索引基础知识
很多人都喜欢将索引比作字典的目录。我们想要查某个字时,先在目录里查找这个字的页码(索引扫描),然后直接翻到那一页,就找到了那个字。没有目录(字典)时,我们只能一页一页地翻(全表扫描)。这样的话性能很慢。
索引可以包含一列或队列的值,即单值索引和复合索引。创建复合索引和两个1列的索引效果是不一样的
1、索引类型
索引实在存储引擎层实现的,而不是服务器层。不同的存储引擎可能支持不同的索引类型。
1.1.B-Tree索引
InoDB引擎默认的索引数据结构。
1.2.Hash索引
Mysql中Memory引擎支持。
1.3.全文索引
类似搜索引擎查找关键词干的事。
InnoDB可以有“伪哈希索引”,在B-Tree索引的基础上进行哈希查找,取代原先的按键值查找。
比如URL很长,用作索引列会很慢,可以用CRC_URL(url)后的列值(整形)作为索引,能提升性能。这里的CRC_URL()就相当于一个哈希函数。
高性能的索引策略
1、 独立的列
所谓独立的列,指的是不要将索引列作为表达式的一部分或函数的参数。如下是两个错误的例子:
- Select actorname from actor where actirid + 1 = 5;
- Select xxx from xxx where TODAYS(CURRENT_DATE)- TODAYS(date_col)<=7;
上面的actorid和datecol上建立的索引,将无法被mysql自动识别并使用。因此我们尽量不要这么做。
2、前缀索引和索引选择性
有时候很长的列直接作为索引的话,性能会比较慢,这时我们需要使用前缀索引,例如上面提到的CRC_URL。但这还不够,需要考虑选择性。所谓选择性,指的是区分度。即使用索引查询时,能够过滤掉的行数。区分度越高,过滤掉的记录数越多,这样的索引效果才好。唯一索引拥有最好的区分度,因为没有重复的列值。而像性别这种列,不适合作为索引列,因为就2种值。
3、复合索引
注意,复合索引并不是在多个列上单独的建单列索引,因为这往往并不能很好的提升性能。
5.x版本的MySQL会采用索引合并策略。即下面的sql语句上,actori和filmname列上各有一个单列索引。
Select xxx from actor where actorid = 1 or filmname = ‘TiTanNic’
Mysql会将这两个索引合并,生产并使用这个新的索引idx_actorid_filmname。但这往往意味着我们设计的索引并不优,可用考虑合并成一个复合索引key(actorid,filename)
4、建立合适顺序的复合索引
将区分度更高的列放在前面,这样通常是比较好的原则,因为这样能过滤掉更多的列。换句话说,就是计算候选列的值分布,值分布越多,区分度越高,应该把它放在前面。可以用如下的sql计算各个列的区分度。
- Select count(distinct col1)/count(*) as discrimination1,
- Count(distinct col2)/count(*) as discrimination2,
- Count(*) from A;
5、防范某些特殊值导致的索引列性能慢
这里的特殊值,比如应用的管理员,游客用户,这些列值往往拥有的记录数很大,从而区分度很小,使用索引查询时几乎不能过滤掉行数。这种案例的解决办法,通常可以在应用程序端做特殊处理,区分出这种特殊值,禁止这种特殊值直接参与查询。
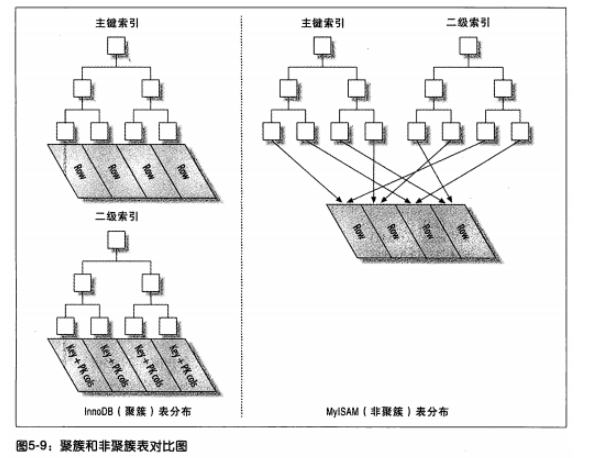
6、聚(簇)集索引
聚集索引实际上并不是一种索引类型,而是一种数据存储方式。聚集索引指的是数据行和索引键值紧密地存放在一起,索引键值的顺序大小和数据行的顺序大小一致。一个表只能有1个聚集索引,默认是主键列作为聚集索引。如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果也没有这样的索引,InnoDB会隐式地创建一个主键来作为聚集索引。
聚集索引的优点:
1、 可以将相关数据保存在一起。比如电子邮箱的表,可以根据用户ID来聚集数据,这样只需要从磁盘读取少许的数据页就能获取某个用户的所有邮件。如果是非聚集索引,则每封邮件都可能导致一次磁盘IO。
2、 访问速度更快。索引和数据保存在同一个B-Tree节点中,因此从聚集索引中获取数据比非聚集索引更快。
聚集索引示例图
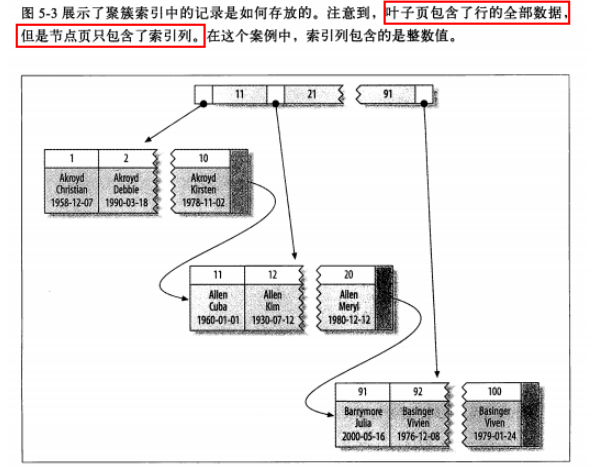
聚集和非聚集索引的区别:
7、覆盖索引
通常索引的工作方式时,先在索引上查找到目标数据的指针,再回表去查询指针指向的数据行。如果我们要查询的列恰好在索引列中,即被索引列覆盖到了,那么就不需要回表(主键索引的二次查询)操作了,直接返回索引中的数据即可,这样能够大大提升性能。
8、延迟关联
翻页很大时,即offset,limit中offset值很大时,可以采用延迟关联策略。先根据过滤条件查询出主键值(通常被覆盖索引所覆盖),再和原表关联,查出需要的列
9、IN('MALE', 'FEMALE')小技巧
当有(SEX, AGE)这样的复合索引时,但用户并未指定SEX条件时,可以强制加上where SEX IN ('MALE', 'FEMALE') and AGE < 25。因为IN()在where中相当于多个等值查询,它并不像范围查询一样,不会导致索引中断失效。但要注意,这个技巧不能滥用,IN()里面的可选值不能太多。
10、选择性和频率需同时考虑
需要看哪些列的选择性更高,哪些列在where条件后出现的最频繁,这2点都需要考虑。
例如,即使某些列的选择性很低(如SEX),但它几乎出现在每个查询的where条件中,那也应该为它设计索引。
11、范围查询的列通常放在索引最后一列
如age列。这样可以尽可能使用更多的索引列。
三个原则
在选择索引和编写利用这些索引的查询时,有如下三个原则始终需要记住:
1、单行访问是很慢的。特别是在机械硬盘存储中(SSD也是)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引用以提升效率。
2、按顺序访问范围数据是很快的,这有两个原因。第一,顺序IO不需要多次磁盘寻道,所以比随机IO要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUP BY查询也无须再做排序和将行按组进行聚合计算了。
3、索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就不需要再回表查找行。这避免了大量的单行访问。
总的来说,编写查询语句时应该尽可能选择合适的索引以避免单行查找、尽可能地使用数据原生顺序从而避免额外的排序操作,并尽可能使用索引覆盖查询。