] 2 servertype = weblogic 3 serverport = 7001 4 serverurl = http://127.0.0.1:7922/console 5 6 [BACKUP] 7 backuptype = Full 8 backuptime = 23:00 9 backupuser = weblogic 10 11 [DEPLOY] 12 deploytype = incremental 13 deployuser = webloic
配置文件的增删改查:
1 print(config.sections()) # 获取所有的节,不包括DEFAULT,DEFAULT是特殊的默认节 2 3 print(config.items("BACKUP")) # 获取指定节的值(key:values),输出时DEFAULT默认节也会一同输出 4 print(config.options("BACKUP")) # 获取指定节的值(key),输出时DEFAULT默认节也会一同输出 5 6 for key in config['DEPLOY']: # 获取指定节的值(key),输出时DEFAULT默认节也会一同输出 7 print(key) 8 9 # 获取指定key的value值: 10 print(config['DEPLOY']['deploytype']) 11 print(config.get('DEPLOY','deploytype')) 12 print(config.getint('DEFAULT','serverport')) 13 14 # 添加 15 config.add_section('compile') 16 config.set('compile','CompileType','ant') 17 config.write(open('config.ini','w')) 18 19 # 删除 20 config.remove_option('DEPLOY','deploytype') 21 config.remove_section('BACKUP') 22 config.clear() # 清除DEFAULT以外的所有内容 23 config.write(open('config.ini','w'))
DEFAULT:
[DEFAULT] 一般包含 ini 格式配置文件的默认项,所以 configparser 部分方法会自动跳过这个 section 。
前面已经提到 sections() 是获取不到的,还有删除方法对 [DEFAULT] 也无效
但指定删除和修改 [DEFAULT] 里的 keys & values 是可以的:
1 config.remove_option('DEFAULT','servertype') # 删除DEFAULT中的key 2 config.set('DEFAULT','serverport','8080') # 修改DEFAULT中指定key的值 3 config.write(open('config.ini','w'))
注:文件中的内容一旦保存在磁盘中,是不会被修改的。所以每次操作动作执行完都要加上config.write(open('config.ini','w'))这一句将之前的文件内容进行覆盖。
七、re模块(正则表达式)
简介:
正则表达式是一种小型的、用来匹配字符串的高度专业化的编程语言,Python将正则表达式嵌入到了re模块中,方便py粉儿使用。
1 s="hello world" 2 3 print(s.find('or')) 4 >>>7 5 print(s.replace('ll','aa')) 6 >>>heaao world 7 print(s.split(' ')) 8 >>>['hello', 'world']
字符串自身的方法是完全匹配,而有些场景字符串自身的方法并不能完全满足,比如在一堆人员中过滤出电话号,这时候就需要使用模糊匹配,而正则表达式就是为了提供模糊匹配的一种编程语言。
元字符:有特殊意义的字符
. ^ * + ? { } [ ] | ( )
1 import re 2 s = "My name is Ye xiaohei" 3 print(re.findall('xiaohei',s)) # findall 以列表的形式输出所有匹配项 4 >>>['xiaohei'] 5 print(re.findall('h.i',s)) # . 只能匹配一个字符,换行符( )除外 6 >>>['hei'] 7 print(re.findall('^hei',s)) # ^ 只从开头匹配 8 >>>[] 9 print(re.findall('hei$',s)) # $ 只在结尾匹配 10 >>>['hei'] 11 print(re.findall('xiao*','xiaooooooooo')) # * 匹配前一个字符的0到多次 12 >>>['xiaooooooooo'] 13 print(re.findall('hei+','xiaoooheoo')) # + 匹配前一个字符的1到多次 14 >>>[] 15 print(re.findall('xia?o','xiaoooxiooo')) # ? 匹配0到1次 16 >>>['xiao', 'xio'] 17 print(re.findall('xi{5}ao','xiiiiiaoooo')) # {m} 匹配前一个字符的N次 18 >>>['xiiiiiao'] 19 print(re.findall('xi{1,3}ao','xiaoooo')) # {m,n} 匹配前一个字符的m到n次 20 >>>['xiao'] 21 print(re.findall('[i,o]',s)) # [] 匹配元字符集中的任意字符 22 >>>['i', 'i', 'o', 'i'] 23 print(re.findall('d{5}','asd230498327843vfeq')) # 转义字符后边跟普通字符实现特殊功能 24 >>>['23049', '83278'] 25 print(re.findall('*','asd2304983*27843vfeq')) # 转义字符后边跟元字符取消特殊功能 26 >>>['*'] 27 print(re.search('i',s)) # search 方法以对象的方式输出匹配的第一项 28 >>><_sre.SRE_Match object; span=(8, 9), match='i'>
1 print(re.findall('a|1','asddsa1321')) # | “或”的意思,截取管道符左边的或者右边的字符 2 >>>['a', 'a', '1', '1'] 3 print(re.findall('(as)+','asasassaasdfasfas')) # () 分组 括号内的字符为一组,作为整体去匹配 4 >>>['as', 'as', 'as', 'as'] 5 print(re.findall('(as|sa)','asaaadsasaadsa')) 6 >>>['as', 'sa', 'sa', 'sa'] 7 ret=re.search('(?P<id>w{3})/(?P<path>d*)','asd/5412543') # (?P<组名>匹配规则) 固定格式 为每个标注出名字 方便调用 8 print(ret.group()) 9 >>>asd/5412543 10 print(ret.group('id')) 11 >>>asd 12 print(ret.group('path')) 13 >>>5412543
纠结的反斜杠:
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。同样,匹配一个数字的"\d"可以写成r"d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1 print(re.findall(r'\','asddsa')) 2 >>>['\'] 3 print(re.findall('\\','asddsa')) 4 >>>['\']
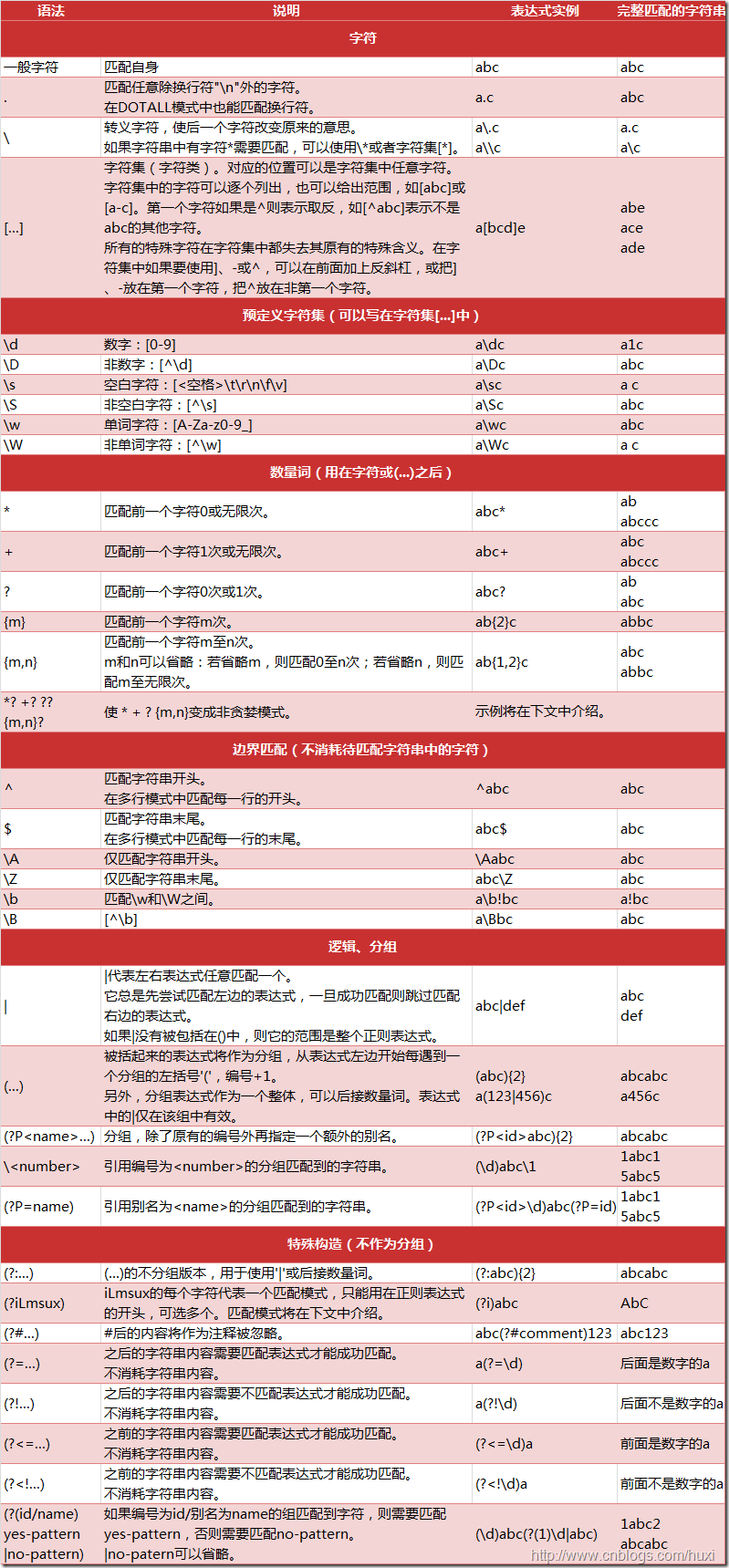
元字符明细表:
转至:(https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html)
正则表达式的方法:
findall():以列表的形式返回匹配到的所有内容
search():以object的形式只返回匹配到的第一个内容,可以使用group()方法查看结果
match():只在字符串的开始匹配,以object的形式返回第一个内容,可以使用group()方法查看结果
split():跟字符串的split()的方法一样都是用来切分,格式:re.split('可用正则的切割符','被切割的内容')
sub():替换内容,格式:re.sub('正则获取需要替换内容','替换后的内容','替换内容')
compile():将正则表达式编译成正则表达式对象
正则计算器:
水平一般,能力有限,欢迎来怼!
1 # Author : Adair 2 # -*- coding:utf-8 -*- 3 4 import re,sys 5 6 UserInput=input("请输入你要计算的数字:") 7 # UserInput="1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )" 8 # UserInput="123+2333*10/8+2356+(123*58)" 9 10 def Format(original): # 格式化用户输入 11 ReplaceSpace=original.replace(' ','') #清除空格 12 ParenGroup=re.search('(?P<BeforeBrackets>()(?P<Digital>-?d*.?d*)(?P<AfterBrackets>))', ReplaceSpace) 13 if ParenGroup: 14 ParenProce=re.sub('(-?d*.?d*)',ParenGroup.group('Digital'),ReplaceSpace,1) 15 SameSymbolSub_AddSub=re.sub('--|++','+',ParenProce) # 相同符号替换 (加减) 16 else: 17 SameSymbolSub_AddSub=re.sub('--|++','+',ReplaceSpace) # 相同符号替换 (加减) 18 SameSymbolSub_take=re.sub('**','*',SameSymbolSub_AddSub) # 相同符号替换 (乘) 19 SameSymbolSub_division=re.sub('//','/',SameSymbolSub_take) # 相同符号替换 (除) 20 AdjDiffSymbol_SubAdd=re.sub('-+|+-','-',SameSymbolSub_division) # 相邻不同符号替换 (加减) 21 22 return AdjDiffSymbol_SubAdd 23 24 def ComPlianceCheck(CheckItem): # 合法性检查 25 flag=True 26 if re.findall('[a-zA-Z]',CheckItem): # 不支持字母的运算 27 print("Input error: no alphabetic operation is supported! (%s)"%CheckItem) 28 flag=False 29 if re.findall('*/|/*',CheckItem): # 不合法的计算符 30 print("Input error: operator input error! (%s)"%CheckItem) 31 flag=False 32 return flag 33 34 def Calculate(ori,cal): # 计算 35 if re.search('*|/',cal): # 运算符优先级判断 36 PacketProcessing = re.search('(?P<num1>-?d+.?d*)(?P<operator>[*/])(?P<num2>-?d+.?d*)', cal) 37 elif re.search('+|-',cal): 38 PacketProcessing = re.search('(?P<num1>-?d+.?d*)(?P<operator>[+-])(?P<num2>-?d+.?d*)', cal) 39 # 字符类型处理 str >>> int 40 Num1 = float(PacketProcessing.group('num1')) 41 Operator = PacketProcessing.group('operator') 42 Num2 = float(PacketProcessing.group('num2')) 43 if Operator == '+': 44 Results = Num1 + Num2 45 origi = ori.replace(PacketProcessing.group(), str(Results)) 46 return origi 47 elif Operator == '-': 48 Results = Num1 - Num2 49 origi = ori.replace(PacketProcessing.group(), str(Results)) 50 return origi 51 elif Operator == '*': 52 Results = Num1 * Num2 53 origi = ori.replace(PacketProcessing.group(), str(Results)) 54 return origi 55 elif Operator == '/': 56 Results = Num1 / Num2 57 origi = ori.replace(PacketProcessing.group(), str(Results)) 58 return origi 59 60 def PriorityJud(PriJud): # 格式优先级判断 61 ParenthesesRun = re.findall('([^()]*-?d+.?d*[+-*/]-?d+.?d*)', PriJud) 62 if ParenthesesRun: 63 Parentheses=ParenthesesRun[0] 64 cal=Calculate(PriJud,Parentheses) 65 else: 66 cal=Calculate(PriJud,PriJud) 67 return cal 68 69 # 流程控制 70 if ComPlianceCheck(UserInput): 71 Results = UserInput 72 formats = Format(Results) 73 while re.findall('-?d+.?d*[*/+-]+.?d+.?d*', formats): 74 Results = PriorityJud(formats) 75 formats = Format(Results) 76 print(Results) 77 else: 78 sys.exit(0)