数据的特征工程
1.特征工程是什么
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对位置数据的预测准确性。
2.特征工程的意义
直接影响预测结果
3.scikit-learn库介绍
python语言的机器学习工具
scikit-learn包括许多知名的机器学习算法的实现
scikit-learn文档完善,容易上手,丰富的API
4.数据的特征抽取
(1)特征抽取实例演示
#导入包
from sklearn.feature_extraction.text import CountVectorizer
#实例化CountVectorizer
vector=CountVectorizer()
#调用fit_transform输入并转换数据
res=vector.fit_transform(["life is short,i like python","life is too long,i dislike python"])
#打印结果
print(vector.get_feature_names())
print(res.toarray())

通过演示得出结论:
特征抽取对文本等数据进行特征值化,即转化为数字值。
特征值化是为了计算机更好的去理解数据
(2)sklearn特征抽取API
sklearn.feature_extraction
(3)字典特征抽取
作用:对字典数据进行特征值化
sklearn.feature_extraction.DictVectorizer
DictVectorizer语法
DictVectorizer(sparse=True,…)
DictVectorizer.fit_transform(X)
X:字典或者包含字典的迭代器
返回值:返回sparse矩阵
DictVectorizer.inver_transform(X)
X:array数据或者sparse矩阵
返回值:转换之前数据格式
DictVectorizer.get_feature_names()
返回类别名称
DictVectorizer.transform(X)
按照原先的标准转换
流程
1.实例化DictVectorizer
2.调用fit_transform方法输入数据并转换,注意返回格式
演示
from sklearn.feature_extraction import DictVectorizer
def dictvec():
'''
字典数据抽取
:return: none
'''
#实例化
dict=DictVectorizer()
#调用fit_transform
data=dict.fit_transform([
{'city':'北京','temperature':100},
{'city':'上海','temperature':60},
{'city':'深圳','temperature':30}
])
print(data)
return None
if __name__=='__main__':
dictvec()

返回值:sparse矩阵格式
原因:节约内存,方便读取处理
其实也可以转换为普通二维矩阵:
dict=DictVectorizer(sparse=False)

两次输出没有什么差别,只不过sparse矩阵没有打印0值。
打印类别:
print(dict.get_feature_names())
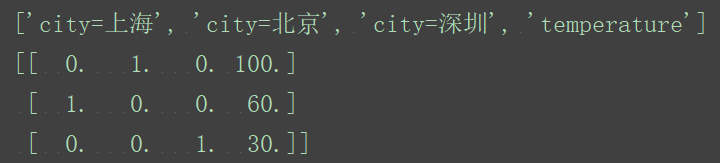
字典数据抽取:把字典中一些类别数据,分别进行转换成特征。
数组形式,有类别特征,先要转换字典数据。
(4)文本特征抽取
作用:对文本数据进行特征值化
CountVectorizer语法
CountVectorizer()
返回词频矩阵
CountVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
CountVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
CountVectorizer.get_feature_name()
返回值:单词列表
流程
1.实例化CountVectorizer
2.调用fit_transform方法输入数据并转换,
注意返回格式,利用toarray()进行矩阵转换array数组
演示
def countvec():
'''
对文本进行特征值化
:return: none
'''
cv=CountVectorizer()
data=cv.fit_transform(["life is short,i like python","life is too long,i dislike python"])
print(data)
return None
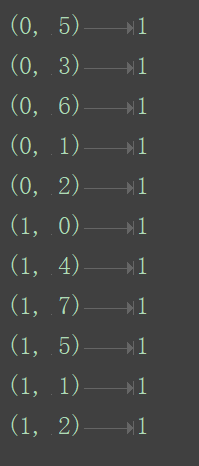
这仍然是sparse矩阵,要转换成普通二维矩阵:
print(data.toarray())
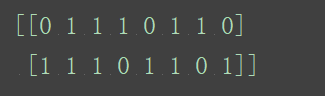
打印类别:
print(cv.get_feature_names())

1.词的列表:统计所有文章当中的词,重复的只看做一次。
2.对每篇文章,在词的列表里面统计每个词出现的次数。(单个字母不统计)
对于中文情况:
data=cv.fit_transform(["人生苦短,我用python","人生漫长,不用python"])

显然,中文情况不能很好的抽取特征。
注意,切分的依据不是逗号“,”
data=cv.fit_transform(["人生 苦短,我用 python","人生 漫长,不用 python"])

所以,需要对中文进行分词才能详细的进行特征值化。
分词需要的包:
import jieba
然后进行分词:
def cutword():
con1=jieba.cut("这是一个久远的故事。当你笑着 醒了的时候 别提会有多快乐!早晨的微笑 是有魔力的,带来一天的好心情。")
con2=jieba.cut("六一的任性魔术是将手中的“魔法棒”敲醒遇到的第一个熟悉的可爱的人。谁会继续 小小傲娇可是要飞上天太阳高高的照。")
con3=jieba.cut("敲醒了那个人竟不知太阳在哪,傻笑着,如初美好。傲娇猫")
#转换成列表
content1=list(con1)
content2=list(con2)
content3=list(con3)
#把列表转换成字符串
c1=" ".join(content1)
c2=" ".join(content2)
c3=" ".join(content3)
return c1,c2,c3
def countvec():
'''
对文本进行特征值化
:return: none
'''
c1,c2,c3=cutword()
print(c1,c2,c3)
cv=CountVectorizer()
data=cv.fit_transform([c1,c2,c3])
print(cv.get_feature_names())
print(data.toarray())
return None
结果如下:
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\dai'er\AppData\Local\Temp\jieba.cache
Loading model cost 0.968 seconds.
Prefix dict has been built succesfully.
这是 一个 久远 的 故事 。 当 你 笑 着 醒 了 的 时候 别提 会 有 多 快乐 ! 早晨 的 微笑 是 有 魔力 的 , 带来 一天 的 好 心情 。 六一 的 任性 魔术 是 将 手中 的 “ 魔法 棒 ” 敲醒 遇到 的 第一个 熟悉 的 可爱 的 人 。 谁 会 继续 小小 傲娇 可是 要 飞 上天 太阳 高高的 照 。 敲醒 了 那个 人竟 不知 太阳 在 哪 , 傻笑 着 , 如初 美好 。 傲娇 猫
['一个', '一天', '上天', '不知', '久远', '人竟', '任性', '傲娇', '傻笑', '六一', '别提', '可是', '可爱', '太阳', '如初', '小小', '带来', '微笑', '心情', '快乐', '手中', '故事', '敲醒', '早晨', '时候', '熟悉', '第一个', '继续', '美好', '这是', '遇到', '那个', '高高的', '魔力', '魔术', '魔法']
[[1 1 0 0 1 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 0 1 0 1 1 0 0 0 0 1 0 0 0 1 0 0]
[0 0 1 0 0 0 1 1 0 1 0 1 1 1 0 1 0 0 0 0 1 0 1 0 0 1 1 1 0 0 1 0 1 0 1 1]
[0 0 0 1 0 1 0 1 1 0 0 0 0 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0]]
但实际上,统计单词次数的分类方式不怎么常用。(一些中性词会干扰分类)
TF-IDF
TF-IDF的主要思想:如果某个词或短语在一篇文章中出现的概率高,并且在其它文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
朴素贝叶斯
tf idf —— tf*idf——重要性程度
tf: term frequency 词的频率 出现的次数
idf: inverse document frequency 逆文档频率 log(总文档数量/该词出现的文档数量)
TfidfVectorizer语法
TfidfVectorizer(stop_words=None,…)
返回词的权重矩阵
TfidfVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回spars矩阵
TfidfVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
TfidfVectorizer.get_feature_names()
返回值:单词列表
为什么需要TfidfVectorizer?
答:分类是机器学习算法的重要依据。
5.数据的特征预处理
对数据进行处理。
特征预处理是什么?
通过特定的统计方法(数学方法)将数据转换成算法要求的数据。
数值型数据:标准缩放:1.归一化。2.标准化。3.缺失值。
类别型数据:one-hot编码
时间类型:时间的切分
1.特征预处理的方法
2.sklearn特征预处理API——sklearn.preprocessing
(1)线性归一化。
也称min-max标准化、离差标准化;是对原始数据的线性变换,使得结果值映射到[0,1]之间。
特点:通过对原始数据进行变换把数据映射到(默认为[0,1])之间。
目的:使得某一个特征对最终结果不会造成更大影响。
转换函数如下:

MinMaxScaler语法
MinMaxScalar(feature_range=(0,1)…)
每个特征缩放到给定范围(默认[0,1])
MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
归一化步骤
1、实例化MinMaxScalar
2、通过fit_transform转换
演示:
from sklearn.preprocessing import MinMaxScaler
def mm():
'''
归一化处理
:return: None
'''
mm=MinMaxScaler()
data=mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
if __name__=='__main__':
mm()

这种归一化比较适用在数值较集中的情况。这种方法有一个缺陷,异常点对最值影响太大,如果max和min不稳定的时候,很容易使得归一化的结果不稳定,影响后续使用效果。其实在实际应用中,一般用经验常量来替代max和min。
对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变。
(2)标准差归一化。
特点:通过对原始数据进行变换把数据变换到均值为0,方差为1范围内。
也叫Z-score标准化,这种方法给予原始数据的均值(mean,μ)和标准差(standard deviation,σ)进行数据的标准化。经过处理后的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
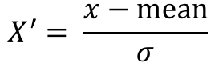
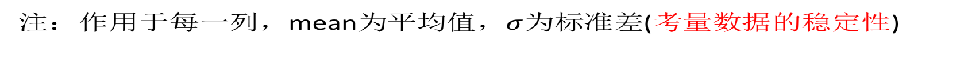

StandardScaler语法
StandardScaler(…)
处理之后每列来说所有数据都聚集在均值0附近标准差为1
StandardScaler.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
StandardScaler.mean_
原始数据中每列特征的平均值
StandardScaler.std_
原始数据每列特征的方差
标准化步骤
1、实例化StandardScaler
2、通过fit_transform转换
演示:
from sklearn.preprocessing import StandardScaler
def stand():
'''
标准化缩放
:return:
'''
std=StandardScaler()
data=std.fit_transform([[ 1., -1., 3.],[ 2., 4., 2.],[ 4., 6., -1.]])
print(data)
return None
if __name__=='__main__':
stand()
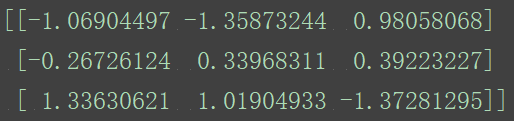
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
(3)缺失值
如何处理数据中的缺失值?

Imputer语法
Imputer(missing_values='NaN', strategy='mean', axis=0)
完成缺失值插补
Imputer.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
Imputer流程
1、初始化Imputer,指定”缺失值”,指定填补策略,指定行或列
注:缺失值也可以是别的指定要替换的值
2、调用fit_transform
演示:
from sklearn.preprocessing import Imputer
import numpy as np
def im():
'''
缺失值处理
:return:
'''
im=Imputer(missing_values='NaN',strategy='mean',axis=0)
data=im.fit_transform([[1, 2], [np.nan, 3], [7, 6]])
print(data)
return None
if __name__=='__main__':
im()

关于np.nan(np.NaN)
1、 numpy的数组中可以使用np.nan/np.NaN来代替缺失值,属于float类型。
2、如果是文件中的一些缺失值,可以替换成nan,通过np.array转化成float型的数组即可。
(4)非线性归一化,这种方法一般使用在数据分析比较大的场景,有些数值很大,有些很小,通过一些数学函数,将原始值进行映射。一般使用的函数包括log、指数、正切等,需要根据数据分布的具体情况来决定非线性函数的曲线。