2017-12-6 沈阳
论文<基于神经网络的数据挖掘分类算法的比较和分析>
为什么有数据挖掘?
(1) 数据对冗杂
(2) 数据不安全增加
(3) 数据时代的发展推动
应用:
(1) 金融投资方面的证券管理系统(LBS Capital Managemnent)
(2) 电信行业的预测预测是否存在用户数据的异常
(3) 商业 通过CRM的数据挖掘时的相关公司可以预测潜在的客户
(4) 天文学方面的就是可以使用SKICAT(Sky ImageCataloging and Analysis Tool)成功地发现了16个遥远的新星群
数据挖掘的任务:
从数据即中发现和找到潜在的,有用的模式.该模式可以被分为两类:预测性(Predictive)模式,依据模式的数据项的值对某种未知的结果进行预测或确定:描述型(discriptive)模式,也就是对数据集中所存在的事实做出规范性描述,刻画出数据的一般性质。
分类与聚类
分类:找出数据库中的数据映射到给定类别中去的分类函数或是分类的模型中
聚类:根据数据的不同的特征进行相应的划分,从而归类到不同的数据类中去。另外将实现的同一类别的数据的距离尽可能的进行缩小,并让不同类的个体之间的距离达到最大化
相关性的分析:就是找到数据之间或特征之间的相互依赖性,例如有名的啤酒与尿布
常用的数挖掘的算法分类
(1) 机器学习型算法:属于人工智能的范畴,就是通过大量的样本集的训练和学习找出所需要的参数或模式(我觉得这里的模式也就是指相应的符合的函数的类型)
(2) 统计分析型算法:此类的算法主要有:相关性的分析,聚类分析,概率分析,判别分析。
数据挖掘的常用算法:
统计分析;决策树;贝叶斯网络;粗糙集;人工神经,以及遗传算法
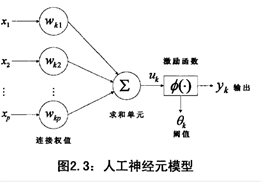
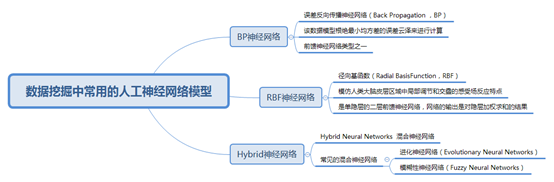
人工神经网络
它有三层的结构来进行描述的:分别是:输入层(我们的接收或感知外部信息的接口,比如我们的眼耳口鼻),隐层(就是一系列的身体的各中神经细胞的进行运作)以及输出层(人类的各个肢体的行动器管)
输入层中有多个神经元,主要的作用就是接收信息,在接收信息之后将其传递给下一层;隐含层负责信息的交换与管理是人工神经网络的处理内部信息的层,它可以根据具体的信息的不同而设计曾多层或者是单层;最后经过一系列的处理隐层将信息传递给输出层.


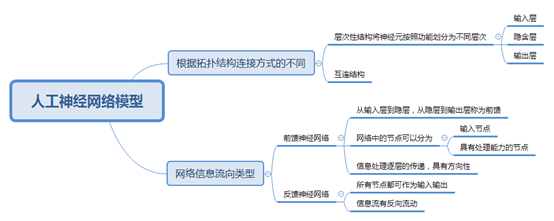
人工神经网络按照学习方式的分类
分别使用的图形的方法是:
数据挖掘中常用的人工神经网络的算法:
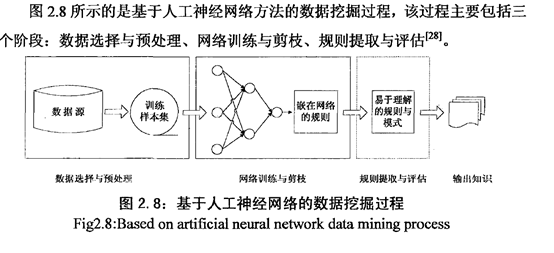
基于人工神经网络的数据挖掘
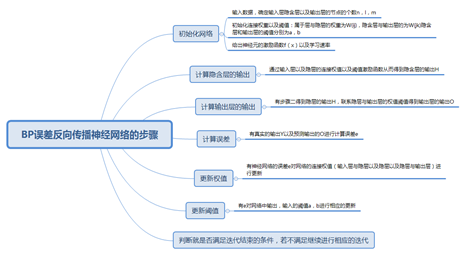
步骤:
人工神经网络的一些特性:

第三章:ELM的理论基础
BP神经网络
步骤:
(1) 输入层的节点n,隐层节点l,输出层节点m
输入层与隐层的权值为Wij,隐层与输出层的权值为Wjk
隐层与输出层的权值为a,b
激励函数f(),学习速率ɧ
(2) 隐层输出H=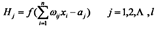
(3) 输出层输出O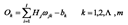
(4) 计算误差e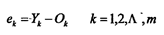
(5) 根更新权值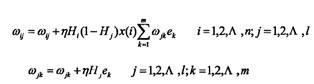
(6) 更新阈值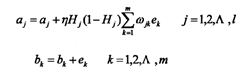
(7) 判断
SVM支持向量机
周志华:《机器学习》121页
问题:给定训练集怎么去寻找可以良好的方法将训练样本划分来?
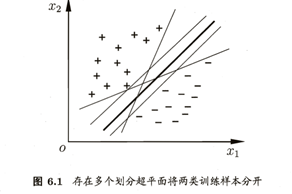
而从直觉上将“红色颜色最深”的为鲁棒的,也就是最稳定的,对未见示例的泛化能力最强。而在样本空间中,划分超平面可以通过如下的线性方程来描述:
WTX+b=0;其中W=(W1,W2, Wd)为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离。在样本空间之中任意X到超平面(W,b)的距离可以写为: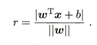
构造支持向量机学习算法的关键是:在“支持向量”x(i)与输入空间抽取的向量x之间的內积核函数
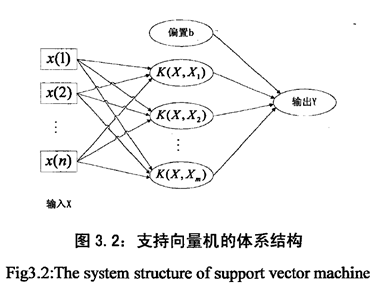
图中K为核函数,核函数的种类主要有:
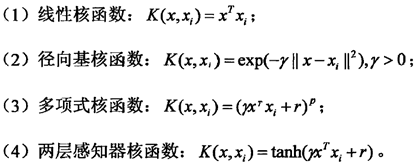
SVM网络算法描述
(1) 二分类支持向量机
(2) 我的理解:简单的将一件事物分为属于与不属于,然后通过标注是-1,1来区分属于与不属于。
C-SVC模型是比较常见的二分类支持向量机模型,其具体的形式如下:


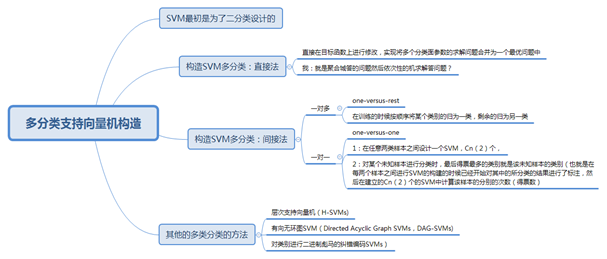
SVM构造多分类支持向量机
ELM(Extreme Learning Machine)极限学习机
单隐层前馈神经网路(Single-hidden Layer Feedforward Neural Network SLFN)
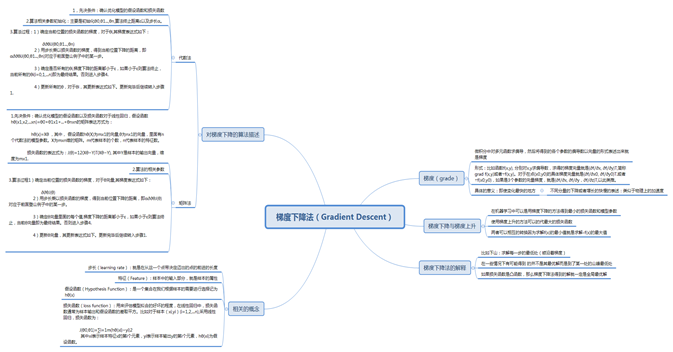
传统的神经网络多使用梯度下降法,该方法的具体的不足:
(1训练速度慢,耗时过长
(2容易陷入极小点
(3学习率ɧ的选择敏感
对梯度学习的来源于:梯度下降(Gradient Descent)小结 - 刘建平Pinard - 博客园
https://www.cnblogs.com/pinard/p/5970503.html#undefined
我的想法:
无论是是使用代数法还是矩阵的方法,其在第三部的算法过程中的(3)周都有使得x的系数的低度下降距离小于某一个数值。这样似乎是在设限制,也就是告诉说似乎快接近最优解的选项了,才使得变化或者下降的矩离越来越小。
需要了解自己使用矩阵的求导;矩阵的求导公式的总结:
矩阵求导计算法则 例题_唐唐唐唐_新浪博客
http://blog.sina.com.cn/s/blog_4a033b090100pwjq.html
Extreme Learning Machine ELM
(1) 针对单隐层前馈神经网络(SLFN)
(2) 特点: 随机的产生输入层与隐含层的连接权值,以及隐含层神经元的阈值,并且在训练的过程中需要加以调整(也就是说网络仅仅只需要对隐层神经元的个数加以控制就可以了,就能获得唯一的最优解)
ELM的网络结构:
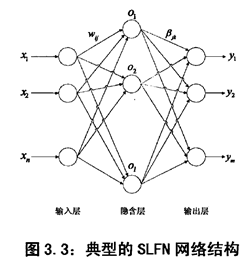
此处分别设置输入与隐含层的连接权值W和隐含层与输入层的连接beta,用矩阵的表示的方法也就是这个样子的:

其中X具有Q个样本训练集。设隐层神经元的激活函数为g(x),则网络得输出T也就表示为:
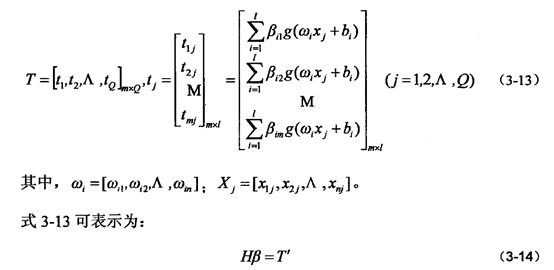
H为人工神经网络中的隐含层的输出矩阵,T’为T的转置,H的具体的形式也就是:
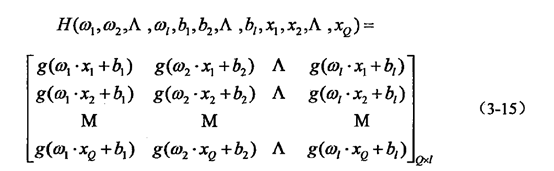
研究中的两个定理如下:

定理一和定理二中的激活函数都是在无限可微的情况之下的:
有定理一知道Q是关键,也就是在有Q个样本和Q个隐层神经元的情况之下随机的设置权值和阈值使得其数据的误差为0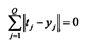
但是现在实际的情况下,Q的数值比较大,所以就会取K作为比Q小的值。满足的误差: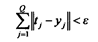
因此当激活函数无限可微的时候,只需要去随机产生w和b的值然后在训练中保持值不发生改变,输出层和隐层的连接权值beta可以通过最小二乘的方法进行求解:

我:在学习的过程中,通过对训练数据的描述,进而得到一个训练的模型函数。
我们的目的是通过训练的模型的函数应用在测试的数据之上从而得到比较好的数据预测。
而我们往往会忽视的一点就是为什么不对一个训练的数据进行再检测那?我们可以通过使用训练得到的模型对训数据的在检测和引入,从而去看是不是存在过拟合:
过拟合的标准就是太过于100%了,我们对数据的训练然后得到的模型是一种适合大众的,而不是适合每一个的,除非是线性的模型在每一个点上的那种我们可以100%的吻合。因为我们要符合现实3,现实就是不会太个例化。
ELM的步骤
(1) 在应用软件中添加ELM的文件,启动
(2) 随机的生成w和b
(3) 在函数的库类型中选择合适的函数的类型,也就是选择激活函数。而激活函数的无通过公式的出来隐层的输出矩阵H
(4) 利用隐层的输出矩阵H和训练样本的输出(标签T),从而得到隐层与输出层的权重beta